 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoPHo: Classifier-guided Conditional Topology Generation with Persistent Homology
Dec 17, 2025The structure of topology underpins much of the research on performance and robustness, yet available topology data are typically scarce, necessitating the generation of synthetic graphs with desired properties for testing or release. Prior diffusion-based approaches either embed conditions into the diffusion model, requiring retraining for each attribute and hindering real-time applicability, or use classifier-based guidance post-training, which does not account for topology scale and practical constraints. In this paper, we show from a discrete perspective that gradients from a pre-trained graph-level classifier can be incorporated into the discrete reverse diffusion posterior to steer generation toward specified structural properties. Based on this insight, we propose Classifier-guided Conditional Topology Generation with Persistent Homology (CoPHo), which builds a persistent homology filtration over intermediate graphs and interprets features as guidance signals that steer generation toward the desired properties at each denoising step. Experiments on four generic/network datasets demonstrate that CoPHo outperforms existing methods at matching target metrics, and we further validate its transferability on the QM9 molecular dataset.
Mixing Importance with Diversity: Joint Optimization for KV Cache Compression in Large Vision-Language Models
Oct 23, 2025Recent large vision-language models (LVLMs) demonstrate remarkable capabilities in processing extended multi-modal sequences, yet the resulting key-value (KV) cache expansion creates a critical memory bottleneck that fundamentally limits deployment scalability. While existing KV cache compression methods focus on retaining high-importance KV pairs to minimize storage, they often overlook the modality-specific semantic redundancy patterns that emerge distinctively in multi-modal KV caches. In this work, we first analyze how, beyond simple importance, the KV cache in LVLMs exhibits varying levels of redundancy across attention heads. We show that relying solely on importance can only cover a subset of the full KV cache information distribution, leading to potential loss of semantic coverage. To address this, we propose \texttt{MixKV}, a novel method that mixes importance with diversity for optimized KV cache compression in LVLMs. \texttt{MixKV} adapts to head-wise semantic redundancy, selectively balancing diversity and importance when compressing KV pairs. Extensive experiments demonstrate that \texttt{MixKV} consistently enhances existing methods across multiple LVLMs. Under extreme compression (budget=64), \texttt{MixKV} improves baseline methods by an average of \textbf{5.1\%} across five multi-modal understanding benchmarks and achieves remarkable gains of \textbf{8.0\%} and \textbf{9.0\%} for SnapKV and AdaKV on GUI grounding tasks, all while maintaining comparable inference efficiency. Furthermore, \texttt{MixKV} extends seamlessly to LLMs with comparable performance gains. Our code is available at \href{https://github.com/xuyang-liu16/MixKV}{\textcolor{citeblue}{https://github.com/xuyang-liu16/MixKV}}.
Packet-Level DDoS Data Augmentation Using Dual-Stream Temporal-Field Diffusion
Jul 27, 2025In response to Distributed Denial of Service (DDoS) attacks, recent research efforts increasingly rely on Machine Learning (ML)-based solutions, whose effectiveness largely depends on the quality of labeled training datasets. To address the scarcity of such datasets, data augmentation with synthetic traces is often employed. However, current synthetic trace generation methods struggle to capture the complex temporal patterns and spatial distributions exhibited in emerging DDoS attacks. This results in insufficient resemblance to real traces and unsatisfied detection accuracy when applied to ML tasks. In this paper, we propose Dual-Stream Temporal-Field Diffusion (DSTF-Diffusion), a multi-view, multi-stream network traffic generative model based on diffusion models, featuring two main streams: The field stream utilizes spatial mapping to bridge network data characteristics with pre-trained realms of stable diffusion models, effectively translating complex network interactions into formats that stable diffusion can process, while the spatial stream adopts a dynamic temporal modeling approach, meticulously capturing the intrinsic temporal patterns of network traffic. Extensive experiments demonstrate that data generated by our model exhibits higher statistical similarity to originals compared to current state-of-the-art solutions, and enhance performances on a wide range of downstream tasks.
Addressing Correlated Latent Exogenous Variables in Debiased Recommender Systems
Jun 09, 2025Recommendation systems (RS) aim to provide personalized content, but they face a challenge in unbiased learning due to selection bias, where users only interact with items they prefer. This bias leads to a distorted representation of user preferences, which hinders the accuracy and fairness of recommendations. To address the issue, various methods such as error imputation based, inverse propensity scoring, and doubly robust techniques have been developed. Despite the progress, from the structural causal model perspective, previous debiasing methods in RS assume the independence of the exogenous variables. In this paper, we release this assumption and propose a learning algorithm based on likelihood maximization to learn a prediction model. We first discuss the correlation and difference between unmeasured confounding and our scenario, then we propose a unified method that effectively handles latent exogenous variables. Specifically, our method models the data generation process with latent exogenous variables under mild normality assumptions. We then develop a Monte Carlo algorithm to numerically estimate the likelihood function. Extensive experiments on synthetic datasets and three real-world datasets demonstrate the effectiveness of our proposed method. The code is at https://github.com/WallaceSUI/kdd25-background-variable.
StableFace: Analyzing and Improving Motion Stability for Talking Face Generation
Aug 29, 2022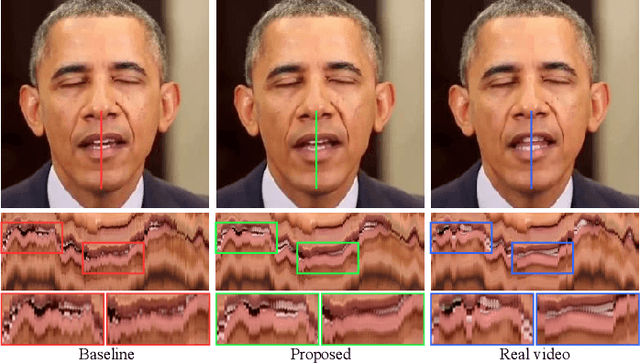
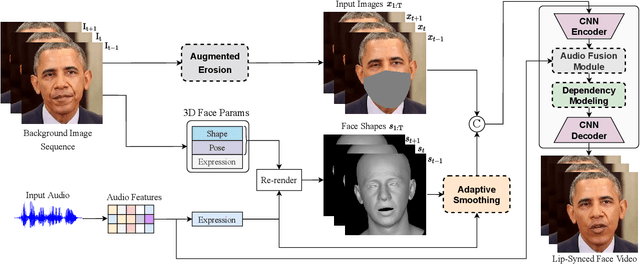
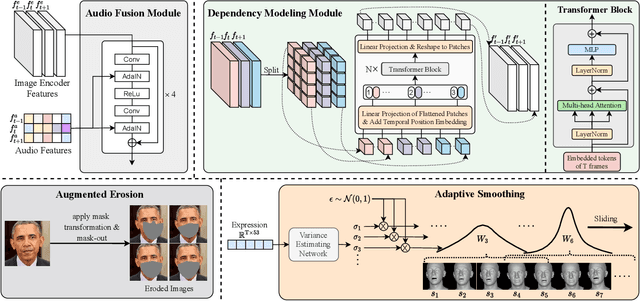

While previous speech-driven talking face generation methods have made significant progress in improving the visual quality and lip-sync quality of the synthesized videos, they pay less attention to lip motion jitters which greatly undermine the realness of talking face videos. What causes motion jitters, and how to mitigate the problem? In this paper, we conduct systematic analyses on the motion jittering problem based on a state-of-the-art pipeline that uses 3D face representations to bridge the input audio and output video, and improve the motion stability with a series of effective designs. We find that several issues can lead to jitters in synthesized talking face video: 1) jitters from the input 3D face representations; 2) training-inference mismatch; 3) lack of dependency modeling among video frames. Accordingly, we propose three effective solutions to address this issue: 1) we propose a gaussian-based adaptive smoothing module to smooth the 3D face representations to eliminate jitters in the input; 2) we add augmented erosions on the input data of the neural renderer in training to simulate the distortion in inference to reduce mismatch; 3) we develop an audio-fused transformer generator to model dependency among video frames. Besides, considering there is no off-the-shelf metric for measuring motion jitters in talking face video, we devise an objective metric (Motion Stability Index, MSI), to quantitatively measure the motion jitters by calculating the reciprocal of variance acceleration. Extensive experimental results show the superiority of our method on motion-stable face video generation, with better quality than previous systems.