 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaxDistill: Improving Metagenomic Taxonomic Annotation via Distilled Genomic Foundation Models
May 22, 2026Metagenomic taxonomic annotation aims to identify the microbial origins of DNA fragments in environmental samples. Traditional methods that rely on sequence similarity are often constrained by the high microbial diversity and the incompleteness of reference databases, which has motivated the development of learning approaches such as Taxometer that perform post hoc correction to learn more informative metagenomic sequence representations. However, these methods typically rely on labels derived from similarity search tools during training, which inevitably introduces noise that can impair representation learning and degrade classification performance. To address this issue, we propose TaxDistill, a knowledge distillation framework for metagenomic classification. We introduce GenomeOcean, a 500M parameter genomic foundation model, as the teacher network to extract deep semantic features and generate soft labels based on confidence. By distilling this soft label information into a lightweight student network, TaxDistill effectively reduces the label noise introduced by initial retrieval tools. Comprehensive experiments on seven diverse CAMI2 datasets demonstrate that TaxDistill outperforms existing baselines in most scenarios. For instance, on the Gastrointestinal dataset, it improves the F1 score of MMseqs2 from 0.763 to 0.941, outperforming the Taxometer baseline. Overall, TaxDistill provides a reliable method for label correction in complex metagenomic analysis.
When Simulation Lies: A Sim-to-Real Benchmark and Domain-Randomized RL Recipe for Tool-Use Agents
May 12, 2026Tool-use language agents are evaluated on benchmarks that assume clean inputs, unambiguous tool registries, and reliable APIs. Real deployments violate all these assumptions: user typos propagate into hallucinated tool names, a misconfigured request timeout can stall an agent indefinitely, and duplicate tool names across servers can freeze an SDK. We study these failures as a sim-to-real gap in the tool-use partially observable Markov decision process (POMDP), where deployment noise enters through the observation, action space, reward-relevant metadata, or transition dynamics. We introduce RobustBench-TC, a benchmark with 22 perturbation types organized by these four POMDP components, each grounded in a verified GitHub issue or documented tool-calling failure. Across 21 models from 1.5B to 32B parameters (including the closed-source o4-mini), the robustness profile is sharply uneven: observation perturbations reduce accuracy by less than 5%, while reward-relevant and transition perturbations reduce accuracy by roughly 40% and 30%, respectively; scale alone does not close these gaps. We then propose ToolRL-DR, a domain-randomization reinforcement learning (RL) recipe that trains a tool-use agent on perturbation-augmented trajectories spanning the three statically encodable POMDP components. On a 3B backbone, ToolRL-DR-Full retains roughly three-quarters of clean accuracy and reaches an aggregate perturbed accuracy comparable to open-source 14B function-calling baselines while substantially narrowing the gap to o4-mini. It closes approximately 27% of the Transition gap despite never seeing transition perturbations in training, suggesting that RL on adversarial static tool-use inputs induces a more persistent retry policy that transfers to unseen runtime failures. The dataset, code and benchmark leaderboard are publicly available.
Machine intelligence supports the full chain of 2D dendrite synthesis
Mar 17, 2026Exemplified by the chemical vapor deposition growth of two-dimensional dendrites, which has potential applications in catalysis and presents a parameter-intensive, data-scarce and reaction process-complex model problem, we devise a machine intelligence-empowered framework for the full chain support of material synthesis, encompassing rapid process optimization, accurate customized synthesis, and comprehensive mechanism deciphering.First, active learning is integrated into the experimental workflow, identifying an optimal recipe for the growth of highly-branched, electrocatalytically-active ReSe2 dendrites through 60 experiments (4 iterations), which account for less than 1.3% of the numerous possible parameter combinations.Then, a prediction accuracy-guided data augmentation strategy is developed combined with a tree-based machine learning (ML) algorithm, unveiling a non-linear correlation between 5 process variables and fractal dimension (DF) of ReSe2 dendrites with only 9 experiment additions, which guides the synthesis of various user-defined DF. Finally, we construct a data-knowledge dual-driven mechanism model by integration of cross-scale characterizations, interpretable ML models, and domain knowledge in thermodynamics and kinetics, unraveling synergistic contributions of multiple process parameters to the product morphology. This work demonstrates the ML potential to transform the research paradigm and is adaptable to broader material synthesis.
HIFICL: High-Fidelity In-Context Learning for Multimodal Tasks
Mar 13, 2026In-Context Learning (ICL) is a significant paradigm for Large Multimodal Models (LMMs), using a few in-context demonstrations (ICDs) for new task adaptation. However, its performance is sensitive to demonstration configurations and computationally expensive. Mathematically, the influence of these demonstrations can be decomposed into a dynamic mixture of the standard attention output and the context values. Current approximation methods simplify this process by learning a "shift vector". Inspired by the exact decomposition, we introduce High-Fidelity In-Context Learning (HIFICL) to more faithfully model the ICL mechanism. HIFICL consists of three key components: 1) a set of "virtual key-value pairs" to act as a learnable context, 2) a low-rank factorization for stable and regularized training, and 3) a simple end-to-end training objective. From another perspective, this mechanism constitutes a form of context-aware Parameter-Efficient Fine-Tuning (PEFT). Extensive experiments show that HiFICL consistently outperforms existing approximation methods on several multimodal benchmarks. The code is available at https://github.com/bbbandari/HiFICL.
Fairness or Fluency? An Investigation into Language Bias of Pairwise LLM-as-a-Judge
Jan 20, 2026Recent advances in Large Language Models (LLMs) have incentivized the development of LLM-as-a-judge, an application of LLMs where they are used as judges to decide the quality of a certain piece of text given a certain context. However, previous studies have demonstrated that LLM-as-a-judge can be biased towards different aspects of the judged texts, which often do not align with human preference. One of the identified biases is language bias, which indicates that the decision of LLM-as-a-judge can differ based on the language of the judged texts. In this paper, we study two types of language bias in pairwise LLM-as-a-judge: (1) performance disparity between languages when the judge is prompted to compare options from the same language, and (2) bias towards options written in major languages when the judge is prompted to compare options of two different languages. We find that for same-language judging, there exist significant performance disparities across language families, with European languages consistently outperforming African languages, and this bias is more pronounced in culturally-related subjects. For inter-language judging, we observe that most models favor English answers, and that this preference is influenced more by answer language than question language. Finally, we investigate whether language bias is in fact caused by low-perplexity bias, a previously identified bias of LLM-as-a-judge, and we find that while perplexity is slightly correlated with language bias, language bias cannot be fully explained by perplexity only.
Multi-objective Aligned Bidword Generation Model for E-commerce Search Advertising
Jun 04, 2025



Retrieval systems primarily address the challenge of matching user queries with the most relevant advertisements, playing a crucial role in e-commerce search advertising. The diversity of user needs and expressions often produces massive long-tail queries that cannot be matched with merchant bidwords or product titles, which results in some advertisements not being recalled, ultimately harming user experience and search efficiency. Existing query rewriting research focuses on various methods such as query log mining, query-bidword vector matching, or generation-based rewriting. However, these methods often fail to simultaneously optimize the relevance and authenticity of the user's original query and rewrite and maximize the revenue potential of recalled ads. In this paper, we propose a Multi-objective aligned Bidword Generation Model (MoBGM), which is composed of a discriminator, generator, and preference alignment module, to address these challenges. To simultaneously improve the relevance and authenticity of the query and rewrite and maximize the platform revenue, we design a discriminator to optimize these key objectives. Using the feedback signal of the discriminator, we train a multi-objective aligned bidword generator that aims to maximize the combined effect of the three objectives. Extensive offline and online experiments show that our proposed algorithm significantly outperforms the state of the art. After deployment, the algorithm has created huge commercial value for the platform, further verifying its feasibility and robustness.
Generative Retrieval and Alignment Model: A New Paradigm for E-commerce Retrieval
Apr 02, 2025Traditional sparse and dense retrieval methods struggle to leverage general world knowledge and often fail to capture the nuanced features of queries and products. With the advent of large language models (LLMs), industrial search systems have started to employ LLMs to generate identifiers for product retrieval. Commonly used identifiers include (1) static/semantic IDs and (2) product term sets. The first approach requires creating a product ID system from scratch, missing out on the world knowledge embedded within LLMs. While the second approach leverages this general knowledge, the significant difference in word distribution between queries and products means that product-based identifiers often do not align well with user search queries, leading to missed product recalls. Furthermore, when queries contain numerous attributes, these algorithms generate a large number of identifiers, making it difficult to assess their quality, which results in low overall recall efficiency. To address these challenges, this paper introduces a novel e-commerce retrieval paradigm: the Generative Retrieval and Alignment Model (GRAM). GRAM employs joint training on text information from both queries and products to generate shared text identifier codes, effectively bridging the gap between queries and products. This approach not only enhances the connection between queries and products but also improves inference efficiency. The model uses a co-alignment strategy to generate codes optimized for maximizing retrieval efficiency. Additionally, it introduces a query-product scoring mechanism to compare product values across different codes, further boosting retrieval efficiency. Extensive offline and online A/B testing demonstrates that GRAM significantly outperforms traditional models and the latest generative retrieval models, confirming its effectiveness and practicality.
Exploring structure diversity in atomic resolution microscopy with graph neural networks
Oct 23, 2024



The emergence of deep learning (DL) has provided great opportunities for the high-throughput analysis of atomic-resolution micrographs. However, the DL models trained by image patches in fixed size generally lack efficiency and flexibility when processing micrographs containing diversified atomic configurations. Herein, inspired by the similarity between the atomic structures and graphs, we describe a few-shot learning framework based on an equivariant graph neural network (EGNN) to analyze a library of atomic structures (e.g., vacancies, phases, grain boundaries, doping, etc.), showing significantly promoted robustness and three orders of magnitude reduced computing parameters compared to the image-driven DL models, which is especially evident for those aggregated vacancy lines with flexible lattice distortion. Besides, the intuitiveness of graphs enables quantitative and straightforward extraction of the atomic-scale structural features in batches, thus statistically unveiling the self-assembly dynamics of vacancy lines under electron beam irradiation. A versatile model toolkit is established by integrating EGNN sub-models for single structure recognition to process images involving varied configurations in the form of a task chain, leading to the discovery of novel doping configurations with superior electrocatalytic properties for hydrogen evolution reactions. This work provides a powerful tool to explore structure diversity in a fast, accurate, and intelligent manner.
Driving Scene Perception Network: Real-time Joint Detection, Depth Estimation and Semantic Segmentation
Mar 10, 2018

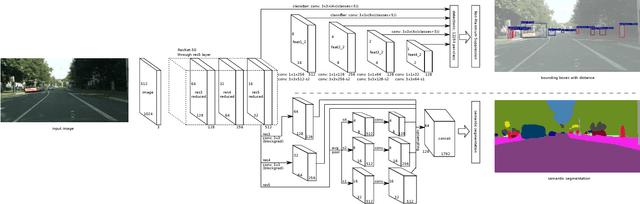

As the demand for enabling high-level autonomous driving has increased in recent years and visual perception is one of the critical features to enable fully autonomous driving, in this paper, we introduce an efficient approach for simultaneous object detection, depth estimation and pixel-level semantic segmentation using a shared convolutional architecture. The proposed network model, which we named Driving Scene Perception Network (DSPNet), uses multi-level feature maps and multi-task learning to improve the accuracy and efficiency of object detection, depth estimation and image segmentation tasks from a single input image. Hence, the resulting network model uses less than 850 MiB of GPU memory and achieves 14.0 fps on NVIDIA GeForce GTX 1080 with a 1024x512 input image, and both precision and efficiency have been improved over combination of single tasks.