 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Simulation Lies: A Sim-to-Real Benchmark and Domain-Randomized RL Recipe for Tool-Use Agents
May 12, 2026Tool-use language agents are evaluated on benchmarks that assume clean inputs, unambiguous tool registries, and reliable APIs. Real deployments violate all these assumptions: user typos propagate into hallucinated tool names, a misconfigured request timeout can stall an agent indefinitely, and duplicate tool names across servers can freeze an SDK. We study these failures as a sim-to-real gap in the tool-use partially observable Markov decision process (POMDP), where deployment noise enters through the observation, action space, reward-relevant metadata, or transition dynamics. We introduce RobustBench-TC, a benchmark with 22 perturbation types organized by these four POMDP components, each grounded in a verified GitHub issue or documented tool-calling failure. Across 21 models from 1.5B to 32B parameters (including the closed-source o4-mini), the robustness profile is sharply uneven: observation perturbations reduce accuracy by less than 5%, while reward-relevant and transition perturbations reduce accuracy by roughly 40% and 30%, respectively; scale alone does not close these gaps. We then propose ToolRL-DR, a domain-randomization reinforcement learning (RL) recipe that trains a tool-use agent on perturbation-augmented trajectories spanning the three statically encodable POMDP components. On a 3B backbone, ToolRL-DR-Full retains roughly three-quarters of clean accuracy and reaches an aggregate perturbed accuracy comparable to open-source 14B function-calling baselines while substantially narrowing the gap to o4-mini. It closes approximately 27% of the Transition gap despite never seeing transition perturbations in training, suggesting that RL on adversarial static tool-use inputs induces a more persistent retry policy that transfers to unseen runtime failures. The dataset, code and benchmark leaderboard are publicly available.
PRIME: Training Free Proactive Reasoning via Iterative Memory Evolution for User-Centric Agent
Apr 08, 2026The development of autonomous tool-use agents for complex, long-horizon tasks in collaboration with human users has become the frontier of agentic research. During multi-turn Human-AI interactions, the dynamic and uncertain nature of user demands poses a significant challenge; agents must not only invoke tools but also iteratively refine their understanding of user intent through effective communication. While recent advances in reinforcement learning offer a path to more capable tool-use agents, existing approaches require expensive training costs and struggle with turn-level credit assignment across extended interaction horizons. To this end, we introduce PRIME (Proactive Reasoning via Iterative Memory Evolution), a gradient-free learning framework that enables continuous agent evolvement through explicit experience accumulation rather than expensive parameter optimization. PRIME distills multi-turn interaction trajectories into structured, human-readable experiences organized across three semantic zones: successful strategies, failure patterns, and user preferences. These experiences evolve through meta-level operations and guide future agent behavior via retrieval-augmented generation. Our experiments across several diverse user-centric environments demonstrate that PRIME achieves competitive performance with gradient-based methods while offering cost-efficiency and interpretability. Together, PRIME presents a practical paradigm for building proactive, collaborative agents that learn from Human-AI interaction without the computational burden of gradient-based training.
AgentSocialBench: Evaluating Privacy Risks in Human-Centered Agentic Social Networks
Apr 01, 2026With the rise of personalized, persistent LLM agent frameworks such as OpenClaw, human-centered agentic social networks in which teams of collaborative AI agents serve individual users in a social network across multiple domains are becoming a reality. This setting creates novel privacy challenges: agents must coordinate across domain boundaries, mediate between humans, and interact with other users' agents, all while protecting sensitive personal information. While prior work has evaluated multi-agent coordination and privacy preservation, the dynamics and privacy risks of human-centered agentic social networks remain unexplored. To this end, we introduce AgentSocialBench, the first benchmark to systematically evaluate privacy risk in this setting, comprising scenarios across seven categories spanning dyadic and multi-party interactions, grounded in realistic user profiles with hierarchical sensitivity labels and directed social graphs. Our experiments reveal that privacy in agentic social networks is fundamentally harder than in single-agent settings: (1) cross-domain and cross-user coordination creates persistent leakage pressure even when agents are explicitly instructed to protect information, (2) privacy instructions that teach agents how to abstract sensitive information paradoxically cause them to discuss it more (we call it abstraction paradox). These findings underscore that current LLM agents lack robust mechanisms for privacy preservation in human-centered agentic social networks, and that new approaches beyond prompt engineering are needed to make agent-mediated social coordination safe for real-world deployment.
SLEA-RL: Step-Level Experience Augmented Reinforcement Learning for Multi-Turn Agentic Training
Mar 18, 2026Large Language Model (LLM) agents have shown strong results on multi-turn tool-use tasks, yet they operate in isolation during training, failing to leverage experiences accumulated across episodes. Existing experience-augmented methods address this by organizing trajectories into retrievable libraries, but they retrieve experiences only once based on the initial task description and hold them constant throughout the episode. In multi-turn settings where observations change at every step, this static retrieval becomes increasingly mismatched as episodes progress. We propose SLEA-RL (Step-Level Experience-Augmented Reinforcement Learning), a framework that retrieves relevant experiences at each decision step conditioned on the current observation. SLEA-RL operates through three components: (i) step-level observation clustering that groups structurally equivalent environmental states for efficient cluster-indexed retrieval; (ii) a self-evolving experience library that distills successful strategies and failure patterns through score-based admission and rate-limited extraction; and (iii) policy optimization with step-level credit assignment for fine-grained advantage estimation across multi-turn episodes. The experience library evolves alongside the policy through semantic analysis rather than gradient updates. Experiments on long-horizon multi-turn agent benchmarks demonstrate that SLEA-RL achieves superior performance compared to various reinforcement learning baselines.
Gen-DFL: Decision-Focused Generative Learning for Robust Decision Making
Feb 08, 2025



Decision-focused learning (DFL) integrates predictive models with downstream optimization, directly training machine learning models to minimize decision errors. While DFL has been shown to provide substantial advantages when compared to a counterpart that treats the predictive and prescriptive models separately, it has also been shown to struggle in high-dimensional and risk-sensitive settings, limiting its applicability in real-world settings. To address this limitation, this paper introduces decision-focused generative learning (Gen-DFL), a novel framework that leverages generative models to adaptively model uncertainty and improve decision quality. Instead of relying on fixed uncertainty sets, Gen-DFL learns a structured representation of the optimization parameters and samples from the tail regions of the learned distribution to enhance robustness against worst-case scenarios. This approach mitigates over-conservatism while capturing complex dependencies in the parameter space. The paper shows, theoretically, that Gen-DFL achieves improved worst-case performance bounds compared to traditional DFL. Empirically, it evaluates Gen-DFL on various scheduling and logistics problems, demonstrating its strong performance against existing DFL methods.
On the Encoder-Decoder Incompatibility in Variational Text Modeling and Beyond
Apr 20, 2020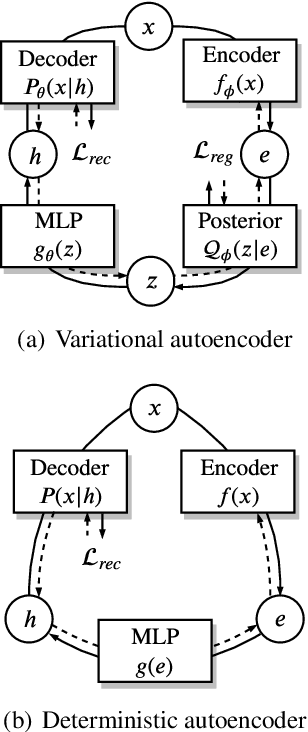
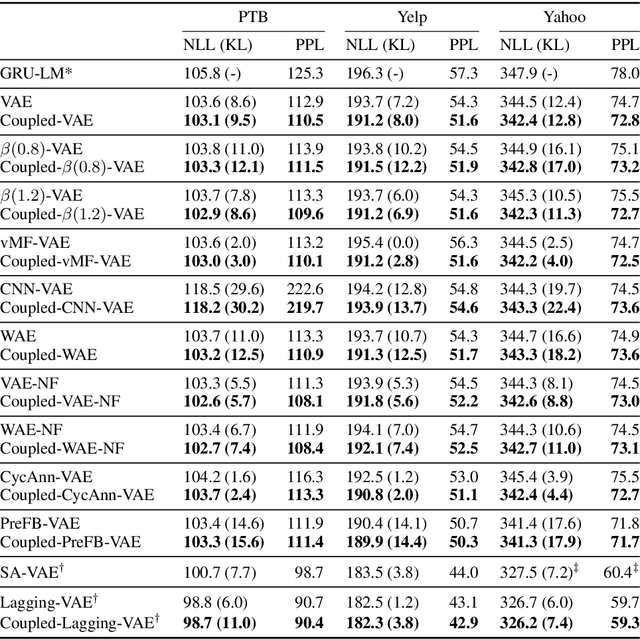
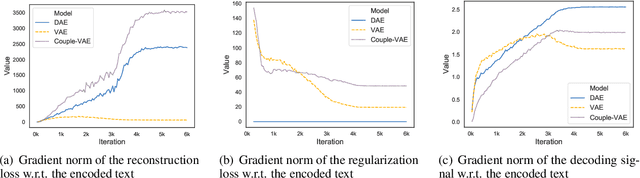
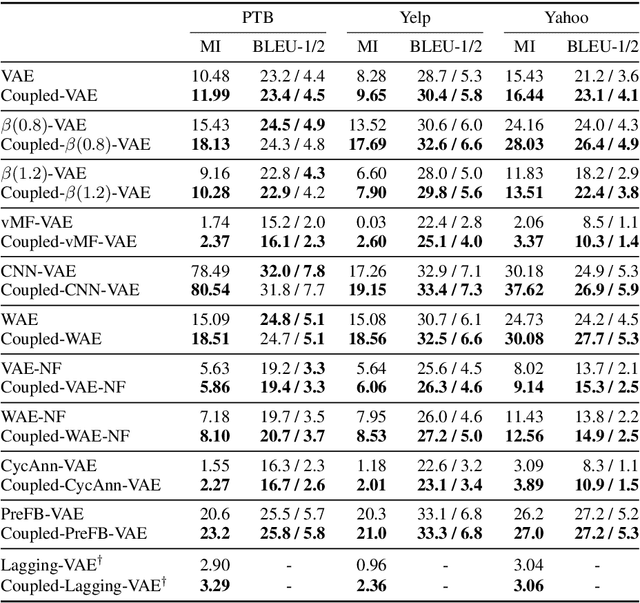
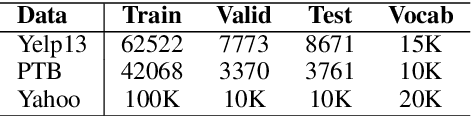
Variational autoencoders (VAEs) combine latent variables with amortized variational inference, whose optimization usually converges into a trivial local optimum termed posterior collapse, especially in text modeling. By tracking the optimization dynamics, we observe the encoder-decoder incompatibility that leads to poor parameterizations of the data manifold. We argue that the trivial local optimum may be avoided by improving the encoder and decoder parameterizations since the posterior network is part of a transition map between them. To this end, we propose Coupled-VAE, which couples a VAE model with a deterministic autoencoder with the same structure and improves the encoder and decoder parameterizations via encoder weight sharing and decoder signal matching. We apply the proposed Coupled-VAE approach to various VAE models with different regularization, posterior family, decoder structure, and optimization strategy. Experiments on benchmark datasets (i.e., PTB, Yelp, and Yahoo) show consistently improved results in terms of probability estimation and richness of the latent space. We also generalize our method to conditional language modeling and propose Coupled-CVAE, which largely improves the diversity of dialogue generation on the Switchboard dataset.
Neural Gaussian Copula for Variational Autoencoder
Sep 09, 2019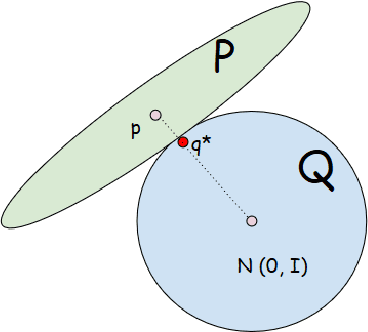

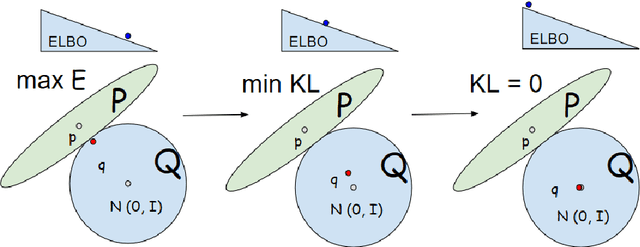
Variational language models seek to estimate the posterior of latent variables with an approximated variational posterior. The model often assumes the variational posterior to be factorized even when the true posterior is not. The learned variational posterior under this assumption does not capture the dependency relationships over latent variables. We argue that this would cause a typical training problem called posterior collapse observed in all other variational language models. We propose Gaussian Copula Variational Autoencoder (VAE) to avert this problem. Copula is widely used to model correlation and dependencies of high-dimensional random variables, and therefore it is helpful to maintain the dependency relationships that are lost in VAE. The empirical results show that by modeling the correlation of latent variables explicitly using a neural parametric copula, we can avert this training difficulty while getting competitive results among all other VAE approaches.
* 11 pages
Riemannian Normalizing Flow on Variational Wasserstein Autoencoder for Text Modeling
Apr 22, 2019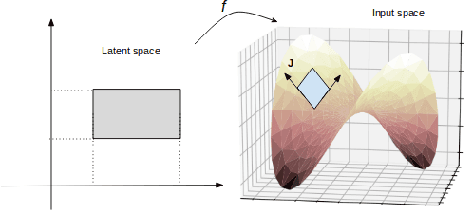
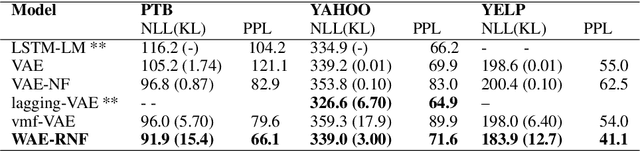


Recurrent Variational Autoencoder has been widely used for language modeling and text generation tasks. These models often face a difficult optimization problem, also known as the Kullback-Leibler (KL) term vanishing issue, where the posterior easily collapses to the prior, and the model will ignore latent codes in generative tasks. To address this problem, we introduce an improved Wasserstein Variational Autoencoder (WAE) with Riemannian Normalizing Flow (RNF) for text modeling. The RNF transforms a latent variable into a space that respects the geometric characteristics of input space, which makes posterior impossible to collapse to the non-informative prior. The Wasserstein objective minimizes the distance between the marginal distribution and the prior directly and therefore does not force the posterior to match the prior. Empirical experiments show that our model avoids KL vanishing over a range of datasets and has better performances in tasks such as language modeling, likelihood approximation, and text generation. Through a series of experiments and analysis over latent space, we show that our model learns latent distributions that respect latent space geometry and is able to generate sentences that are more diverse.