 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFORTIS: Benchmarking Over-Privilege in Agent Skills
May 09, 2026Large language model agents increasingly operate through an intermediate skill layer that mediates between user intent and concrete task execution. This layer is widely treated as an organizational abstraction, but we argue it is also a privilege boundary that current models routinely exceed. We present \textbf{FORTIS}, a benchmark that evaluates over-privilege in agent skills across two stages: whether a model selects the minimally sufficient skill from a large overlapping library, and whether it executes that skill without expanding into broader tools or actions than the skill permits. Across ten frontier models and three domains, we find that over-privileged behavior is the norm rather than the exception. Models consistently reach for higher-privilege skills and tools than the task requires, failing at both stages at rates that remain high even for the strongest available models. Failure is especially severe under the ordinary conditions of real user interaction: incomplete specification, convenience framing, and proximity to skill boundaries. None of these requires adversarial construction. The results indicate that the skill layer, far from containing agent behavior, is itself a primary source of privilege escalation in current systems.
Geometry over Density: Few-Shot Cross-Domain OOD Detection
May 05, 2026Out-of-distribution (OOD) detection identifies test samples that fall outside a model's training distribution, a capability critical for safe deployment in high-stakes applications. Standard OOD detectors are trained on a specific in-distribution (ID) dataset and detect deviations from that single domain. In contrast, we study few-shot cross-domain OOD detection: given a \emph{single} pre-trained model, can we perform OOD detection on \emph{arbitrary} new ID-OOD task pairs using only a handful of ID samples at inference time, with no additional training? We propose \textbf{UFCOD}, a unified framework that achieves this goal through information-geometric analysis of diffusion trajectories. Our key insight is that diffusion noise predictions are score functions (gradients of log-density), and we extract two energy features: \emph{Path Energy} (integrated score magnitude) and \emph{Dynamics Energy} (score smoothness), that form a discrete Sobolev norm capturing how samples interact with the learned diffusion process. The central contribution is a \textbf{train-once, deploy-anywhere} paradigm: a diffusion model trained on a single dataset (e.g., CelebA) serves as a universal feature extractor for OOD detection across semantically unrelated domains (e.g., CIFAR-10, SVHN, Textures). At deployment, each new task requires only $\sim$100 unlabeled ID samples for inference: no retraining, no fine-tuning, no task-specific adaptation. Using 100 ID samples per task, UFCOD achieves 93.7\% average AUROC across 12 cross-domain benchmarks, competitive with methods trained on 50k--163k samples, demonstrating $\sim$500$\times$ improvement in sample efficiency. See our code in https://github.com/lili0415/UFCOD.
The Autonomy Tax: Defense Training Breaks LLM Agents
Mar 19, 2026Large language model (LLM) agents increasingly rely on external tools (file operations, API calls, database transactions) to autonomously complete complex multi-step tasks. Practitioners deploy defense-trained models to protect against prompt injection attacks that manipulate agent behavior through malicious observations or retrieved content. We reveal a fundamental \textbf{capability-alignment paradox}: defense training designed to improve safety systematically destroys agent competence while failing to prevent sophisticated attacks. Evaluating defended models against undefended baselines across 97 agent tasks and 1,000 adversarial prompts, we uncover three systematic biases unique to multi-step agents. \textbf{Agent incompetence bias} manifests as immediate tool execution breakdown, with models refusing or generating invalid actions on benign tasks before observing any external content. \textbf{Cascade amplification bias} causes early failures to propagate through retry loops, pushing defended models to timeout on 99\% of tasks compared to 13\% for baselines. \textbf{Trigger bias} leads to paradoxical security degradation where defended models perform worse than undefended baselines while straightforward attacks bypass defenses at high rates. Root cause analysis reveals these biases stem from shortcut learning: models overfit to surface attack patterns rather than semantic threat understanding, evidenced by extreme variance in defense effectiveness across attack categories. Our findings demonstrate that current defense paradigms optimize for single-turn refusal benchmarks while rendering multi-step agents fundamentally unreliable, necessitating new approaches that preserve tool execution competence under adversarial conditions.
Defenses Against Prompt Attacks Learn Surface Heuristics
Jan 12, 2026Large language models (LLMs) are increasingly deployed in security-sensitive applications, where they must follow system- or developer-specified instructions that define the intended task behavior, while completing benign user requests. When adversarial instructions appear in user queries or externally retrieved content, models may override intended logic. Recent defenses rely on supervised fine-tuning with benign and malicious labels. Although these methods achieve high attack rejection rates, we find that they rely on narrow correlations in defense data rather than harmful intent, leading to systematic rejection of safe inputs. We analyze three recurring shortcut behaviors induced by defense fine-tuning. \emph{Position bias} arises when benign content placed later in a prompt is rejected at much higher rates; across reasoning benchmarks, suffix-task rejection rises from below \textbf{10\%} to as high as \textbf{90\%}. \emph{Token trigger bias} occurs when strings common in attack data raise rejection probability even in benign contexts; inserting a single trigger token increases false refusals by up to \textbf{50\%}. \emph{Topic generalization bias} reflects poor generalization beyond the defense data distribution, with defended models suffering test-time accuracy drops of up to \textbf{40\%}. These findings suggest that current prompt-injection defenses frequently respond to attack-like surface patterns rather than the underlying intent. We introduce controlled diagnostic datasets and a systematic evaluation across two base models and multiple defense pipelines, highlighting limitations of supervised fine-tuning for reliable LLM security.
BabyVLM-V2: Toward Developmentally Grounded Pretraining and Benchmarking of Vision Foundation Models
Dec 11, 2025Early children's developmental trajectories set up a natural goal for sample-efficient pretraining of vision foundation models. We introduce BabyVLM-V2, a developmentally grounded framework for infant-inspired vision-language modeling that extensively improves upon BabyVLM-V1 through a longitudinal, multifaceted pretraining set, a versatile model, and, most importantly, DevCV Toolbox for cognitive evaluation. The pretraining set maximizes coverage while minimizing curation of a longitudinal, infant-centric audiovisual corpus, yielding video-utterance, image-utterance, and multi-turn conversational data that mirror infant experiences. DevCV Toolbox adapts all vision-related measures of the recently released NIH Baby Toolbox into a benchmark suite of ten multimodal tasks, covering spatial reasoning, memory, and vocabulary understanding aligned with early children's capabilities. Experimental results show that a compact model pretrained from scratch can achieve competitive performance on DevCV Toolbox, outperforming GPT-4o on some tasks. We hope the principled, unified BabyVLM-V2 framework will accelerate research in developmentally plausible pretraining of vision foundation models.
Don't Let It Hallucinate: Premise Verification via Retrieval-Augmented Logical Reasoning
Apr 08, 2025Large language models (LLMs) have shown substantial capacity for generating fluent, contextually appropriate responses. However, they can produce hallucinated outputs, especially when a user query includes one or more false premises-claims that contradict established facts. Such premises can mislead LLMs into offering fabricated or misleading details. Existing approaches include pretraining, fine-tuning, and inference-time techniques that often rely on access to logits or address hallucinations after they occur. These methods tend to be computationally expensive, require extensive training data, or lack proactive mechanisms to prevent hallucination before generation, limiting their efficiency in real-time applications. We propose a retrieval-based framework that identifies and addresses false premises before generation. Our method first transforms a user's query into a logical representation, then applies retrieval-augmented generation (RAG) to assess the validity of each premise using factual sources. Finally, we incorporate the verification results into the LLM's prompt to maintain factual consistency in the final output. Experiments show that this approach effectively reduces hallucinations, improves factual accuracy, and does not require access to model logits or large-scale fine-tuning.
DecAlign: Hierarchical Cross-Modal Alignment for Decoupled Multimodal Representation Learning
Mar 14, 2025


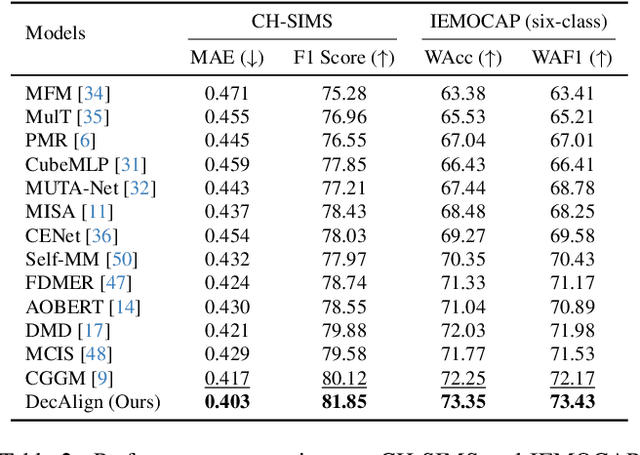
Multimodal representation learning aims to capture both shared and complementary semantic information across multiple modalities. However, the intrinsic heterogeneity of diverse modalities presents substantial challenges to achieve effective cross-modal collaboration and integration. To address this, we introduce DecAlign, a novel hierarchical cross-modal alignment framework designed to decouple multimodal representations into modality-unique (heterogeneous) and modality-common (homogeneous) features. For handling heterogeneity, we employ a prototype-guided optimal transport alignment strategy leveraging gaussian mixture modeling and multi-marginal transport plans, thus mitigating distribution discrepancies while preserving modality-unique characteristics. To reinforce homogeneity, we ensure semantic consistency across modalities by aligning latent distribution matching with Maximum Mean Discrepancy regularization. Furthermore, we incorporate a multimodal transformer to enhance high-level semantic feature fusion, thereby further reducing cross-modal inconsistencies. Our extensive experiments on four widely used multimodal benchmarks demonstrate that DecAlign consistently outperforms existing state-of-the-art methods across five metrics. These results highlight the efficacy of DecAlign in enhancing superior cross-modal alignment and semantic consistency while preserving modality-unique features, marking a significant advancement in multimodal representation learning scenarios. Our project page is at https://taco-group.github.io/DecAlign and the code is available at https://github.com/taco-group/DecAlign.
AD-LLM: Benchmarking Large Language Models for Anomaly Detection
Dec 15, 2024



Anomaly detection (AD) is an important machine learning task with many real-world uses, including fraud detection, medical diagnosis, and industrial monitoring. Within natural language processing (NLP), AD helps detect issues like spam, misinformation, and unusual user activity. Although large language models (LLMs) have had a strong impact on tasks such as text generation and summarization, their potential in AD has not been studied enough. This paper introduces AD-LLM, the first benchmark that evaluates how LLMs can help with NLP anomaly detection. We examine three key tasks: (i) zero-shot detection, using LLMs' pre-trained knowledge to perform AD without tasks-specific training; (ii) data augmentation, generating synthetic data and category descriptions to improve AD models; and (iii) model selection, using LLMs to suggest unsupervised AD models. Through experiments with different datasets, we find that LLMs can work well in zero-shot AD, that carefully designed augmentation methods are useful, and that explaining model selection for specific datasets remains challenging. Based on these results, we outline six future research directions on LLMs for AD.
PyOD 2: A Python Library for Outlier Detection with LLM-powered Model Selection
Dec 11, 2024


Outlier detection (OD), also known as anomaly detection, is a critical machine learning (ML) task with applications in fraud detection, network intrusion detection, clickstream analysis, recommendation systems, and social network moderation. Among open-source libraries for outlier detection, the Python Outlier Detection (PyOD) library is the most widely adopted, with over 8,500 GitHub stars, 25 million downloads, and diverse industry usage. However, PyOD currently faces three limitations: (1) insufficient coverage of modern deep learning algorithms, (2) fragmented implementations across PyTorch and TensorFlow, and (3) no automated model selection, making it hard for non-experts. To address these issues, we present PyOD Version 2 (PyOD 2), which integrates 12 state-of-the-art deep learning models into a unified PyTorch framework and introduces a large language model (LLM)-based pipeline for automated OD model selection. These improvements simplify OD workflows, provide access to 45 algorithms, and deliver robust performance on various datasets. In this paper, we demonstrate how PyOD 2 streamlines the deployment and automation of OD models and sets a new standard in both research and industry. PyOD 2 is accessible at [https://github.com/yzhao062/pyod](https://github.com/yzhao062/pyod). This study aligns with the Web Mining and Content Analysis track, addressing topics such as the robustness of Web mining methods and the quality of algorithmically-generated Web data.
DPU: Dynamic Prototype Updating for Multimodal Out-of-Distribution Detection
Nov 12, 2024



Out-of-distribution (OOD) detection is essential for ensuring the robustness of machine learning models by identifying samples that deviate from the training distribution. While traditional OOD detection has primarily focused on single-modality inputs, such as images, recent advances in multimodal models have demonstrated the potential of leveraging multiple modalities (e.g., video, optical flow, audio) to enhance detection performance. However, existing methods often overlook intra-class variability within in-distribution (ID) data, assuming that samples of the same class are perfectly cohesive and consistent. This assumption can lead to performance degradation, especially when prediction discrepancies are uniformly amplified across all samples. To address this issue, we propose Dynamic Prototype Updating (DPU), a novel plug-and-play framework for multimodal OOD detection that accounts for intra-class variations. Our method dynamically updates class center representations for each class by measuring the variance of similar samples within each batch, enabling adaptive adjustments. This approach allows us to amplify prediction discrepancies based on the updated class centers, thereby improving the model's robustness and generalization across different modalities. Extensive experiments on two tasks, five datasets, and nine base OOD algorithms demonstrate that DPU significantly improves OOD detection performance, setting a new state-of-the-art in multimodal OOD detection, with improvements of up to 80 percent in Far-OOD detection. To facilitate accessibility and reproducibility, our code is publicly available on GitHub.