 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Simulation Lies: A Sim-to-Real Benchmark and Domain-Randomized RL Recipe for Tool-Use Agents
May 12, 2026Tool-use language agents are evaluated on benchmarks that assume clean inputs, unambiguous tool registries, and reliable APIs. Real deployments violate all these assumptions: user typos propagate into hallucinated tool names, a misconfigured request timeout can stall an agent indefinitely, and duplicate tool names across servers can freeze an SDK. We study these failures as a sim-to-real gap in the tool-use partially observable Markov decision process (POMDP), where deployment noise enters through the observation, action space, reward-relevant metadata, or transition dynamics. We introduce RobustBench-TC, a benchmark with 22 perturbation types organized by these four POMDP components, each grounded in a verified GitHub issue or documented tool-calling failure. Across 21 models from 1.5B to 32B parameters (including the closed-source o4-mini), the robustness profile is sharply uneven: observation perturbations reduce accuracy by less than 5%, while reward-relevant and transition perturbations reduce accuracy by roughly 40% and 30%, respectively; scale alone does not close these gaps. We then propose ToolRL-DR, a domain-randomization reinforcement learning (RL) recipe that trains a tool-use agent on perturbation-augmented trajectories spanning the three statically encodable POMDP components. On a 3B backbone, ToolRL-DR-Full retains roughly three-quarters of clean accuracy and reaches an aggregate perturbed accuracy comparable to open-source 14B function-calling baselines while substantially narrowing the gap to o4-mini. It closes approximately 27% of the Transition gap despite never seeing transition perturbations in training, suggesting that RL on adversarial static tool-use inputs induces a more persistent retry policy that transfers to unseen runtime failures. The dataset, code and benchmark leaderboard are publicly available.
Beyond Idealized Patients: Evaluating LLMs under Challenging Patient Behaviors in Medical Consultations
Mar 31, 2026Large language models (LLMs) are increasingly used for medical consultation and health information support. In this high-stakes setting, safety depends not only on medical knowledge, but also on how models respond when patient inputs are unclear, inconsistent, or misleading. However, most existing medical LLM evaluations assume idealized and well-posed patient questions, which limits their realism. In this paper, we study challenging patient behaviors that commonly arise in real medical consultations and complicate safe clinical reasoning. We define four clinically grounded categories of such behaviors: information contradiction, factual inaccuracy, self-diagnosis, and care resistance. For each behavior, we specify concrete failure criteria that capture unsafe responses. Building on four existing medical dialogue datasets, we introduce CPB-Bench (Challenging Patient Behaviors Benchmark), a bilingual (English and Chinese) benchmark of 692 multi-turn dialogues annotated with these behaviors. We evaluate a range of open- and closed-source LLMs on their responses to challenging patient utterances. While models perform well overall, we identify consistent, behavior-specific failure patterns, with particular difficulty in handling contradictory or medically implausible patient information. We also study four intervention strategies and find that they yield inconsistent improvements and can introduce unnecessary corrections. We release the dataset and code.
Fairness or Fluency? An Investigation into Language Bias of Pairwise LLM-as-a-Judge
Jan 20, 2026Recent advances in Large Language Models (LLMs) have incentivized the development of LLM-as-a-judge, an application of LLMs where they are used as judges to decide the quality of a certain piece of text given a certain context. However, previous studies have demonstrated that LLM-as-a-judge can be biased towards different aspects of the judged texts, which often do not align with human preference. One of the identified biases is language bias, which indicates that the decision of LLM-as-a-judge can differ based on the language of the judged texts. In this paper, we study two types of language bias in pairwise LLM-as-a-judge: (1) performance disparity between languages when the judge is prompted to compare options from the same language, and (2) bias towards options written in major languages when the judge is prompted to compare options of two different languages. We find that for same-language judging, there exist significant performance disparities across language families, with European languages consistently outperforming African languages, and this bias is more pronounced in culturally-related subjects. For inter-language judging, we observe that most models favor English answers, and that this preference is influenced more by answer language than question language. Finally, we investigate whether language bias is in fact caused by low-perplexity bias, a previously identified bias of LLM-as-a-judge, and we find that while perplexity is slightly correlated with language bias, language bias cannot be fully explained by perplexity only.
FairREAD: Re-fusing Demographic Attributes after Disentanglement for Fair Medical Image Classification
Dec 20, 2024Recent advancements in deep learning have shown transformative potential in medical imaging, yet concerns about fairness persist due to performance disparities across demographic subgroups. Existing methods aim to address these biases by mitigating sensitive attributes in image data; however, these attributes often carry clinically relevant information, and their removal can compromise model performance-a highly undesirable outcome. To address this challenge, we propose Fair Re-fusion After Disentanglement (FairREAD), a novel, simple, and efficient framework that mitigates unfairness by re-integrating sensitive demographic attributes into fair image representations. FairREAD employs orthogonality constraints and adversarial training to disentangle demographic information while using a controlled re-fusion mechanism to preserve clinically relevant details. Additionally, subgroup-specific threshold adjustments ensure equitable performance across demographic groups. Comprehensive evaluations on a large-scale clinical X-ray dataset demonstrate that FairREAD significantly reduces unfairness metrics while maintaining diagnostic accuracy, establishing a new benchmark for fairness and performance in medical image classification.
Bayesian Calibration of Win Rate Estimation with LLM Evaluators
Nov 07, 2024



Recent advances in large language models (LLMs) show the potential of using LLMs as evaluators for assessing the quality of text generations from LLMs. However, applying LLM evaluators naively to compare or judge between different systems can lead to unreliable results due to the intrinsic win rate estimation bias of LLM evaluators. In order to mitigate this problem, we propose two calibration methods, Bayesian Win Rate Sampling (BWRS) and Bayesian Dawid-Skene, both of which leverage Bayesian inference to more accurately infer the true win rate of generative language models. We empirically validate our methods on six datasets covering story generation, summarization, and instruction following tasks. We show that both our methods are effective in improving the accuracy of win rate estimation using LLMs as evaluators, offering a promising direction for reliable automatic text quality evaluation.
Nuclear Norm based Matrix Regression with Applications to Face Recognition with Occlusion and Illumination Changes
May 06, 2014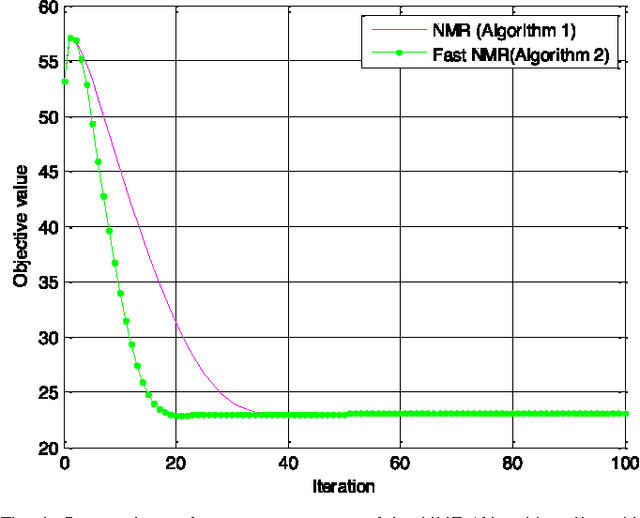
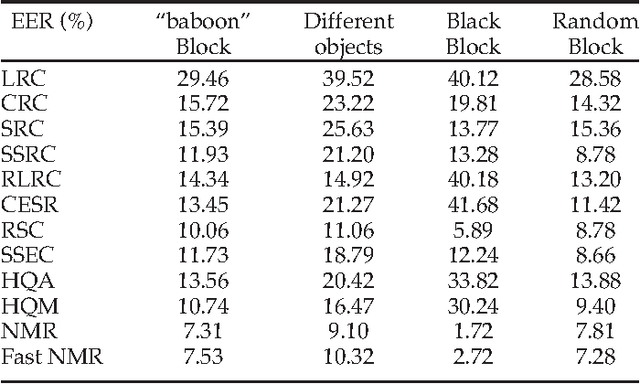
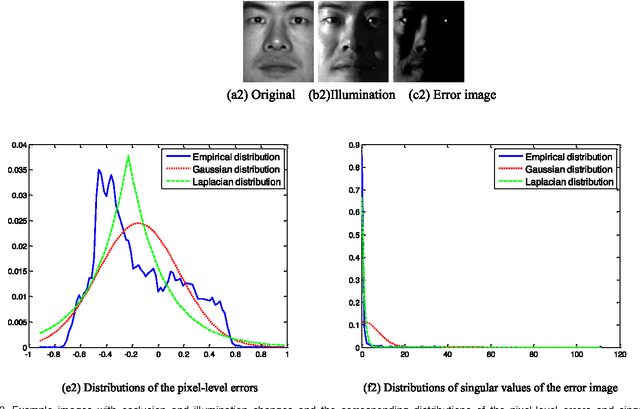
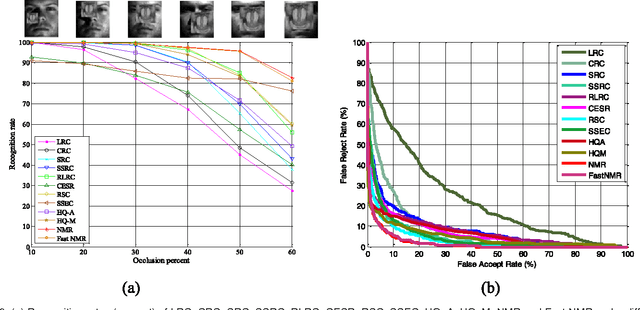
Recently regression analysis becomes a popular tool for face recognition. The existing regression methods all use the one-dimensional pixel-based error model, which characterizes the representation error pixel by pixel individually and thus neglects the whole structure of the error image. We observe that occlusion and illumination changes generally lead to a low-rank error image. To make use of this low-rank structural information, this paper presents a two-dimensional image matrix based error model, i.e. matrix regression, for face representation and classification. Our model uses the minimal nuclear norm of representation error image as a criterion, and the alternating direction method of multipliers method to calculate the regression coefficients. Compared with the current regression methods, the proposed Nuclear Norm based Matrix Regression (NMR) model is more robust for alleviating the effect of illumination, and more intuitive and powerful for removing the structural noise caused by occlusion. We experiment using four popular face image databases, the Extended Yale B database, the AR database, the Multi-PIE and the FRGC database. Experimental results demonstrate the performance advantage of NMR over the state-of-the-art regression based face recognition methods.