 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounding System-Induced Biases in Recommender Systems with A Randomized Dataset
Mar 21, 2023Debiased recommendation with a randomized dataset has shown very promising results in mitigating the system-induced biases. However, it still lacks more theoretical insights or an ideal optimization objective function compared with the other more well studied route without a randomized dataset. To bridge this gap, we study the debiasing problem from a new perspective and propose to directly minimize the upper bound of an ideal objective function, which facilitates a better potential solution to the system-induced biases. Firstly, we formulate a new ideal optimization objective function with a randomized dataset. Secondly, according to the prior constraints that an adopted loss function may satisfy, we derive two different upper bounds of the objective function, i.e., a generalization error bound with the triangle inequality and a generalization error bound with the separability. Thirdly, we show that most existing related methods can be regarded as the insufficient optimization of these two upper bounds. Fourthly, we propose a novel method called debiasing approximate upper bound with a randomized dataset (DUB), which achieves a more sufficient optimization of these upper bounds. Finally, we conduct extensive experiments on a public dataset and a real product dataset to verify the effectiveness of our DUB.
Self-Sampling Training and Evaluation for the Accuracy-Bias Tradeoff in Recommendation
Feb 07, 2023



Research on debiased recommendation has shown promising results. However, some issues still need to be handled for its application in industrial recommendation. For example, most of the existing methods require some specific data, architectures and training methods. In this paper, we first argue through an online study that arbitrarily removing all the biases in industrial recommendation may not consistently yield a desired performance improvement. For the situation that a randomized dataset is not available, we propose a novel self-sampling training and evaluation (SSTE) framework to achieve the accuracy-bias tradeoff in recommendation, i.e., eliminate the harmful biases and preserve the beneficial ones. Specifically, SSTE uses a self-sampling module to generate some subsets with different degrees of bias from the original training and validation data. A self-training module infers the beneficial biases and learns better tradeoff based on these subsets, and a self-evaluation module aims to use these subsets to construct more plausible references to reflect the optimized model. Finally, we conduct extensive offline experiments on two datasets to verify the effectiveness of our SSTE. Moreover, we deploy our SSTE in homepage recommendation of a famous financial management product called Tencent Licaitong, and find very promising results in an online A/B test.
Feature Representation Learning for Click-through Rate Prediction: A Review and New Perspectives
Feb 04, 2023Representation learning has been a critical topic in machine learning. In Click-through Rate Prediction, most features are represented as embedding vectors and learned simultaneously with other parameters in the model. With the development of CTR models, feature representation learning has become a trending topic and has been extensively studied by both industrial and academic researchers in recent years. This survey aims at summarizing the feature representation learning in a broader picture and pave the way for future research. To achieve such a goal, we first present a taxonomy of current research methods on feature representation learning following two main issues: (i) which feature to represent and (ii) how to represent these features. Then we give a detailed description of each method regarding these two issues. Finally, the review concludes with a discussion on the future directions of this field.
Optimizing Feature Set for Click-Through Rate Prediction
Jan 26, 2023Click-through prediction (CTR) models transform features into latent vectors and enumerate possible feature interactions to improve performance based on the input feature set. Therefore, when selecting an optimal feature set, we should consider the influence of both feature and its interaction. However, most previous works focus on either feature field selection or only select feature interaction based on the fixed feature set to produce the feature set. The former restricts search space to the feature field, which is too coarse to determine subtle features. They also do not filter useless feature interactions, leading to higher computation costs and degraded model performance. The latter identifies useful feature interaction from all available features, resulting in many redundant features in the feature set. In this paper, we propose a novel method named OptFS to address these problems. To unify the selection of feature and its interaction, we decompose the selection of each feature interaction into the selection of two correlated features. Such a decomposition makes the model end-to-end trainable given various feature interaction operations. By adopting feature-level search space, we set a learnable gate to determine whether each feature should be within the feature set. Because of the large-scale search space, we develop a learning-by-continuation training scheme to learn such gates. Hence, OptFS generates the feature set only containing features which improve the final prediction results. Experimentally, we evaluate OptFS on three public datasets, demonstrating OptFS can optimize feature sets which enhance the model performance and further reduce both the storage and computational cost.
DIWIFT: Discovering Instance-wise Influential Features for Tabular Data
Jul 06, 2022
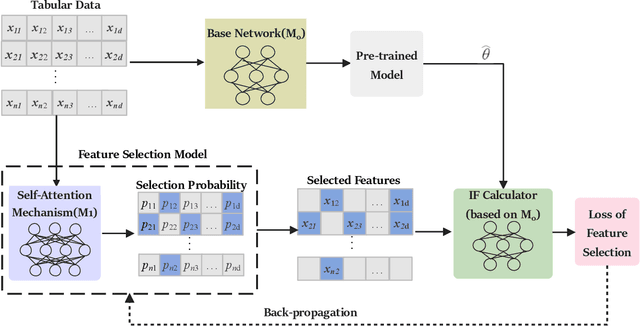
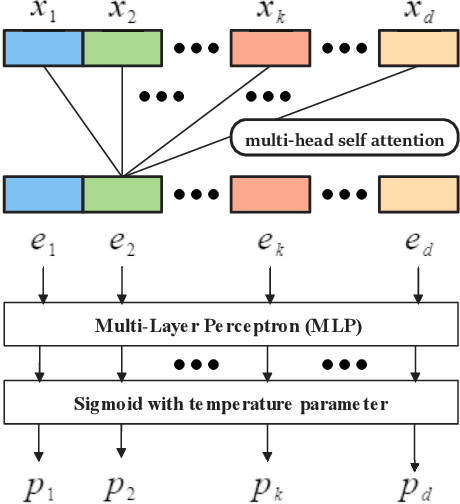
Tabular data is one of the most common data storage formats in business applications, ranging from retail, bank and E-commerce. These applications rely heavily on machine learning models to achieve business success. One of the critical problems in learning tabular data is to distinguish influential features from all the predetermined features. Global feature selection has been well-studied for quite some time, assuming that all instances have the same influential feature subsets. However, different instances rely on different feature subsets in practice, which also gives rise to that instance-wise feature selection receiving increasing attention in recent studies. In this paper, we first propose a novel method for discovering instance-wise influential features for tabular data (DIWIFT), the core of which is to introduce the influence function to measure the importance of an instance-wise feature. DIWIFT is capable of automatically discovering influential feature subsets of different sizes in different instances, which is different from global feature selection that considers all instances with the same influential feature subset. On the other hand, different from the previous instance-wise feature selection, DIWIFT minimizes the validation loss on the validation set and is thus more robust to the distribution shift existing in the training dataset and test dataset, which is important in tabular data. Finally, we conduct extensive experiments on both synthetic and real-world datasets to validate the effectiveness of our DIWIFT, compared it with baseline methods. Moreover, we also demonstrate the robustness of our method via some ablation experiments.
A Graph-Enhanced Click Model for Web Search
Jun 17, 2022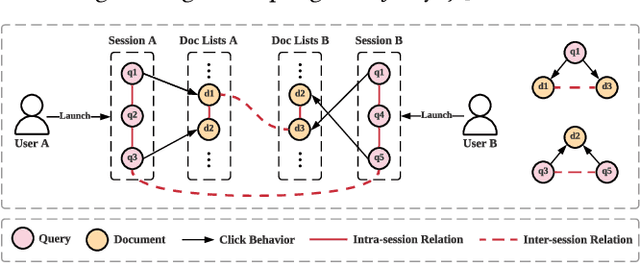

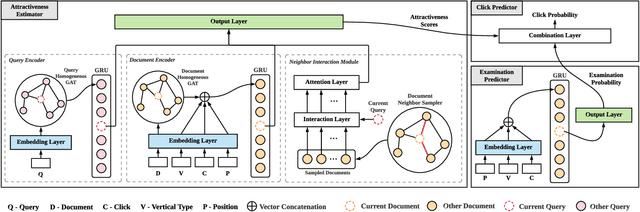
To better exploit search logs and model users' behavior patterns, numerous click models are proposed to extract users' implicit interaction feedback. Most traditional click models are based on the probabilistic graphical model (PGM) framework, which requires manually designed dependencies and may oversimplify user behaviors. Recently, methods based on neural networks are proposed to improve the prediction accuracy of user behaviors by enhancing the expressive ability and allowing flexible dependencies. However, they still suffer from the data sparsity and cold-start problems. In this paper, we propose a novel graph-enhanced click model (GraphCM) for web search. Firstly, we regard each query or document as a vertex, and propose novel homogeneous graph construction methods for queries and documents respectively, to fully exploit both intra-session and inter-session information for the sparsity and cold-start problems. Secondly, following the examination hypothesis, we separately model the attractiveness estimator and examination predictor to output the attractiveness scores and examination probabilities, where graph neural networks and neighbor interaction techniques are applied to extract the auxiliary information encoded in the pre-constructed homogeneous graphs. Finally, we apply combination functions to integrate examination probabilities and attractiveness scores into click predictions. Extensive experiments conducted on three real-world session datasets show that GraphCM not only outperforms the state-of-art models, but also achieves superior performance in addressing the data sparsity and cold-start problems.
Regularization Penalty Optimization for Addressing Data Quality Variance in OoD Algorithms
Jun 12, 2022
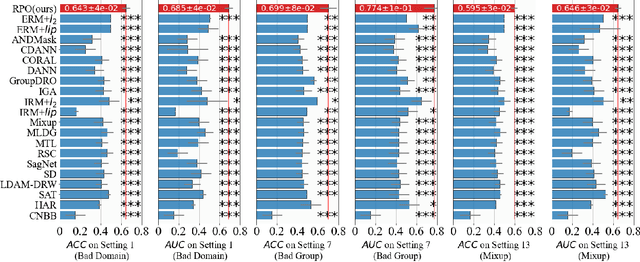

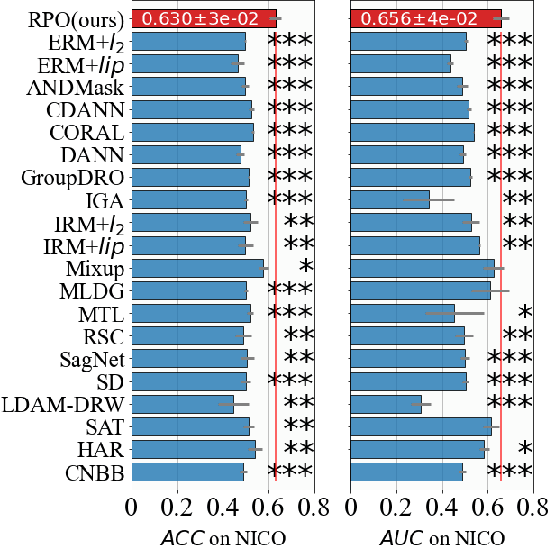
Due to the poor generalization performance of traditional empirical risk minimization (ERM) in the case of distributional shift, Out-of-Distribution (OoD) generalization algorithms receive increasing attention. However, OoD generalization algorithms overlook the great variance in the quality of training data, which significantly compromises the accuracy of these methods. In this paper, we theoretically reveal the relationship between training data quality and algorithm performance and analyze the optimal regularization scheme for Lipschitz regularized invariant risk minimization. A novel algorithm is proposed based on the theoretical results to alleviate the influence of low-quality data at both the sample level and the domain level. The experiments on both the regression and classification benchmarks validate the effectiveness of our method with statistical significance.
ReLoop: A Self-Correction Continual Learning Loop for Recommender Systems
Apr 24, 2022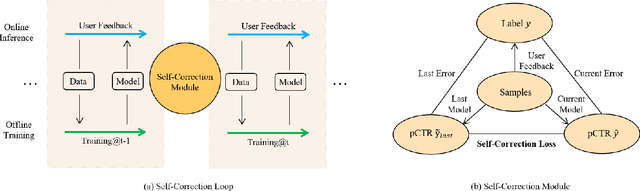
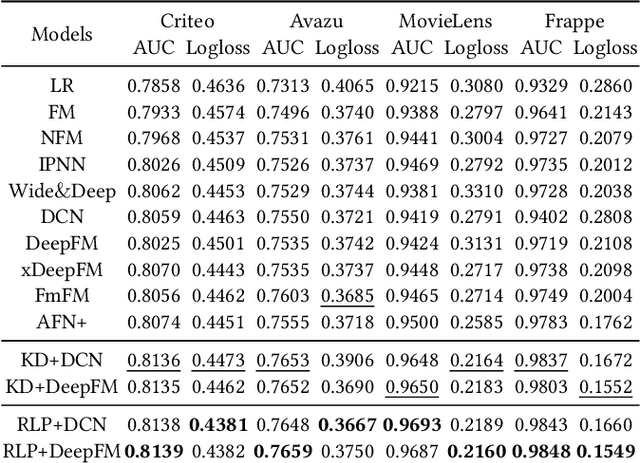
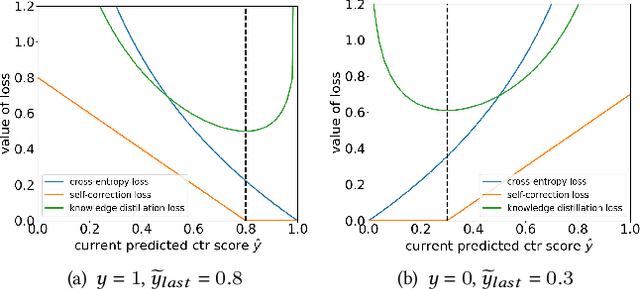

Deep learning-based recommendation has become a widely adopted technique in various online applications. Typically, a deployed model undergoes frequent re-training to capture users' dynamic behaviors from newly collected interaction logs. However, the current model training process only acquires users' feedbacks as labels, but fail to take into account the errors made in previous recommendations. Inspired by the intuition that humans usually reflect and learn from mistakes, in this paper, we attempt to build a self-correction learning loop (dubbed ReLoop) for recommender systems. In particular, a new customized loss is employed to encourage every new model version to reduce prediction errors over the previous model version during training. Our ReLoop learning framework enables a continual self-correction process in the long run and thus is expected to obtain better performance over existing training strategies. Both offline experiments and an online A/B test have been conducted to validate the effectiveness of ReLoop.
Contrastive Learning with Positive-Negative Frame Mask for Music Representation
Apr 03, 2022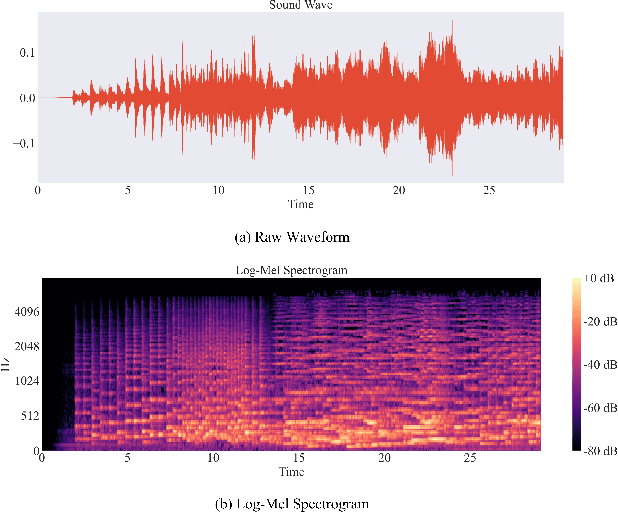
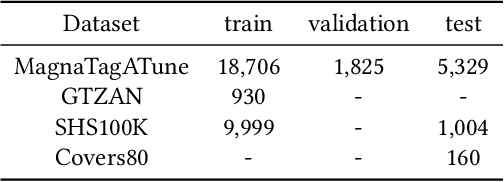
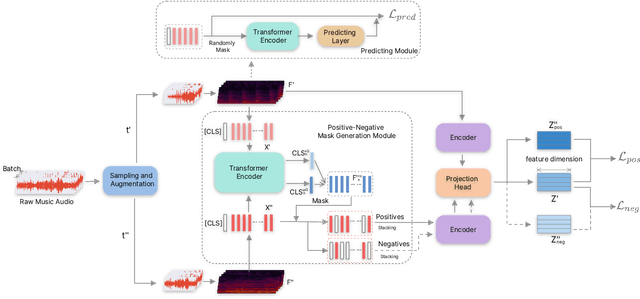
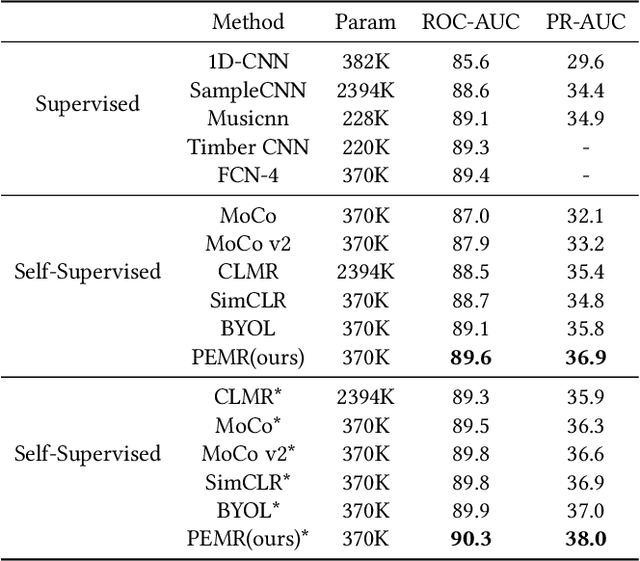
Self-supervised learning, especially contrastive learning, has made an outstanding contribution to the development of many deep learning research fields. Recently, researchers in the acoustic signal processing field noticed its success and leveraged contrastive learning for better music representation. Typically, existing approaches maximize the similarity between two distorted audio segments sampled from the same music. In other words, they ensure a semantic agreement at the music level. However, those coarse-grained methods neglect some inessential or noisy elements at the frame level, which may be detrimental to the model to learn the effective representation of music. Towards this end, this paper proposes a novel Positive-nEgative frame mask for Music Representation based on the contrastive learning framework, abbreviated as PEMR. Concretely, PEMR incorporates a Positive-Negative Mask Generation module, which leverages transformer blocks to generate frame masks on the Log-Mel spectrogram. We can generate self-augmented negative and positive samples by masking important components or inessential components, respectively. We devise a novel contrastive learning objective to accommodate both self-augmented positives/negatives sampled from the same music. We conduct experiments on four public datasets. The experimental results of two music-related downstream tasks, music classification, and cover song identification, demonstrate the generalization ability and transferability of music representation learned by PEMR.
PEAR: Personalized Re-ranking with Contextualized Transformer for Recommendation
Mar 23, 2022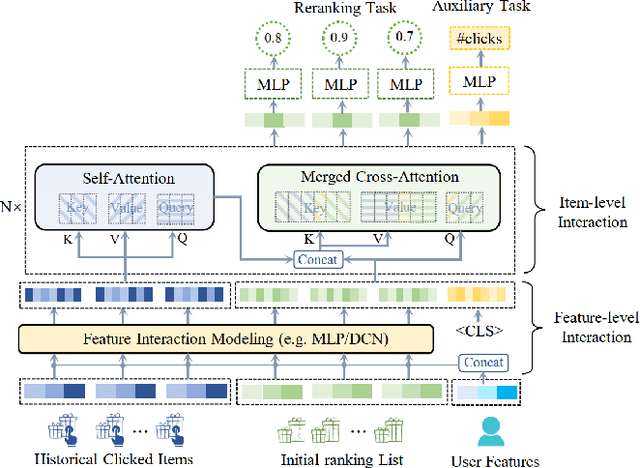
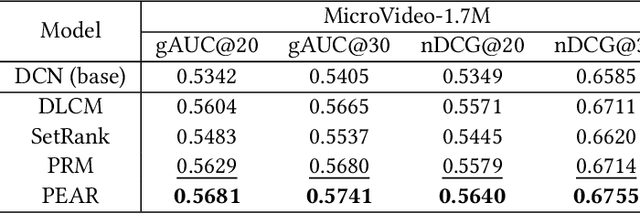
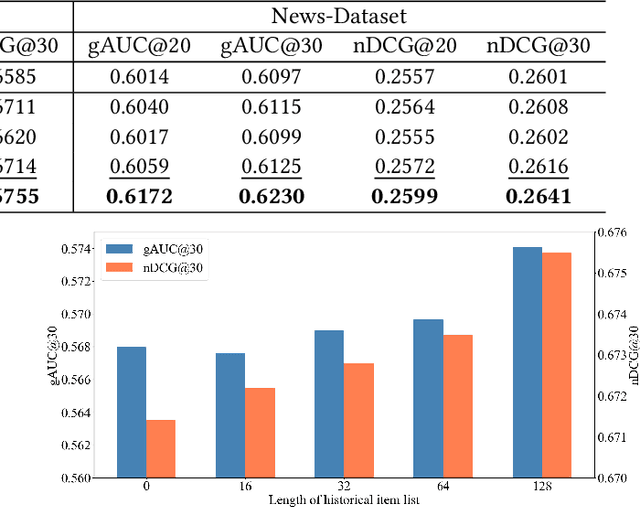

The goal of recommender systems is to provide ordered item lists to users that best match their interests. As a critical task in the recommendation pipeline, re-ranking has received increasing attention in recent years. In contrast to conventional ranking models that score each item individually, re-ranking aims to explicitly model the mutual influences among items to further refine the ordering of items given an initial ranking list. In this paper, we present a personalized re-ranking model (dubbed PEAR) based on contextualized transformer. PEAR makes several major improvements over the existing methods. Specifically, PEAR not only captures feature-level and item-level interactions, but also models item contexts from both the initial ranking list and the historical clicked item list. In addition to item-level ranking score prediction, we also augment the training of PEAR with a list-level classification task to assess users' satisfaction on the whole ranking list. Experimental results on both public and production datasets have shown the superior effectiveness of PEAR compared to the previous re-ranking models.