 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language-Action Safety: Threats, Challenges, Evaluations, and Mechanisms
Apr 26, 2026Vision-Language-Action (VLA) models are emerging as a unified substrate for embodied intelligence. This shift raises a new class of safety challenges, stemming from the embodied nature of VLA systems, including irreversible physical consequences, a multimodal attack surface across vision, language, and state, real-time latency constraints on defense, error propagation over long-horizon trajectories, and vulnerabilities in the data supply chain. Yet the literature remains fragmented across robotic learning, adversarial machine learning, AI alignment, and autonomous systems safety. This survey provides a unified and up-to-date overview of safety in Vision-Language-Action models. We organize the field along two parallel timing axes, attack timing (training-time vs. inference-time and defense timing (training-time vs. inference-time, linking each class of threat to the stage at which it can be mitigated. We first define the scope of VLA safety, distinguishing it from text-only LLM safety and classical robotic safety, and review the foundations of VLA models, including architectures, training paradigms, and inference mechanisms. We then examine the literature through four lenses: Attacks, Defenses, Evaluation, and Deployment. We survey training-time threats such as data poisoning and backdoors, as well as inference-time attacks including adversarial patches, cross-modal perturbations, semantic jailbreaks, and freezing attacks. We review training-time and runtime defenses, analyze existing benchmarks and metrics, and discuss safety challenges across six deployment domains. Finally, we highlight key open problems, including certified robustness for embodied trajectories, physically realizable defenses, safety-aware training, unified runtime safety architectures, and standardized evaluation.
NoLan: Mitigating Object Hallucinations in Large Vision-Language Models via Dynamic Suppression of Language Priors
Feb 25, 2026Object hallucination is a critical issue in Large Vision-Language Models (LVLMs), where outputs include objects that do not appear in the input image. A natural question arises from this phenomenon: Which component of the LVLM pipeline primarily contributes to object hallucinations? The vision encoder to perceive visual information, or the language decoder to generate text responses? In this work, we strive to answer this question through designing a systematic experiment to analyze the roles of the vision encoder and the language decoder in hallucination generation. Our observations reveal that object hallucinations are predominantly associated with the strong priors from the language decoder. Based on this finding, we propose a simple and training-free framework, No-Language-Hallucination Decoding, NoLan, which refines the output distribution by dynamically suppressing language priors, modulated based on the output distribution difference between multimodal and text-only inputs. Experimental results demonstrate that NoLan effectively reduces object hallucinations across various LVLMs on different tasks. For instance, NoLan achieves substantial improvements on POPE, enhancing the accuracy of LLaVA-1.5 7B and Qwen-VL 7B by up to 6.45 and 7.21, respectively. The code is publicly available at: https://github.com/lingfengren/NoLan.
Refinement Provenance Inference: Detecting LLM-Refined Training Prompts from Model Behavior
Jan 05, 2026Instruction tuning increasingly relies on LLM-based prompt refinement, where prompts in the training corpus are selectively rewritten by an external refiner to improve clarity and instruction alignment. This motivates an instance-level audit problem: for a fine-tuned model and a training prompt-response pair, can we infer whether the model was trained on the original prompt or its LLM-refined version within a mixed corpus? This matters for dataset governance and dispute resolution when training data are contested. However, it is non-trivial in practice: refined and raw instances are interleaved in the training corpus with unknown, source-dependent mixture ratios, making it harder to develop provenance methods that generalize across models and training setups. In this paper, we formalize this audit task as Refinement Provenance Inference (RPI) and show that prompt refinement yields stable, detectable shifts in teacher-forced token distributions, even when semantic differences are not obvious. Building on this phenomenon, we propose RePro, a logit-based provenance framework that fuses teacher-forced likelihood features with logit-ranking signals. During training, RePro learns a transferable representation via shadow fine-tuning, and uses a lightweight linear head to infer provenance on unseen victims without training-data access. Empirically, RePro consistently attains strong performance and transfers well across refiners, suggesting that it exploits refiner-agnostic distribution shifts rather than rewrite-style artifacts.
Discrete Diffusion in Large Language and Multimodal Models: A Survey
Jun 16, 2025In this work, we provide a systematic survey of Discrete Diffusion Language Models (dLLMs) and Discrete Diffusion Multimodal Language Models (dMLLMs). Unlike autoregressive (AR) models, dLLMs and dMLLMs adopt a multi-token, parallel decoding paradigm using full attention and a denoising-based generation strategy. This paradigm naturally enables parallel generation, fine-grained output controllability, and dynamic, response-aware perception. These capabilities are previously difficult to achieve with AR models. Recently, a growing number of industrial-scale proprietary d(M)LLMs, as well as a large number of open-source academic d(M)LLMs, have demonstrated performance comparable to their autoregressive counterparts, while achieving up to 10x acceleration in inference speed. The advancement of discrete diffusion LLMs and MLLMs has been largely driven by progress in two domains. The first is the development of autoregressive LLMs and MLLMs, which has accumulated vast amounts of data, benchmarks, and foundational infrastructure for training and inference. The second contributing domain is the evolution of the mathematical models underlying discrete diffusion. Together, these advancements have catalyzed a surge in dLLMs and dMLLMs research in early 2025. In this work, we present a comprehensive overview of the research in the dLLM and dMLLM domains. We trace the historical development of dLLMs and dMLLMs, formalize the underlying mathematical frameworks, and categorize representative models. We further analyze key techniques for training and inference, and summarize emerging applications across language, vision-language, and biological domains. We conclude by discussing future directions for research and deployment. Paper collection: https://github.com/LiQiiiii/DLLM-Survey
Dimple: Discrete Diffusion Multimodal Large Language Model with Parallel Decoding
May 22, 2025In this work, we propose Dimple, the first Discrete Diffusion Multimodal Large Language Model (DMLLM). We observe that training with a purely discrete diffusion approach leads to significant training instability, suboptimal performance, and severe length bias issues. To address these challenges, we design a novel training paradigm that combines an initial autoregressive phase with a subsequent diffusion phase. This approach yields the Dimple-7B model, trained on the same dataset and using a similar training pipeline as LLaVA-NEXT. Dimple-7B ultimately surpasses LLaVA-NEXT in performance by 3.9%, demonstrating that DMLLM can achieve performance comparable to that of autoregressive models. To improve inference efficiency, we propose a decoding strategy termed confident decoding, which dynamically adjusts the number of tokens generated at each step, significantly reducing the number of generation iterations. In autoregressive models, the number of forward iterations during generation equals the response length. With confident decoding, however, the number of iterations needed by Dimple is even only $\frac{\text{response length}}{3}$. We also re-implement the prefilling technique in autoregressive models and demonstrate that it does not significantly impact performance on most benchmark evaluations, while offering a speedup of 1.5x to 7x. Additionally, we explore Dimple's capability to precisely control its response using structure priors. These priors enable structured responses in a manner distinct from instruction-based or chain-of-thought prompting, and allow fine-grained control over response format and length, which is difficult to achieve in autoregressive models. Overall, this work validates the feasibility and advantages of DMLLM and enhances its inference efficiency and controllability. Code and models are available at https://github.com/yu-rp/Dimple.
dKV-Cache: The Cache for Diffusion Language Models
May 21, 2025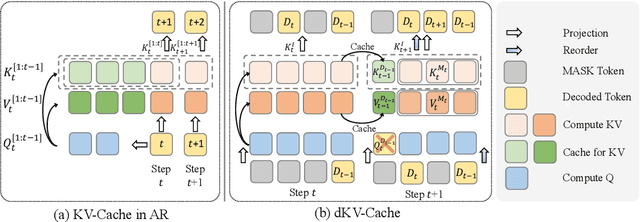
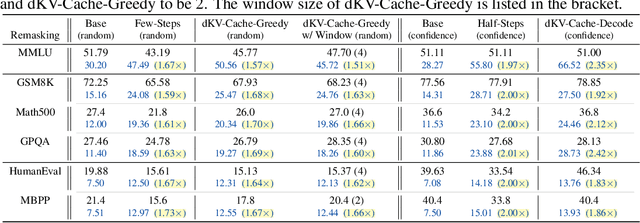
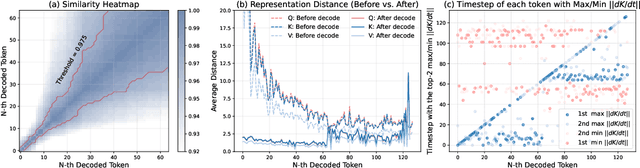
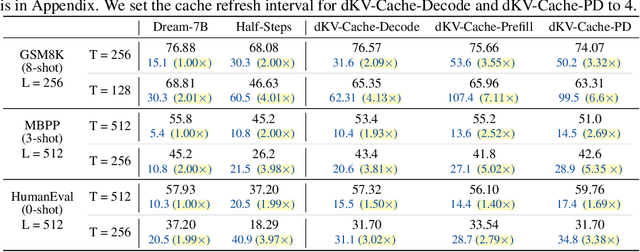
Diffusion Language Models (DLMs) have been seen as a promising competitor for autoregressive language models. However, diffusion language models have long been constrained by slow inference. A core challenge is that their non-autoregressive architecture and bidirectional attention preclude the key-value cache that accelerates decoding. We address this bottleneck by proposing a KV-cache-like mechanism, delayed KV-Cache, for the denoising process of DLMs. Our approach is motivated by the observation that different tokens have distinct representation dynamics throughout the diffusion process. Accordingly, we propose a delayed and conditioned caching strategy for key and value states. We design two complementary variants to cache key and value step-by-step: (1) dKV-Cache-Decode, which provides almost lossless acceleration, and even improves performance on long sequences, suggesting that existing DLMs may under-utilise contextual information during inference. (2) dKV-Cache-Greedy, which has aggressive caching with reduced lifespan, achieving higher speed-ups with quadratic time complexity at the cost of some performance degradation. dKV-Cache, in final, achieves from 2-10x speedup in inference, largely narrowing the gap between ARs and DLMs. We evaluate our dKV-Cache on several benchmarks, delivering acceleration across general language understanding, mathematical, and code-generation benchmarks. Experiments demonstrate that cache can also be used in DLMs, even in a training-free manner from current DLMs.
Multi-Level Collaboration in Model Merging
Mar 03, 2025Parameter-level model merging is an emerging paradigm in multi-task learning with significant promise. Previous research has explored its connections with prediction-level model ensembling-commonly viewed as the upper bound for merging-to reveal the potential of achieving performance consistency between the two. However, this observation relies on certain preconditions, such as being limited to two models, using ViT-based models, and all models are fine-tuned from the same pre-trained checkpoint. To further understand the intrinsic connections between model merging and model ensembling, this paper explores an interesting possibility: If these restrictions are removed, can performance consistency still be achieved between merging and ensembling? To answer this question, we first theoretically establish a performance correlation between merging and ensembling. We find that even when previous restrictions are not met, there is still a way for model merging to attain a near-identical and superior performance similar to that of ensembling. To verify whether our findings are practical, we introduce a validation framework termed Neural Ligand (NeuLig). The learning process of NeuLig is meticulously designed with a specialized loss function supported by theoretical foundations. Experimental results demonstrate the robust resilience of NeuLig in terms of both model scale and the number of collaborating models. For instance, for the case involving 5 CLIP-ViT-B/32 models, parameter-level merging achieves the same performance as prediction-level ensembling (merging: 95.44% vs. ensembling: 95.46%).
Introducing Visual Perception Token into Multimodal Large Language Model
Feb 24, 2025To utilize visual information, Multimodal Large Language Model (MLLM) relies on the perception process of its vision encoder. The completeness and accuracy of visual perception significantly influence the precision of spatial reasoning, fine-grained understanding, and other tasks. However, MLLM still lacks the autonomous capability to control its own visual perception processes, for example, selectively reviewing specific regions of an image or focusing on information related to specific object categories. In this work, we propose the concept of Visual Perception Token, aiming to empower MLLM with a mechanism to control its visual perception processes. We design two types of Visual Perception Tokens, termed the Region Selection Token and the Vision Re-Encoding Token. MLLMs autonomously generate these tokens, just as they generate text, and use them to trigger additional visual perception actions. The Region Selection Token explicitly identifies specific regions in an image that require further perception, while the Vision Re-Encoding Token uses its hidden states as control signals to guide additional visual perception processes. Extensive experiments demonstrate the advantages of these tokens in handling spatial reasoning, improving fine-grained understanding, and other tasks. On average, the introduction of Visual Perception Tokens improves the performance of a 2B model by 23.6\%, increasing its score from 0.572 to 0.708, and even outperforms a 7B parameter model by 13.4\% (from 0.624). Please check out our repo https://github.com/yu-rp/VisualPerceptionToken
CoT-Valve: Length-Compressible Chain-of-Thought Tuning
Feb 13, 2025



Chain-of-Thought significantly enhances a model's reasoning capability, but it also comes with a considerable increase in inference costs due to long chains. With the observation that the reasoning path can be easily compressed under easy tasks but struggle on hard tasks, we explore the feasibility of elastically controlling the length of reasoning paths with only one model, thereby reducing the inference overhead of reasoning models dynamically based on task difficulty. We introduce a new tuning and inference strategy named CoT-Valve, designed to allow models to generate reasoning chains of varying lengths. To achieve this, we propose to identify a direction in the parameter space that, when manipulated, can effectively control the length of generated CoT. Moreover, we show that this property is valuable for compressing the reasoning chain. We construct datasets with chains from long to short for the same questions and explore two enhanced strategies for CoT-Valve: (1) a precise length-compressible CoT tuning method, and (2) a progressive chain length compression approach. Our experiments show that CoT-Valve successfully enables controllability and compressibility of the chain and shows better performance than the prompt-based control. We applied this method to QwQ-32B-Preview, reducing reasoning chains on GSM8K from 741 to 225 tokens with a minor performance drop (95.07% to 94.92%) and on AIME from 6827 to 4629 tokens, with only one additional incorrect answer.
Revisiting Self-Supervised Heterogeneous Graph Learning from Spectral Clustering Perspective
Dec 01, 2024



Self-supervised heterogeneous graph learning (SHGL) has shown promising potential in diverse scenarios. However, while existing SHGL methods share a similar essential with clustering approaches, they encounter two significant limitations: (i) noise in graph structures is often introduced during the message-passing process to weaken node representations, and (ii) cluster-level information may be inadequately captured and leveraged, diminishing the performance in downstream tasks. In this paper, we address these limitations by theoretically revisiting SHGL from the spectral clustering perspective and introducing a novel framework enhanced by rank and dual consistency constraints. Specifically, our framework incorporates a rank-constrained spectral clustering method that refines the affinity matrix to exclude noise effectively. Additionally, we integrate node-level and cluster-level consistency constraints that concurrently capture invariant and clustering information to facilitate learning in downstream tasks. We theoretically demonstrate that the learned representations are divided into distinct partitions based on the number of classes and exhibit enhanced generalization ability across tasks. Experimental results affirm the superiority of our method, showcasing remarkable improvements in several downstream tasks compared to existing methods.