 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Image Quality Assessment Ability of LMMs via Retrieval-Augmented Generation
Jan 13, 2026Large Multimodal Models (LMMs) have recently shown remarkable promise in low-level visual perception tasks, particularly in Image Quality Assessment (IQA), demonstrating strong zero-shot capability. However, achieving state-of-the-art performance often requires computationally expensive fine-tuning methods, which aim to align the distribution of quality-related token in output with image quality levels. Inspired by recent training-free works for LMM, we introduce IQARAG, a novel, training-free framework that enhances LMMs' IQA ability. IQARAG leverages Retrieval-Augmented Generation (RAG) to retrieve some semantically similar but quality-variant reference images with corresponding Mean Opinion Scores (MOSs) for input image. These retrieved images and input image are integrated into a specific prompt. Retrieved images provide the LMM with a visual perception anchor for IQA task. IQARAG contains three key phases: Retrieval Feature Extraction, Image Retrieval, and Integration & Quality Score Generation. Extensive experiments across multiple diverse IQA datasets, including KADID, KonIQ, LIVE Challenge, and SPAQ, demonstrate that the proposed IQARAG effectively boosts the IQA performance of LMMs, offering a resource-efficient alternative to fine-tuning for quality assessment.
VTONQA: A Multi-Dimensional Quality Assessment Dataset for Virtual Try-on
Jan 06, 2026With the rapid development of e-commerce and digital fashion, image-based virtual try-on (VTON) has attracted increasing attention. However, existing VTON models often suffer from artifacts such as garment distortion and body inconsistency, highlighting the need for reliable quality evaluation of VTON-generated images. To this end, we construct VTONQA, the first multi-dimensional quality assessment dataset specifically designed for VTON, which contains 8,132 images generated by 11 representative VTON models, along with 24,396 mean opinion scores (MOSs) across three evaluation dimensions (i.e., clothing fit, body compatibility, and overall quality). Based on VTONQA, we benchmark both VTON models and a diverse set of image quality assessment (IQA) metrics, revealing the limitations of existing methods and highlighting the value of the proposed dataset. We believe that the VTONQA dataset and corresponding benchmarks will provide a solid foundation for perceptually aligned evaluation, benefiting both the development of quality assessment methods and the advancement of VTON models.
Generative Human-Object Interaction Detection via Differentiable Cognitive Steering of Multi-modal LLMs
Dec 19, 2025



Human-object interaction (HOI) detection aims to localize human-object pairs and the interactions between them. Existing methods operate under a closed-world assumption, treating the task as a classification problem over a small, predefined verb set, which struggles to generalize to the long-tail of unseen or ambiguous interactions in the wild. While recent multi-modal large language models (MLLMs) possess the rich world knowledge required for open-vocabulary understanding, they remain decoupled from existing HOI detectors since fine-tuning them is computationally prohibitive. To address these constraints, we propose \GRASP-HO}, a novel Generative Reasoning And Steerable Perception framework that reformulates HOI detection from the closed-set classification task to the open-vocabulary generation problem. To bridge the vision and cognitive, we first extract hybrid interaction representations, then design a lightweight learnable cognitive steering conduit (CSC) module to inject the fine-grained visual evidence into a frozen MLLM for effective reasoning. To address the supervision mismatch between classification-based HOI datasets and open-vocabulary generative models, we introduce a hybrid guidance strategy that coupling the language modeling loss and auxiliary classification loss, enabling discriminative grounding without sacrificing generative flexibility. Experiments demonstrate state-of-the-art closed-set performance and strong zero-shot generalization, achieving a unified paradigm that seamlessly bridges discriminative perception and generative reasoning for open-world HOI detection.
ManipShield: A Unified Framework for Image Manipulation Detection, Localization and Explanation
Nov 18, 2025



With the rapid advancement of generative models, powerful image editing methods now enable diverse and highly realistic image manipulations that far surpass traditional deepfake techniques, posing new challenges for manipulation detection. Existing image manipulation detection and localization (IMDL) benchmarks suffer from limited content diversity, narrow generative-model coverage, and insufficient interpretability, which hinders the generalization and explanation capabilities of current manipulation detection methods. To address these limitations, we introduce \textbf{ManipBench}, a large-scale benchmark for image manipulation detection and localization focusing on AI-edited images. ManipBench contains over 450K manipulated images produced by 25 state-of-the-art image editing models across 12 manipulation categories, among which 100K images are further annotated with bounding boxes, judgment cues, and textual explanations to support interpretable detection. Building upon ManipBench, we propose \textbf{ManipShield}, an all-in-one model based on a Multimodal Large Language Model (MLLM) that leverages contrastive LoRA fine-tuning and task-specific decoders to achieve unified image manipulation detection, localization, and explanation. Extensive experiments on ManipBench and several public datasets demonstrate that ManipShield achieves state-of-the-art performance and exhibits strong generality to unseen manipulation models. Both ManipBench and ManipShield will be released upon publication.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
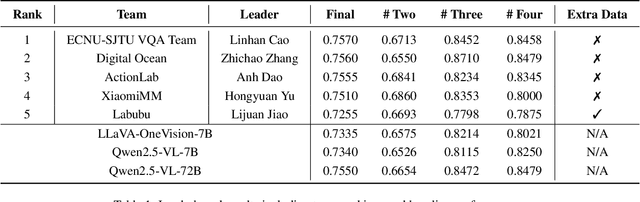
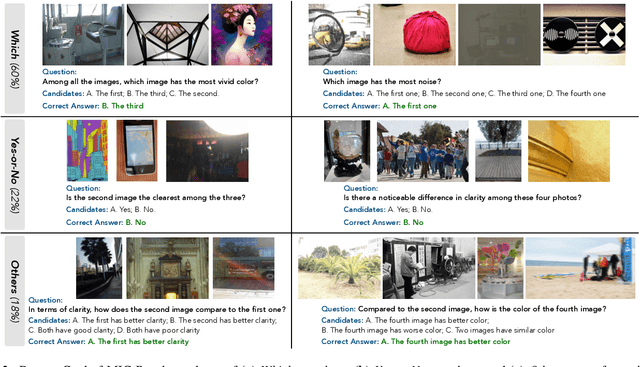
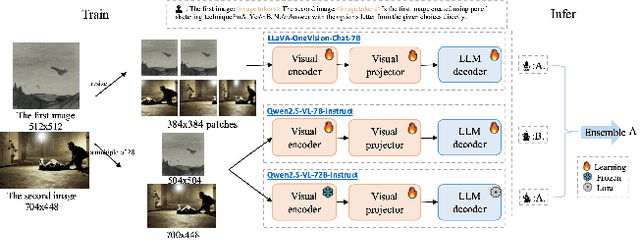
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.
Audio-Assisted Face Video Restoration with Temporal and Identity Complementary Learning
Aug 06, 2025



Face videos accompanied by audio have become integral to our daily lives, while they often suffer from complex degradations. Most face video restoration methods neglect the intrinsic correlations between the visual and audio features, especially in mouth regions. A few audio-aided face video restoration methods have been proposed, but they only focus on compression artifact removal. In this paper, we propose a General Audio-assisted face Video restoration Network (GAVN) to address various types of streaming video distortions via identity and temporal complementary learning. Specifically, GAVN first captures inter-frame temporal features in the low-resolution space to restore frames coarsely and save computational cost. Then, GAVN extracts intra-frame identity features in the high-resolution space with the assistance of audio signals and face landmarks to restore more facial details. Finally, the reconstruction module integrates temporal features and identity features to generate high-quality face videos. Experimental results demonstrate that GAVN outperforms the existing state-of-the-art methods on face video compression artifact removal, deblurring, and super-resolution. Codes will be released upon publication.
CompressedVQA-HDR: Generalized Full-reference and No-reference Quality Assessment Models for Compressed High Dynamic Range Videos
Jul 16, 2025Video compression is a standard procedure applied to all videos to minimize storage and transmission demands while preserving visual quality as much as possible. Therefore, evaluating the visual quality of compressed videos is crucial for guiding the practical usage and further development of video compression algorithms. Although numerous compressed video quality assessment (VQA) methods have been proposed, they often lack the generalization capability needed to handle the increasing diversity of video types, particularly high dynamic range (HDR) content. In this paper, we introduce CompressedVQA-HDR, an effective VQA framework designed to address the challenges of HDR video quality assessment. Specifically, we adopt the Swin Transformer and SigLip 2 as the backbone networks for the proposed full-reference (FR) and no-reference (NR) VQA models, respectively. For the FR model, we compute deep structural and textural similarities between reference and distorted frames using intermediate-layer features extracted from the Swin Transformer as its quality-aware feature representation. For the NR model, we extract the global mean of the final-layer feature maps from SigLip 2 as its quality-aware representation. To mitigate the issue of limited HDR training data, we pre-train the FR model on a large-scale standard dynamic range (SDR) VQA dataset and fine-tune it on the HDRSDR-VQA dataset. For the NR model, we employ an iterative mixed-dataset training strategy across multiple compressed VQA datasets, followed by fine-tuning on the HDRSDR-VQA dataset. Experimental results show that our models achieve state-of-the-art performance compared to existing FR and NR VQA models. Moreover, CompressedVQA-HDR-FR won first place in the FR track of the Generalizable HDR & SDR Video Quality Measurement Grand Challenge at IEEE ICME 2025. The code is available at https://github.com/sunwei925/CompressedVQA-HDR.
Scaling-up Perceptual Video Quality Assessment
May 28, 2025The data scaling law has been shown to significantly enhance the performance of large multi-modal models (LMMs) across various downstream tasks. However, in the domain of perceptual video quality assessment (VQA), the potential of scaling law remains unprecedented due to the scarcity of labeled resources and the insufficient scale of datasets. To address this, we propose \textbf{OmniVQA}, an efficient framework designed to efficiently build high-quality, human-in-the-loop VQA multi-modal instruction databases (MIDBs). We then scale up to create \textbf{OmniVQA-Chat-400K}, the largest MIDB in the VQA field concurrently. Our focus is on the technical and aesthetic quality dimensions, with abundant in-context instruction data to provide fine-grained VQA knowledge. Additionally, we have built the \textbf{OmniVQA-MOS-20K} dataset to enhance the model's quantitative quality rating capabilities. We then introduce a \textbf{complementary} training strategy that effectively leverages the knowledge from datasets for quality understanding and quality rating tasks. Furthermore, we propose the \textbf{OmniVQA-FG (fine-grain)-Benchmark} to evaluate the fine-grained performance of the models. Our results demonstrate that our models achieve state-of-the-art performance in both quality understanding and rating tasks.
TDVE-Assessor: Benchmarking and Evaluating the Quality of Text-Driven Video Editing with LMMs
May 26, 2025Text-driven video editing is rapidly advancing, yet its rigorous evaluation remains challenging due to the absence of dedicated video quality assessment (VQA) models capable of discerning the nuances of editing quality. To address this critical gap, we introduce TDVE-DB, a large-scale benchmark dataset for text-driven video editing. TDVE-DB consists of 3,857 edited videos generated from 12 diverse models across 8 editing categories, and is annotated with 173,565 human subjective ratings along three crucial dimensions, i.e., edited video quality, editing alignment, and structural consistency. Based on TDVE-DB, we first conduct a comprehensive evaluation for the 12 state-of-the-art editing models revealing the strengths and weaknesses of current video techniques, and then benchmark existing VQA methods in the context of text-driven video editing evaluation. Building on these insights, we propose TDVE-Assessor, a novel VQA model specifically designed for text-driven video editing assessment. TDVE-Assessor integrates both spatial and temporal video features into a large language model (LLM) for rich contextual understanding to provide comprehensive quality assessment. Extensive experiments demonstrate that TDVE-Assessor substantially outperforms existing VQA models on TDVE-DB across all three evaluation dimensions, setting a new state-of-the-art. Both TDVE-DB and TDVE-Assessor will be released upon the publication.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.