 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarket-Bench: Benchmarking Large Language Models on Economic and Trade Competition
Apr 07, 2026The ability of large language models (LLMs) to manage and acquire economic resources remains unclear. In this paper, we introduce \textbf{Market-Bench}, a comprehensive benchmark that evaluates the capabilities of LLMs in economically-relevant tasks through economic and trade competition. Specifically, we construct a configurable multi-agent supply chain economic model where LLMs act as retailer agents responsible for procuring and retailing merchandise. In the \textbf{procurement} stage, LLMs bid for limited inventory in budget-constrained auctions. In the \textbf{retail} stage, LLMs set retail prices, generate marketing slogans, and provide them to buyers through a role-based attention mechanism for purchase. Market-Bench logs complete trajectories of bids, prices, slogans, sales, and balance-sheet states, enabling automatic evaluation with economic, operational, and semantic metrics. Benchmarking on 20 open- and closed-source LLM agents reveals significant performance disparities and winner-take-most phenomenon, \textit{i.e.}, only a small subset of LLM retailers can consistently achieve capital appreciation, while many hover around the break-even point despite similar semantic matching scores. Market-Bench provides a reproducible testbed for studying how LLMs interact in competitive markets.
Generative Inverse Design of Cold Metals for Low-Power Electronics
Mar 14, 2026Cold metals are a class of metals with an intrinsic energy gap located close to the Fermi level, which enables cold-carrier injection for steep-slope transistors and is therefore promising for low-power electronic applications. High-throughput screening has revealed 252 three-dimensional (3D) cold metals in the Materials Project database, but database searches are inherently limited to known compounds. Here we present an inverse-design workflow that generates 3D cold metals using MatterGPT, a conditional autoregressive Transformer trained on SLICES, an invertible and symmetry-invariant crystal string representation. We curate a training set of 26,309 metallic structures labeled with energy above hull and a unified band-edge distance descriptor that merges p-type and n-type cold-metal characteristics to address severe label imbalance. Property-conditioned generation targeting thermodynamic stability and 50-500 meV band-edge distances produces 148,506 unique candidates; 92.1% are successfully reconstructed to 3D structures and down-selected by symmetry, uniqueness and novelty filters, followed by high-throughput DFT validation. We identify 257 cold metals verified as novel with respect to the Materials Project database, with gaps around the Fermi level spanning 50-500 meV. First-principles phonon, electronic-structure, and work-function calculations for representative candidates confirm dynamical stability and contact-relevant work functions. Our results demonstrate that SLICES-enabled generative transformers can expand the chemical space of cold metals beyond high-throughput screening, providing a route to low-power electronic materials discovery.
LifeEval: A Multimodal Benchmark for Assistive AI in Egocentric Daily Life Tasks
Feb 28, 2026The rapid progress of Multimodal Large Language Models (MLLMs) marks a significant step toward artificial general intelligence, offering great potential for augmenting human capabilities. However, their ability to provide effective assistance in dynamic, real-world environments remains largely underexplored. Existing video benchmarks predominantly assess passive understanding through retrospective analysis or isolated perception tasks, failing to capture the interactive and adaptive nature of real-time user assistance. To bridge this gap, we introduce LifeEval, a multimodal benchmark designed to evaluate real-time, task-oriented human-AI collaboration in daily life from an egocentric perspective. LifeEval emphasizes three key aspects: task-oriented holistic evaluation, egocentric real-time perception from continuous first-person streams, and human-assistant collaborative interaction through natural dialogues. Constructed via a rigorous annotation pipeline, the benchmark comprises 4,075 high-quality question-answer pairs across 6 core capability dimensions. Extensive evaluations of 26 state-of-the-art MLLMs on LifeEval reveal substantial challenges in achieving timely, effective and adaptive interaction, highlighting essential directions for advancing human-centered interactive intelligence.
Enhancing Image Quality Assessment Ability of LMMs via Retrieval-Augmented Generation
Jan 13, 2026Large Multimodal Models (LMMs) have recently shown remarkable promise in low-level visual perception tasks, particularly in Image Quality Assessment (IQA), demonstrating strong zero-shot capability. However, achieving state-of-the-art performance often requires computationally expensive fine-tuning methods, which aim to align the distribution of quality-related token in output with image quality levels. Inspired by recent training-free works for LMM, we introduce IQARAG, a novel, training-free framework that enhances LMMs' IQA ability. IQARAG leverages Retrieval-Augmented Generation (RAG) to retrieve some semantically similar but quality-variant reference images with corresponding Mean Opinion Scores (MOSs) for input image. These retrieved images and input image are integrated into a specific prompt. Retrieved images provide the LMM with a visual perception anchor for IQA task. IQARAG contains three key phases: Retrieval Feature Extraction, Image Retrieval, and Integration & Quality Score Generation. Extensive experiments across multiple diverse IQA datasets, including KADID, KonIQ, LIVE Challenge, and SPAQ, demonstrate that the proposed IQARAG effectively boosts the IQA performance of LMMs, offering a resource-efficient alternative to fine-tuning for quality assessment.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
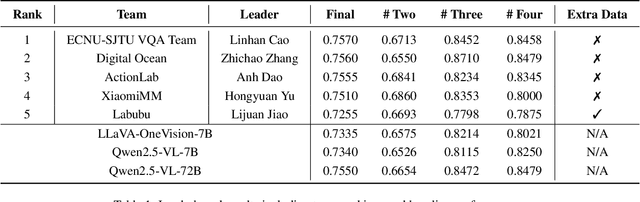
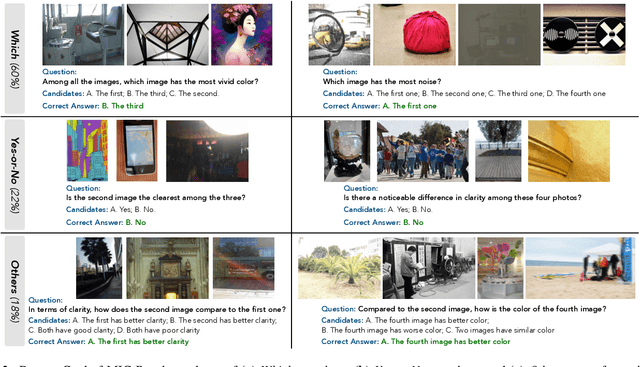
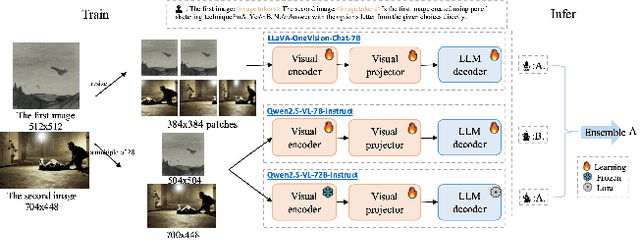
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.
Can Large Models Fool the Eye? A New Turing Test for Biological Animation
Aug 08, 2025Evaluating the abilities of large models and manifesting their gaps are challenging. Current benchmarks adopt either ground-truth-based score-form evaluation on static datasets or indistinct textual chatbot-style human preferences collection, which may not provide users with immediate, intuitive, and perceptible feedback on performance differences. In this paper, we introduce BioMotion Arena, a novel framework for evaluating large language models (LLMs) and multimodal large language models (MLLMs) via visual animation. Our methodology draws inspiration from the inherent visual perception of motion patterns characteristic of living organisms that utilizes point-light source imaging to amplify the performance discrepancies between models. Specifically, we employ a pairwise comparison evaluation and collect more than 45k votes for 53 mainstream LLMs and MLLMs on 90 biological motion variants. Data analyses show that the crowd-sourced human votes are in good agreement with those of expert raters, demonstrating the superiority of our BioMotion Arena in offering discriminative feedback. We also find that over 90\% of evaluated models, including the cutting-edge open-source InternVL3 and proprietary Claude-4 series, fail to produce fundamental humanoid point-light groups, much less smooth and biologically plausible motions. This enables BioMotion Arena to serve as a challenging benchmark for performance visualization and a flexible evaluation framework without restrictions on ground-truth.
AGHI-QA: A Subjective-Aligned Dataset and Metric for AI-Generated Human Images
Apr 30, 2025



The rapid development of text-to-image (T2I) generation approaches has attracted extensive interest in evaluating the quality of generated images, leading to the development of various quality assessment methods for general-purpose T2I outputs. However, existing image quality assessment (IQA) methods are limited to providing global quality scores, failing to deliver fine-grained perceptual evaluations for structurally complex subjects like humans, which is a critical challenge considering the frequent anatomical and textural distortions in AI-generated human images (AGHIs). To address this gap, we introduce AGHI-QA, the first large-scale benchmark specifically designed for quality assessment of AGHIs. The dataset comprises 4,000 images generated from 400 carefully crafted text prompts using 10 state of-the-art T2I models. We conduct a systematic subjective study to collect multidimensional annotations, including perceptual quality scores, text-image correspondence scores, visible and distorted body part labels. Based on AGHI-QA, we evaluate the strengths and weaknesses of current T2I methods in generating human images from multiple dimensions. Furthermore, we propose AGHI-Assessor, a novel quality metric that integrates the large multimodal model (LMM) with domain-specific human features for precise quality prediction and identification of visible and distorted body parts in AGHIs. Extensive experimental results demonstrate that AGHI-Assessor showcases state-of-the-art performance, significantly outperforming existing IQA methods in multidimensional quality assessment and surpassing leading LMMs in detecting structural distortions in AGHIs.
Omni$^2$: Unifying Omnidirectional Image Generation and Editing in an Omni Model
Apr 15, 2025$360^{\circ}$ omnidirectional images (ODIs) have gained considerable attention recently, and are widely used in various virtual reality (VR) and augmented reality (AR) applications. However, capturing such images is expensive and requires specialized equipment, making ODI synthesis increasingly important. While common 2D image generation and editing methods are rapidly advancing, these models struggle to deliver satisfactory results when generating or editing ODIs due to the unique format and broad 360$^{\circ}$ Field-of-View (FoV) of ODIs. To bridge this gap, we construct \textbf{\textit{Any2Omni}}, the first comprehensive ODI generation-editing dataset comprises 60,000+ training data covering diverse input conditions and up to 9 ODI generation and editing tasks. Built upon Any2Omni, we propose an \textbf{\underline{Omni}} model for \textbf{\underline{Omni}}-directional image generation and editing (\textbf{\textit{Omni$^2$}}), with the capability of handling various ODI generation and editing tasks under diverse input conditions using one model. Extensive experiments demonstrate the superiority and effectiveness of the proposed Omni$^2$ model for both the ODI generation and editing tasks.
ESVQA: Perceptual Quality Assessment of Egocentric Spatial Videos
Dec 29, 2024



With the rapid development of eXtended Reality (XR), egocentric spatial shooting and display technologies have further enhanced immersion and engagement for users. Assessing the quality of experience (QoE) of egocentric spatial videos is crucial to ensure a high-quality viewing experience. However, the corresponding research is still lacking. In this paper, we use the embodied experience to highlight this more immersive experience and study the new problem, i.e., embodied perceptual quality assessment for egocentric spatial videos. Specifically, we introduce the first Egocentric Spatial Video Quality Assessment Database (ESVQAD), which comprises 600 egocentric spatial videos and their mean opinion scores (MOSs). Furthermore, we propose a novel multi-dimensional binocular feature fusion model, termed ESVQAnet, which integrates binocular spatial, motion, and semantic features to predict the perceptual quality. Experimental results demonstrate the ESVQAnet outperforms 16 state-of-the-art VQA models on the embodied perceptual quality assessment task, and exhibits strong generalization capability on traditional VQA tasks. The database and codes will be released upon the publication.
How Does Audio Influence Visual Attention in Omnidirectional Videos? Database and Model
Aug 10, 2024



Understanding and predicting viewer attention in omnidirectional videos (ODVs) is crucial for enhancing user engagement in virtual and augmented reality applications. Although both audio and visual modalities are essential for saliency prediction in ODVs, the joint exploitation of these two modalities has been limited, primarily due to the absence of large-scale audio-visual saliency databases and comprehensive analyses. This paper comprehensively investigates audio-visual attention in ODVs from both subjective and objective perspectives. Specifically, we first introduce a new audio-visual saliency database for omnidirectional videos, termed AVS-ODV database, containing 162 ODVs and corresponding eye movement data collected from 60 subjects under three audio modes including mute, mono, and ambisonics. Based on the constructed AVS-ODV database, we perform an in-depth analysis of how audio influences visual attention in ODVs. To advance the research on audio-visual saliency prediction for ODVs, we further establish a new benchmark based on the AVS-ODV database by testing numerous state-of-the-art saliency models, including visual-only models and audio-visual models. In addition, given the limitations of current models, we propose an innovative omnidirectional audio-visual saliency prediction network (OmniAVS), which is built based on the U-Net architecture, and hierarchically fuses audio and visual features from the multimodal aligned embedding space. Extensive experimental results demonstrate that the proposed OmniAVS model outperforms other state-of-the-art models on both ODV AVS prediction and traditional AVS predcition tasks. The AVS-ODV database and OmniAVS model will be released to facilitate future research.