 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaymax: An Accelerated, Data-Driven Simulator for Large-Scale Autonomous Driving Research
Oct 12, 2023



Simulation is an essential tool to develop and benchmark autonomous vehicle planning software in a safe and cost-effective manner. However, realistic simulation requires accurate modeling of nuanced and complex multi-agent interactive behaviors. To address these challenges, we introduce Waymax, a new data-driven simulator for autonomous driving in multi-agent scenes, designed for large-scale simulation and testing. Waymax uses publicly-released, real-world driving data (e.g., the Waymo Open Motion Dataset) to initialize or play back a diverse set of multi-agent simulated scenarios. It runs entirely on hardware accelerators such as TPUs/GPUs and supports in-graph simulation for training, making it suitable for modern large-scale, distributed machine learning workflows. To support online training and evaluation, Waymax includes several learned and hard-coded behavior models that allow for realistic interaction within simulation. To supplement Waymax, we benchmark a suite of popular imitation and reinforcement learning algorithms with ablation studies on different design decisions, where we highlight the effectiveness of routes as guidance for planning agents and the ability of RL to overfit against simulated agents.
Generalized Diffusion MRI Denoising and Super-Resolution using Swin Transformers
Mar 10, 2023Diffusion MRI is a non-invasive, in-vivo medical imaging method able to map tissue microstructure and structural connectivity of the human brain, as well as detect changes, such as brain development and injury, not visible by other clinical neuroimaging techniques. However, acquiring high signal-to-noise ratio (SNR) datasets with high angular and spatial sampling requires prohibitively long scan times, limiting usage in many important clinical settings, especially children, the elderly, and emergency patients with acute neurological disorders who might not be able to cooperate with the MRI scan without conscious sedation or general anesthesia. Here, we propose to use a Swin UNEt TRansformers (Swin UNETR) model, trained on augmented Human Connectome Project (HCP) data and conditioned on registered T1 scans, to perform generalized denoising and super-resolution of diffusion MRI invariant to acquisition parameters, patient populations, scanners, and sites. We qualitatively demonstrate super-resolution with artificially downsampled HCP data in normal adult volunteers. Our experiments on two other unrelated datasets, one of children with neurodevelopmental disorders and one of traumatic brain injury patients, show that our method demonstrates superior denoising despite wide data distribution shifts. Further improvement can be achieved via finetuning with just one additional subject. We apply our model to diffusion tensor (2nd order spherical harmonic) and higher-order spherical harmonic coefficient estimation and show results superior to current state-of-the-art methods. Our method can be used out-of-the-box or minimally finetuned to denoise and super-resolve a wide variety of diffusion MRI datasets. The code and model are publicly available at https://github.com/ucsfncl/dmri-swin.
Imitation Is Not Enough: Robustifying Imitation with Reinforcement Learning for Challenging Driving Scenarios
Dec 21, 2022



Imitation learning (IL) is a simple and powerful way to use high-quality human driving data, which can be collected at scale, to identify driving preferences and produce human-like behavior. However, policies based on imitation learning alone often fail to sufficiently account for safety and reliability concerns. In this paper, we show how imitation learning combined with reinforcement learning using simple rewards can substantially improve the safety and reliability of driving policies over those learned from imitation alone. In particular, we use a combination of imitation and reinforcement learning to train a policy on over 100k miles of urban driving data, and measure its effectiveness in test scenarios grouped by different levels of collision risk. To our knowledge, this is the first application of a combined imitation and reinforcement learning approach in autonomous driving that utilizes large amounts of real-world human driving data.
Deep Reinforcement Learning in a Monetary Model
Apr 19, 2021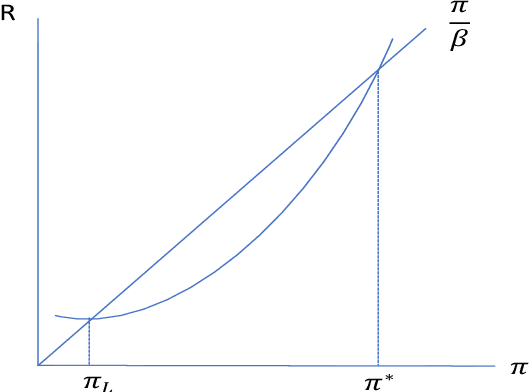
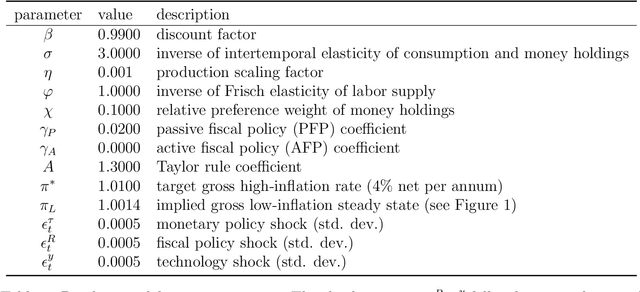
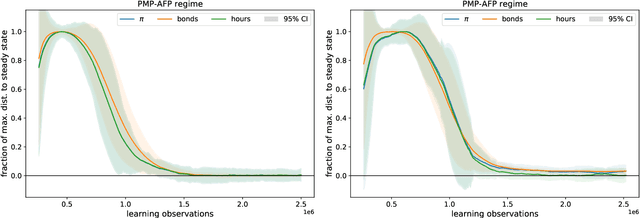
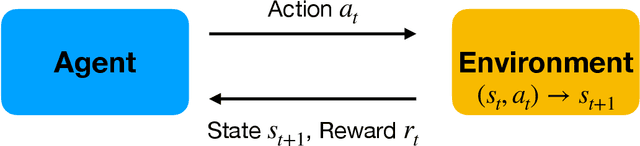
We propose using deep reinforcement learning to solve dynamic stochastic general equilibrium models. Agents are represented by deep artificial neural networks and learn to solve their dynamic optimisation problem by interacting with the model environment, of which they have no a priori knowledge. Deep reinforcement learning offers a flexible yet principled way to model bounded rationality within this general class of models. We apply our proposed approach to a classical model from the adaptive learning literature in macroeconomics which looks at the interaction of monetary and fiscal policy. We find that, contrary to adaptive learning, the artificially intelligent household can solve the model in all policy regimes.
Emergent Hand Morphology and Control from Optimizing Robust Grasps of Diverse Objects
Dec 22, 2020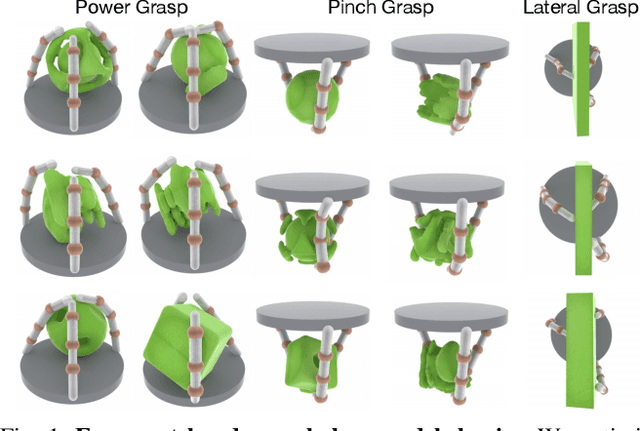
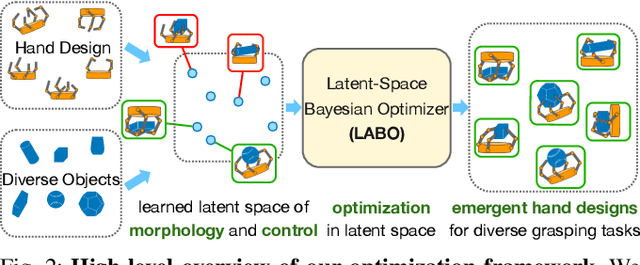
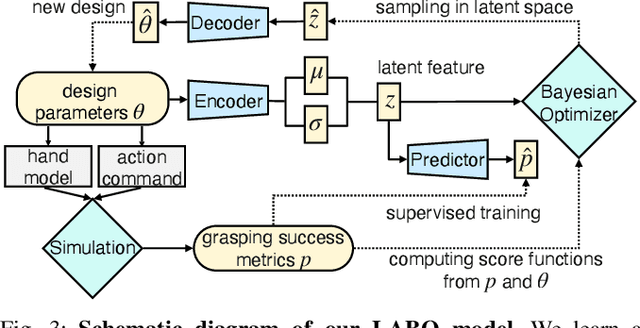
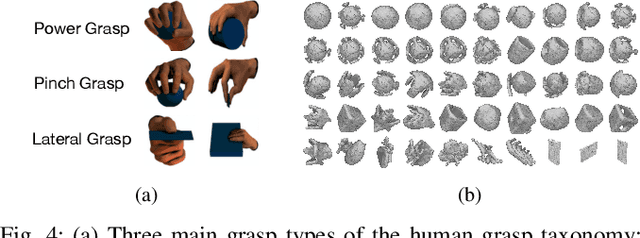
Evolution in nature illustrates that the creatures' biological structure and their sensorimotor skills adapt to the environmental changes for survival. Likewise, the ability to morph and acquire new skills can facilitate an embodied agent to solve tasks of varying complexities. In this work, we introduce a data-driven approach where effective hand designs naturally emerge for the purpose of grasping diverse objects. Jointly optimizing morphology and control imposes computational challenges since it requires constant evaluation of a black-box function that measures the performance of a combination of embodiment and behavior. We develop a novel Bayesian Optimization algorithm that efficiently co-designs the morphology and grasping skills jointly through learned latent-space representations. We design the grasping tasks based on a taxonomy of three human grasp types: power grasp, pinch grasp, and lateral grasp. Through experimentation and comparative study, we demonstrate the effectiveness of our approach in discovering robust and cost-efficient hand morphologies for grasping novel objects.
Zero-shot Imitation Learning from Demonstrations for Legged Robot Visual Navigation
Sep 27, 2019
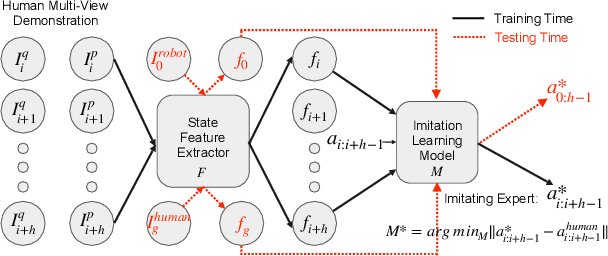
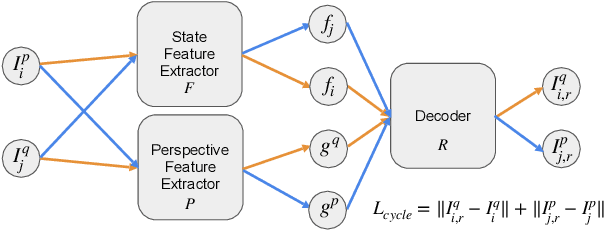
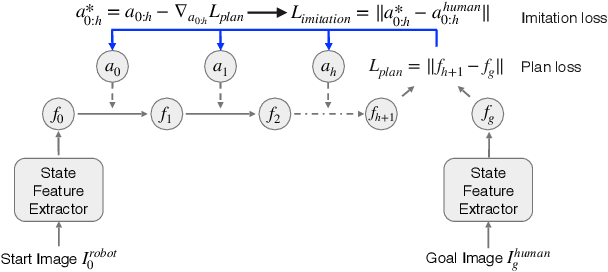
Imitation learning is a popular approach for training effective visual navigation policies. However, for legged robots collecting expert demonstrations is challenging as these robotic systems can be hard to control, move slowly, and cannot operate continuously for long periods of time. In this work, we propose a zero-shot imitation learning framework for training a visual navigation policy on a legged robot from only human demonstration (third-person perspective), allowing for high-quality navigation and cost-effective data collection. However, imitation learning from third-person perspective demonstrations raises unique challenges. First, these human demonstrations are captured from different camera perspectives, which we address via a feature disentanglement network~(FDN) that extracts perspective-agnostic state features. Second, as potential actions vary between systems, we reconstruct missing action labels by either building an inverse model of the robot's dynamics in the feature space and applying it to the demonstrations or developing an efficient Graphic User Interface (GUI) to label human demonstrations. To train a visual navigation policy we use a model-based imitation learning approach with the perspective-agnostic FDN and action-labeled demonstrations. We show that our framework can learn an effective policy for a legged robot, Laikago, from expert demonstrations in both simulated and real-world environments. Our approach is zero-shot as the robot never tries to navigate a given navigation path in the testing environment before the testing phase. We also justify our framework by performing an ablation study and comparing it with baselines.
Characterizing Attacks on Deep Reinforcement Learning
Jul 24, 2019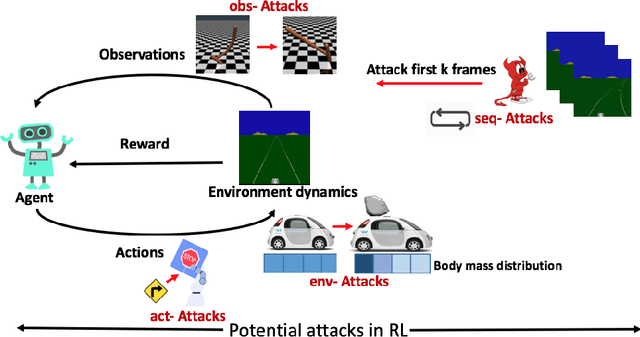
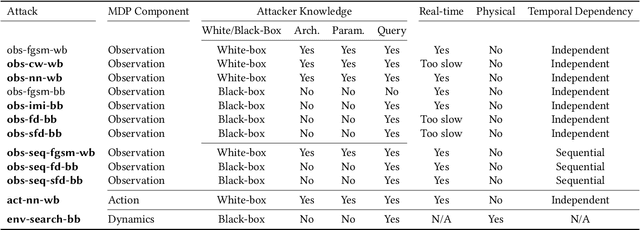

Deep reinforcement learning (DRL) has achieved great success in various applications. However, recent studies show that machine learning models are vulnerable to adversarial attacks. DRL models have been attacked by adding perturbations to observations. While such observation based attack is only one aspect of potential attacks on DRL, other forms of attacks which are more practical require further analysis, such as manipulating environment dynamics. Therefore, we propose to understand the vulnerabilities of DRL from various perspectives and provide a thorough taxonomy of potential attacks. We conduct the first set of experiments on the unexplored parts within the taxonomy. In addition to current observation based attacks against DRL, we propose the first targeted attacks based on action space and environment dynamics. We also introduce the online sequential attacks based on temporal consistency information among frames. To better estimate gradient in black-box setting, we propose a sampling strategy and theoretically prove its efficiency and estimation error bound. We conduct extensive experiments to compare the effectiveness of different attacks with several baselines in various environments, including game playing, robotics control, and autonomous driving.
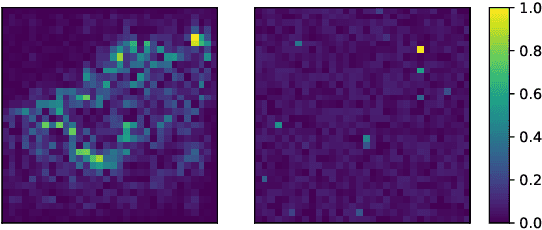
How You Act Tells a Lot: Privacy-Leakage Attack on Deep Reinforcement Learning
Apr 24, 2019
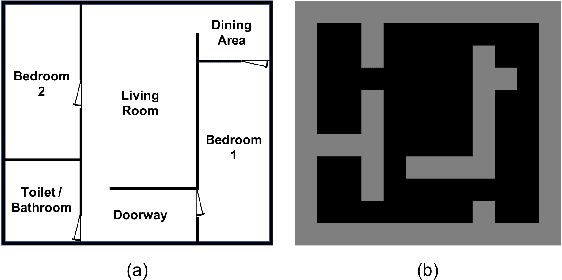
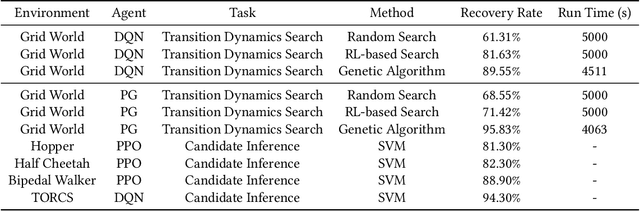
Machine learning has been widely applied to various applications, some of which involve training with privacy-sensitive data. A modest number of data breaches have been studied, including credit card information in natural language data and identities from face dataset. However, most of these studies focus on supervised learning models. As deep reinforcement learning (DRL) has been deployed in a number of real-world systems, such as indoor robot navigation, whether trained DRL policies can leak private information requires in-depth study. To explore such privacy breaches in general, we mainly propose two methods: environment dynamics search via genetic algorithm and candidate inference based on shadow policies. We conduct extensive experiments to demonstrate such privacy vulnerabilities in DRL under various settings. We leverage the proposed algorithms to infer floor plans from some trained Grid World navigation DRL agents with LiDAR perception. The proposed algorithm can correctly infer most of the floor plans and reaches an average recovery rate of 95.83% using policy gradient trained agents. In addition, we are able to recover the robot configuration in continuous control environments and an autonomous driving simulator with high accuracy. To the best of our knowledge, this is the first work to investigate privacy leakage in DRL settings and we show that DRL-based agents do potentially leak privacy-sensitive information from the trained policies.
Risk Averse Robust Adversarial Reinforcement Learning
Mar 31, 2019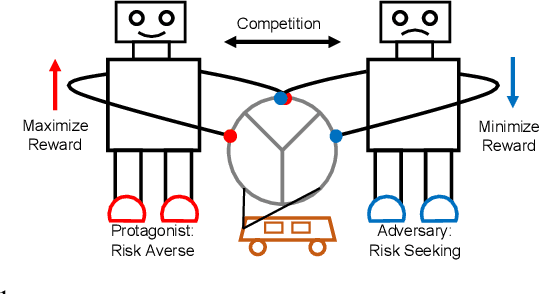
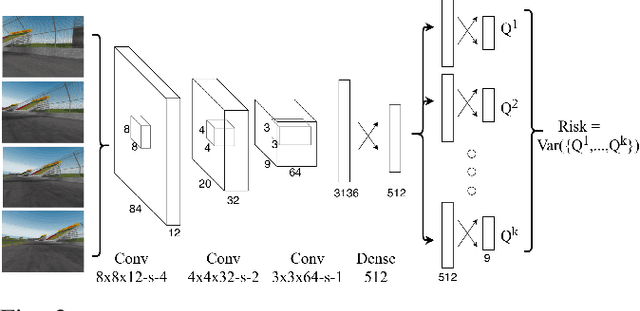
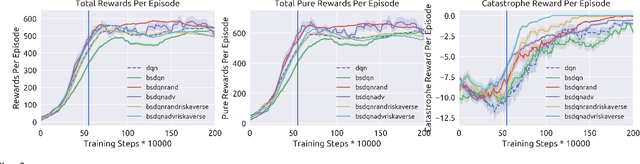
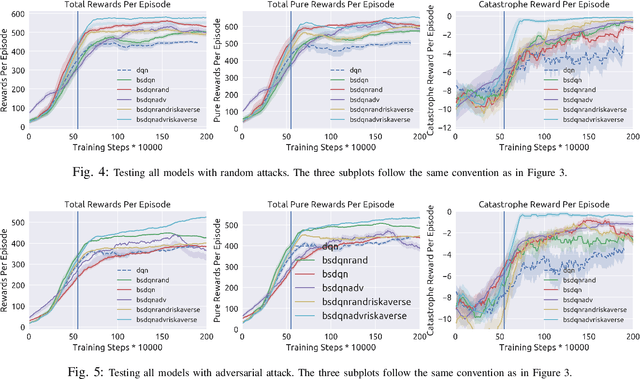
Deep reinforcement learning has recently made significant progress in solving computer games and robotic control tasks. A known problem, though, is that policies overfit to the training environment and may not avoid rare, catastrophic events such as automotive accidents. A classical technique for improving the robustness of reinforcement learning algorithms is to train on a set of randomized environments, but this approach only guards against common situations. Recently, robust adversarial reinforcement learning (RARL) was developed, which allows efficient applications of random and systematic perturbations by a trained adversary. A limitation of RARL is that only the expected control objective is optimized; there is no explicit modeling or optimization of risk. Thus the agents do not consider the probability of catastrophic events (i.e., those inducing abnormally large negative reward), except through their effect on the expected objective. In this paper we introduce risk-averse robust adversarial reinforcement learning (RARARL), using a risk-averse protagonist and a risk-seeking adversary. We test our approach on a self-driving vehicle controller. We use an ensemble of policy networks to model risk as the variance of value functions. We show through experiments that a risk-averse agent is better equipped to handle a risk-seeking adversary, and experiences substantially fewer crashes compared to agents trained without an adversary.
Label and Sample: Efficient Training of Vehicle Object Detector from Sparsely Labeled Data
Aug 26, 2018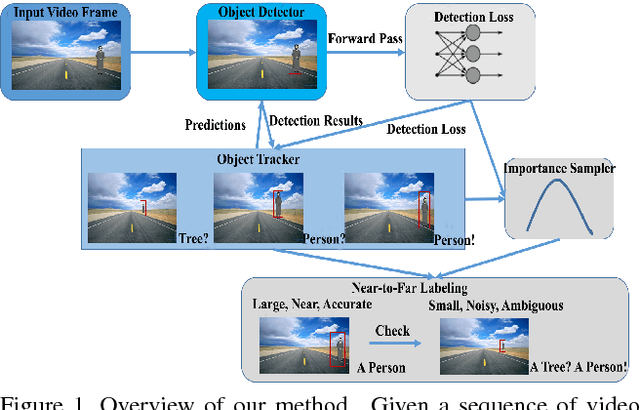
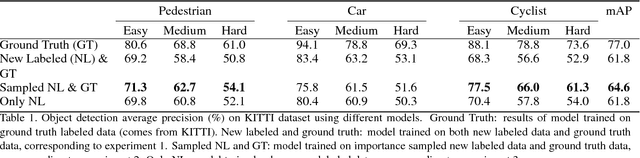

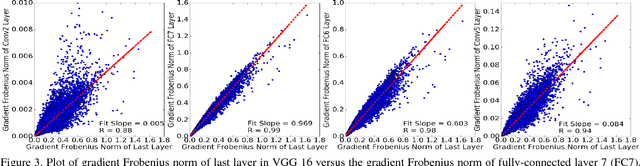
Self-driving vehicle vision systems must deal with an extremely broad and challenging set of scenes. They can potentially exploit an enormous amount of training data collected from vehicles in the field, but the volumes are too large to train offline naively. Not all training instances are equally valuable though, and importance sampling can be used to prioritize which training images to collect. This approach assumes that objects in images are labeled with high accuracy. To generate accurate labels in the field, we exploit the spatio-temporal coherence of vehicle video. We use a near-to-far labeling strategy by first labeling large, close objects in the video, and tracking them back in time to induce labels on small distant presentations of those objects. In this paper we demonstrate the feasibility of this approach in several steps. First, we note that an optimal subset (relative to all the objects encountered and labeled) of labeled objects in images can be obtained by importance sampling using gradients of the recognition network. Next we show that these gradients can be approximated with very low error using the loss function, which is already available when the CNN is running inference. Then, we generalize these results to objects in a larger scene using an object detection system. Finally, we describe a self-labeling scheme using object tracking. Objects are tracked back in time (near-to-far) and labels of near objects are used to check accuracy of those objects in the far field. We then evaluate the accuracy of models trained on importance sampled data vs models trained on complete data.