 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysically-Guided Optical Inversion Enable Non-Contact Side-Channel Attack on Isolated Screens
Apr 15, 2026Noncontact exfiltration of electronic screen content poses a security challenge, with side-channel incursions as the principal vector. We introduce an optical projection side-channel paradigm that confronts two core instabilities: (i) the near-singular Jacobian spectrum of projection mapping breaches Hadamard stability, rendering inversion hypersensitive to perturbations; (ii) irreversible compression in light transport obliterates global semantic cues, magnifying reconstruction ambiguity. Exploiting passive speckle patterns formed by diffuse reflection, our Irradiance Robust Radiometric Inversion Network (IR4Net) fuses a Physically Regularized Irradiance Approximation (PRIrr-Approximation), which embeds the radiative transfer equation in a learnable optimizer, with a contour-to-detail cross-scale reconstruction mechanism that arrests noise propagation. Moreover, an Irreversibility Constrained Semantic Reprojection (ICSR) module reinstates lost global structure through context-driven semantic mapping. Evaluated across four scene categories, IR4Net achieves fidelity beyond competing neural approaches while retaining resilience to illumination perturbations.
LARM: A Large Articulated-Object Reconstruction Model
Nov 14, 2025



Modeling 3D articulated objects with realistic geometry, textures, and kinematics is essential for a wide range of applications. However, existing optimization-based reconstruction methods often require dense multi-view inputs and expensive per-instance optimization, limiting their scalability. Recent feedforward approaches offer faster alternatives but frequently produce coarse geometry, lack texture reconstruction, and rely on brittle, complex multi-stage pipelines. We introduce LARM, a unified feedforward framework that reconstructs 3D articulated objects from sparse-view images by jointly recovering detailed geometry, realistic textures, and accurate joint structures. LARM extends LVSM a recent novel view synthesis (NVS) approach for static 3D objects into the articulated setting by jointly reasoning over camera pose and articulation variation using a transformer-based architecture, enabling scalable and accurate novel view synthesis. In addition, LARM generates auxiliary outputs such as depth maps and part masks to facilitate explicit 3D mesh extraction and joint estimation. Our pipeline eliminates the need for dense supervision and supports high-fidelity reconstruction across diverse object categories. Extensive experiments demonstrate that LARM outperforms state-of-the-art methods in both novel view and state synthesis as well as 3D articulated object reconstruction, generating high-quality meshes that closely adhere to the input images. project page: https://sylviayuan-sy.github.io/larm-site/
ConDense: Consistent 2D/3D Pre-training for Dense and Sparse Features from Multi-View Images
Aug 30, 2024



To advance the state of the art in the creation of 3D foundation models, this paper introduces the ConDense framework for 3D pre-training utilizing existing pre-trained 2D networks and large-scale multi-view datasets. We propose a novel 2D-3D joint training scheme to extract co-embedded 2D and 3D features in an end-to-end pipeline, where 2D-3D feature consistency is enforced through a volume rendering NeRF-like ray marching process. Using dense per pixel features we are able to 1) directly distill the learned priors from 2D models to 3D models and create useful 3D backbones, 2) extract more consistent and less noisy 2D features, 3) formulate a consistent embedding space where 2D, 3D, and other modalities of data (e.g., natural language prompts) can be jointly queried. Furthermore, besides dense features, ConDense can be trained to extract sparse features (e.g., key points), also with 2D-3D consistency -- condensing 3D NeRF representations into compact sets of decorated key points. We demonstrate that our pre-trained model provides good initialization for various 3D tasks including 3D classification and segmentation, outperforming other 3D pre-training methods by a significant margin. It also enables, by exploiting our sparse features, additional useful downstream tasks, such as matching 2D images to 3D scenes, detecting duplicate 3D scenes, and querying a repository of 3D scenes through natural language -- all quite efficiently and without any per-scene fine-tuning.
MeshFormer: High-Quality Mesh Generation with 3D-Guided Reconstruction Model
Aug 19, 2024



Open-world 3D reconstruction models have recently garnered significant attention. However, without sufficient 3D inductive bias, existing methods typically entail expensive training costs and struggle to extract high-quality 3D meshes. In this work, we introduce MeshFormer, a sparse-view reconstruction model that explicitly leverages 3D native structure, input guidance, and training supervision. Specifically, instead of using a triplane representation, we store features in 3D sparse voxels and combine transformers with 3D convolutions to leverage an explicit 3D structure and projective bias. In addition to sparse-view RGB input, we require the network to take input and generate corresponding normal maps. The input normal maps can be predicted by 2D diffusion models, significantly aiding in the guidance and refinement of the geometry's learning. Moreover, by combining Signed Distance Function (SDF) supervision with surface rendering, we directly learn to generate high-quality meshes without the need for complex multi-stage training processes. By incorporating these explicit 3D biases, MeshFormer can be trained efficiently and deliver high-quality textured meshes with fine-grained geometric details. It can also be integrated with 2D diffusion models to enable fast single-image-to-3D and text-to-3D tasks. Project page: https://meshformer3d.github.io
TensoIR: Tensorial Inverse Rendering
Apr 24, 2023We propose TensoIR, a novel inverse rendering approach based on tensor factorization and neural fields. Unlike previous works that use purely MLP-based neural fields, thus suffering from low capacity and high computation costs, we extend TensoRF, a state-of-the-art approach for radiance field modeling, to estimate scene geometry, surface reflectance, and environment illumination from multi-view images captured under unknown lighting conditions. Our approach jointly achieves radiance field reconstruction and physically-based model estimation, leading to photo-realistic novel view synthesis and relighting results. Benefiting from the efficiency and extensibility of the TensoRF-based representation, our method can accurately model secondary shading effects (like shadows and indirect lighting) and generally support input images captured under single or multiple unknown lighting conditions. The low-rank tensor representation allows us to not only achieve fast and compact reconstruction but also better exploit shared information under an arbitrary number of capturing lighting conditions. We demonstrate the superiority of our method to baseline methods qualitatively and quantitatively on various challenging synthetic and real-world scenes.
MovingParts: Motion-based 3D Part Discovery in Dynamic Radiance Field
Mar 10, 2023We present MovingParts, a NeRF-based method for dynamic scene reconstruction and part discovery. We consider motion as an important cue for identifying parts, that all particles on the same part share the common motion pattern. From the perspective of fluid simulation, existing deformation-based methods for dynamic NeRF can be seen as parameterizing the scene motion under the Eulerian view, i.e., focusing on specific locations in space through which the fluid flows as time passes. However, it is intractable to extract the motion of constituting objects or parts using the Eulerian view representation. In this work, we introduce the dual Lagrangian view and enforce representations under the Eulerian/Lagrangian views to be cycle-consistent. Under the Lagrangian view, we parameterize the scene motion by tracking the trajectory of particles on objects. The Lagrangian view makes it convenient to discover parts by factorizing the scene motion as a composition of part-level rigid motions. Experimentally, our method can achieve fast and high-quality dynamic scene reconstruction from even a single moving camera, and the induced part-based representation allows direct applications of part tracking, animation, 3D scene editing, etc.
Nerflets: Local Radiance Fields for Efficient Structure-Aware 3D Scene Representation from 2D Supervision
Mar 10, 2023We address efficient and structure-aware 3D scene representation from images. Nerflets are our key contribution -- a set of local neural radiance fields that together represent a scene. Each nerflet maintains its own spatial position, orientation, and extent, within which it contributes to panoptic, density, and radiance reconstructions. By leveraging only photometric and inferred panoptic image supervision, we can directly and jointly optimize the parameters of a set of nerflets so as to form a decomposed representation of the scene, where each object instance is represented by a group of nerflets. During experiments with indoor and outdoor environments, we find that nerflets: (1) fit and approximate the scene more efficiently than traditional global NeRFs, (2) allow the extraction of panoptic and photometric renderings from arbitrary views, and (3) enable tasks rare for NeRFs, such as 3D panoptic segmentation and interactive editing.
NeRFusion: Fusing Radiance Fields for Large-Scale Scene Reconstruction
Mar 21, 2022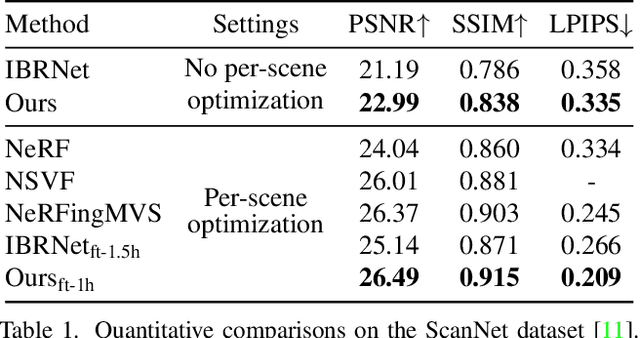
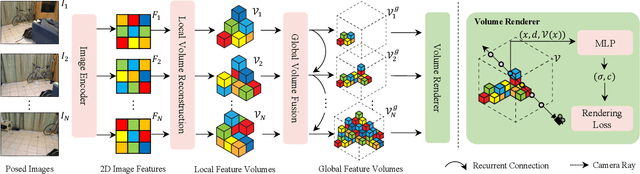
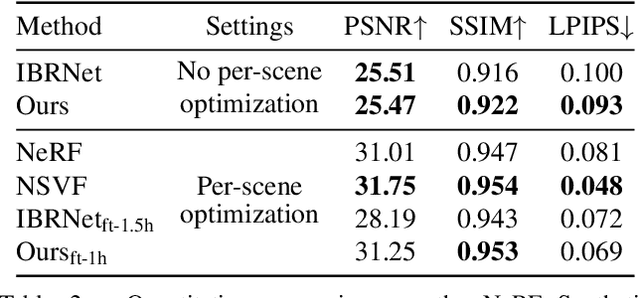
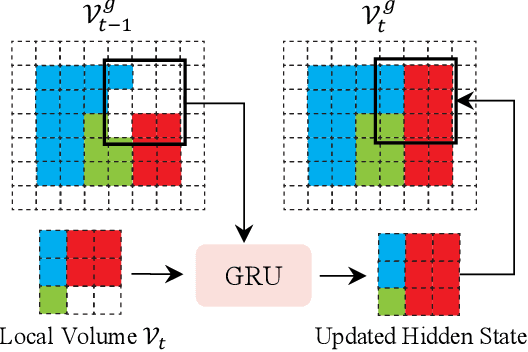
While NeRF has shown great success for neural reconstruction and rendering, its limited MLP capacity and long per-scene optimization times make it challenging to model large-scale indoor scenes. In contrast, classical 3D reconstruction methods can handle large-scale scenes but do not produce realistic renderings. We propose NeRFusion, a method that combines the advantages of NeRF and TSDF-based fusion techniques to achieve efficient large-scale reconstruction and photo-realistic rendering. We process the input image sequence to predict per-frame local radiance fields via direct network inference. These are then fused using a novel recurrent neural network that incrementally reconstructs a global, sparse scene representation in real-time at 22 fps. This global volume can be further fine-tuned to boost rendering quality. We demonstrate that NeRFusion achieves state-of-the-art quality on both large-scale indoor and small-scale object scenes, with substantially faster reconstruction than NeRF and other recent methods.
Close the Visual Domain Gap by Physics-Grounded Active Stereovision Depth Sensor Simulation
Feb 07, 2022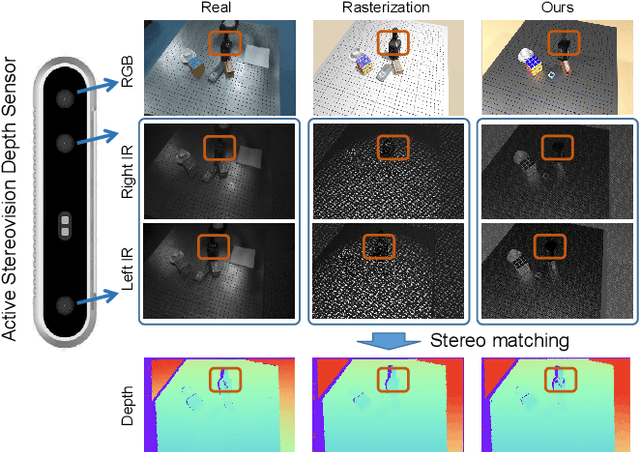
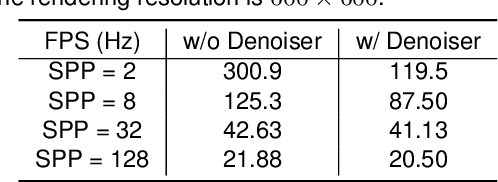
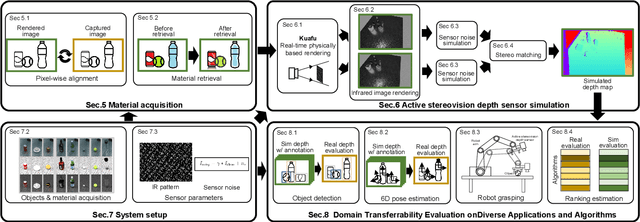
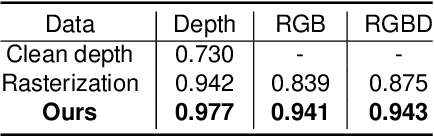
In this paper, we focus on the simulation of active stereovision depth sensors, which are popular in both academic and industry communities. Inspired by the underlying mechanism of the sensors, we designed a fully physics-grounded simulation pipeline, which includes material acquisition, ray tracing based infrared (IR) image rendering, IR noise simulation, and depth estimation. The pipeline is able to generate depth maps with material-dependent error patterns similar to a real depth sensor. We conduct extensive experiments to show that perception algorithms and reinforcement learning policies trained in our simulation platform could transfer well to real world test cases without any fine-tuning. Furthermore, due to the high degree of realism of this simulation, our depth sensor simulator can be used as a convenient testbed to evaluate the algorithm performance in the real world, which will largely reduce the human effort in developing robotic algorithms. The entire pipeline has been integrated into the SAPIEN simulator and is open-sourced to promote the research of vision and robotics communities.
ActiveZero: Mixed Domain Learning for Active Stereovision with Zero Annotation
Dec 06, 2021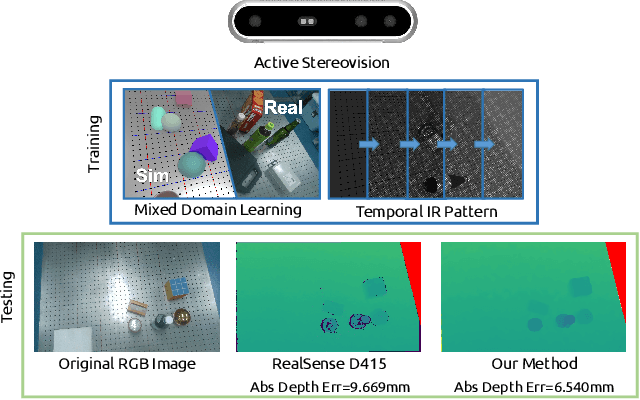
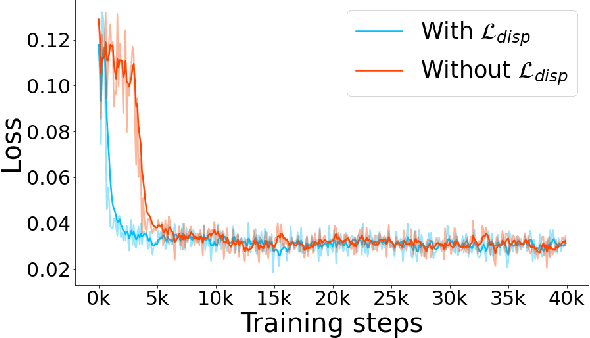
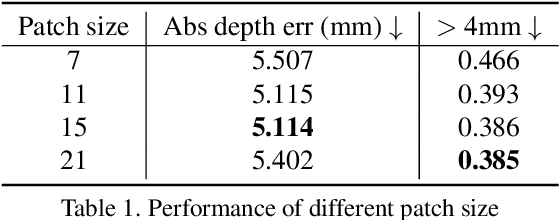
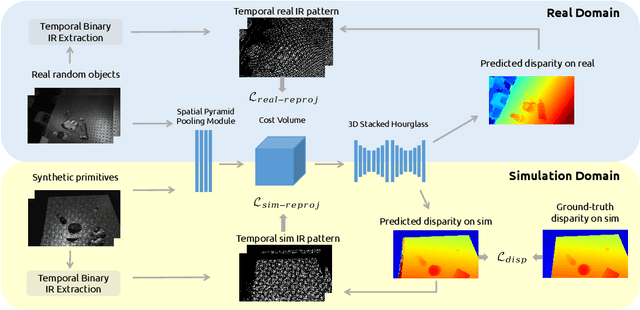
Traditional depth sensors generate accurate real world depth estimates that surpass even the most advanced learning approaches trained only on simulation domains. Since ground truth depth is readily available in the simulation domain but quite difficult to obtain in the real domain, we propose a method that leverages the best of both worlds. In this paper we present a new framework, ActiveZero, which is a mixed domain learning solution for active stereovision systems that requires no real world depth annotation. First, we demonstrate the transferability of our method to out-of-distribution real data by using a mixed domain learning strategy. In the simulation domain, we use a combination of supervised disparity loss and self-supervised losses on a shape primitives dataset. By contrast, in the real domain, we only use self-supervised losses on a dataset that is out-of-distribution from either training simulation data or test real data. Second, our method introduces a novel self-supervised loss called temporal IR reprojection to increase the robustness and accuracy of our reprojections in hard-to-perceive regions. Finally, we show how the method can be trained end-to-end and that each module is important for attaining the end result. Extensive qualitative and quantitative evaluations on real data demonstrate state of the art results that can even beat a commercial depth sensor.