 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptR1: Reinforcement Learning Based Adaptive Interleaved Thinking in Multi-hop Question Answering
May 29, 2026Large Language Models (LLMs) have achieved remarkable performance in complex reasoning tasks through Chain-of-Thought (CoT) prompting. However, this approach often leads to ``over-thinking,'' where models generate unnecessarily long reasoning traces for simple queries and incur avoidable inference cost. While recent work has explored adaptive reasoning, existing methods typically make a single query-level decision about whether to reason. This overlooks the dynamic nature of multi-step tasks, where the need for explicit reasoning varies across intermediate stages. To address this limitation, we introduce AdaptR1, a Reinforcement Learning (RL) based framework for adaptive interleaved thinking in multi-hop Question Answering (QA). Unlike previous approaches that require Supervised Fine-Tuning (SFT) for cold-start initialization, AdaptR1 uses a fully RL-based strategy with a quality-gated efficiency reward to dynamically allocate reasoning budgets at each step. Under the Graph-R1 setting, AdaptR1 reduces average think tokens by 69.71\%, with a 90.35\% reduction on HotpotQA, while maintaining performance comparable to or better than standard baselines. Furthermore, our analysis reveals that overthinking in multi-hop reasoning is not uniformly distributed but occurs predominantly during the initial planning stages, highlighting the effectiveness of step-wise adaptive budget allocation.
AgentLongBench: A Controllable Long Benchmark For Long-Contexts Agents via Environment Rollouts
Jan 29, 2026The evolution of Large Language Models (LLMs) into autonomous agents necessitates the management of extensive, dynamic contexts. Current benchmarks, however, remain largely static, relying on passive retrieval tasks that fail to simulate the complexities of agent-environment interaction, such as non-linear reasoning and iterative feedback. To address this, we introduce \textbf{AgentLongBench}, which evaluates agents through simulated environment rollouts based on Lateral Thinking Puzzles. This framework generates rigorous interaction trajectories across knowledge-intensive and knowledge-free scenarios. Experiments with state-of-the-art models and memory systems (32K to 4M tokens) expose a critical weakness: while adept at static retrieval, agents struggle with the dynamic information synthesis essential for workflows. Our analysis indicates that this degradation is driven by the minimum number of tokens required to resolve a query. This factor explains why the high information density inherent in massive tool responses poses a significantly greater challenge than the memory fragmentation typical of long-turn dialogues.
Is Fine-Tuning an Effective Solution? Reassessing Knowledge Editing for Unstructured Data
Jun 11, 2025



Unstructured Knowledge Editing (UKE) is crucial for updating the relevant knowledge of large language models (LLMs). It focuses on unstructured inputs, such as long or free-form texts, which are common forms of real-world knowledge. Although previous studies have proposed effective methods and tested them, some issues exist: (1) Lack of Locality evaluation for UKE, and (2) Abnormal failure of fine-tuning (FT) based methods for UKE. To address these issues, we first construct two datasets, UnKEBench-Loc and AKEW-Loc (CF), by extending two existing UKE datasets with locality test data from the unstructured and structured views. This enables a systematic evaluation of the Locality of post-edited models. Furthermore, we identify four factors that may affect the performance of FT-based methods. Based on these factors, we conduct experiments to determine how the well-performing FT-based methods should be trained for the UKE task, providing a training recipe for future research. Our experimental results indicate that the FT-based method with the optimal setting (FT-UKE) is surprisingly strong, outperforming the existing state-of-the-art (SOTA). In batch editing scenarios, FT-UKE shows strong performance as well, with its advantage over SOTA methods increasing as the batch size grows, expanding the average metric lead from +6.78% to +10.80%
UAQFact: Evaluating Factual Knowledge Utilization of LLMs on Unanswerable Questions
May 29, 2025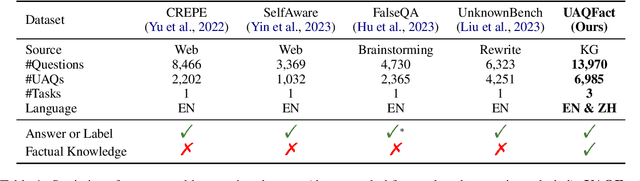



Handling unanswerable questions (UAQ) is crucial for LLMs, as it helps prevent misleading responses in complex situations. While previous studies have built several datasets to assess LLMs' performance on UAQ, these datasets lack factual knowledge support, which limits the evaluation of LLMs' ability to utilize their factual knowledge when handling UAQ. To address the limitation, we introduce a new unanswerable question dataset UAQFact, a bilingual dataset with auxiliary factual knowledge created from a Knowledge Graph. Based on UAQFact, we further define two new tasks to measure LLMs' ability to utilize internal and external factual knowledge, respectively. Our experimental results across multiple LLM series show that UAQFact presents significant challenges, as LLMs do not consistently perform well even when they have factual knowledge stored. Additionally, we find that incorporating external knowledge may enhance performance, but LLMs still cannot make full use of the knowledge which may result in incorrect responses.
Learning to Refuse: Towards Mitigating Privacy Risks in LLMs
Jul 14, 2024Large language models (LLMs) exhibit remarkable capabilities in understanding and generating natural language. However, these models can inadvertently memorize private information, posing significant privacy risks. This study addresses the challenge of enabling LLMs to protect specific individuals' private data without the need for complete retraining. We propose \return, a Real-world pErsonal daTa UnleaRNing dataset, comprising 2,492 individuals from Wikipedia with associated QA pairs, to evaluate machine unlearning (MU) methods for protecting personal data in a realistic scenario. Additionally, we introduce the Name-Aware Unlearning Framework (NAUF) for Privacy Protection, which enables the model to learn which individuals' information should be protected without affecting its ability to answer questions related to other unrelated individuals. Our extensive experiments demonstrate that NAUF achieves a state-of-the-art average unlearning score, surpassing the best baseline method by 5.65 points, effectively protecting target individuals' personal data while maintaining the model's general capabilities.
Probing Language Models for Pre-training Data Detection
Jun 03, 2024Large Language Models (LLMs) have shown their impressive capabilities, while also raising concerns about the data contamination problems due to privacy issues and leakage of benchmark datasets in the pre-training phase. Therefore, it is vital to detect the contamination by checking whether an LLM has been pre-trained on the target texts. Recent studies focus on the generated texts and compute perplexities, which are superficial features and not reliable. In this study, we propose to utilize the probing technique for pre-training data detection by examining the model's internal activations. Our method is simple and effective and leads to more trustworthy pre-training data detection. Additionally, we propose ArxivMIA, a new challenging benchmark comprising arxiv abstracts from Computer Science and Mathematics categories. Our experiments demonstrate that our method outperforms all baselines, and achieves state-of-the-art performance on both WikiMIA and ArxivMIA, with additional experiments confirming its efficacy (Our code and dataset are available at https://github.com/zhliu0106/probing-lm-data).
Seal-Tools: Self-Instruct Tool Learning Dataset for Agent Tuning and Detailed Benchmark
May 14, 2024This paper presents a new tool learning dataset Seal-Tools, which contains self-instruct API-like tools. Seal-Tools not only offers a large number of tools, but also includes instances which demonstrate the practical application of tools. Seeking to generate data on a large scale while ensuring reliability, we propose a self-instruct method to generate tools and instances, allowing precise control over the process. Moreover, our Seal-Tools contains hard instances that call multiple tools to complete the job, among which some are nested tool callings. For precise and comprehensive evaluation, we use strict format control and design three metrics from different dimensions. Therefore, Seal-Tools can serve as a new benchmark to evaluate the tool-calling ability of LLMs. Finally, we evaluate several prevalent LLMs and our finetuned model on Seal-Tools. The results show that current systems are far from perfect. The code, data and experiment results are available at https://github.com/fairyshine/Seal-Tools .
Make a Choice! Knowledge Base Question Answering with In-Context Learning
May 23, 2023



Question answering over knowledge bases (KBQA) aims to answer factoid questions with a given knowledge base (KB). Due to the large scale of KB, annotated data is impossible to cover all fact schemas in KB, which poses a challenge to the generalization ability of methods that require a sufficient amount of annotated data. Recently, LLMs have shown strong few-shot performance in many NLP tasks. We expect LLM can help existing methods improve their generalization ability, especially in low-resource situations. In this paper, we present McL-KBQA, a framework that incorporates the few-shot ability of LLM into the KBQA method via ICL-based multiple choice and then improves the effectiveness of the QA tasks. Experimental results on two KBQA datasets demonstrate the competitive performance of McL-KBQA with strong improvements in generalization. We expect to explore a new way to QA tasks from KBQA in conjunction with LLM, how to generate answers normatively and correctly with strong generalization.