 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstroReason-Bench: Evaluating Unified Agentic Planning across Heterogeneous Space Planning Problems
Jan 16, 2026Recent advances in agentic Large Language Models (LLMs) have positioned them as generalist planners capable of reasoning and acting across diverse tasks. However, existing agent benchmarks largely focus on symbolic or weakly grounded environments, leaving their performance in physics-constrained real-world domains underexplored. We introduce AstroReason-Bench, a comprehensive benchmark for evaluating agentic planning in Space Planning Problems (SPP), a family of high-stakes problems with heterogeneous objectives, strict physical constraints, and long-horizon decision-making. AstroReason-Bench integrates multiple scheduling regimes, including ground station communication and agile Earth observation, and provides a unified agent-oriented interaction protocol. Evaluating on a range of state-of-the-art open- and closed-source agentic LLM systems, we find that current agents substantially underperform specialized solvers, highlighting key limitations of generalist planning under realistic constraints. AstroReason-Bench offers a challenging and diagnostic testbed for future agentic research.
Taming Hyperparameter Sensitivity in Data Attribution: Practical Selection Without Costly Retraining
May 30, 2025Data attribution methods, which quantify the influence of individual training data points on a machine learning model, have gained increasing popularity in data-centric applications in modern AI. Despite a recent surge of new methods developed in this space, the impact of hyperparameter tuning in these methods remains under-explored. In this work, we present the first large-scale empirical study to understand the hyperparameter sensitivity of common data attribution methods. Our results show that most methods are indeed sensitive to certain key hyperparameters. However, unlike typical machine learning algorithms -- whose hyperparameters can be tuned using computationally-cheap validation metrics -- evaluating data attribution performance often requires retraining models on subsets of training data, making such metrics prohibitively costly for hyperparameter tuning. This poses a critical open challenge for the practical application of data attribution methods. To address this challenge, we advocate for better theoretical understandings of hyperparameter behavior to inform efficient tuning strategies. As a case study, we provide a theoretical analysis of the regularization term that is critical in many variants of influence function methods. Building on this analysis, we propose a lightweight procedure for selecting the regularization value without model retraining, and validate its effectiveness across a range of standard data attribution benchmarks. Overall, our study identifies a fundamental yet overlooked challenge in the practical application of data attribution, and highlights the importance of careful discussion on hyperparameter selection in future method development.
A collaborative filtering model with heterogeneous neural networks for recommender systems
May 27, 2019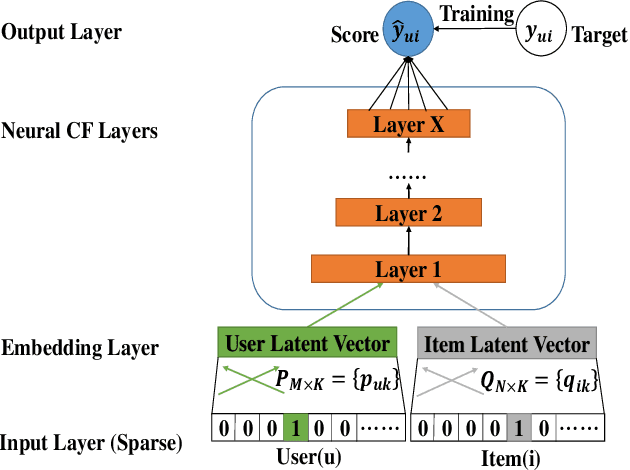
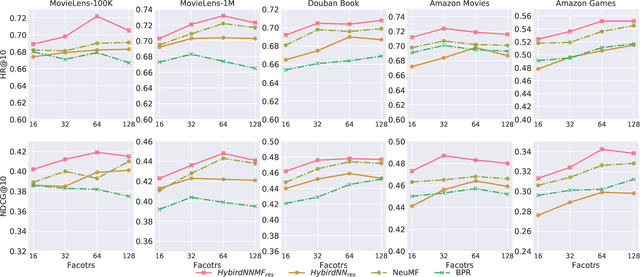
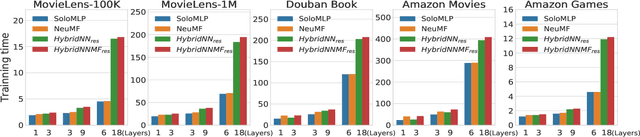
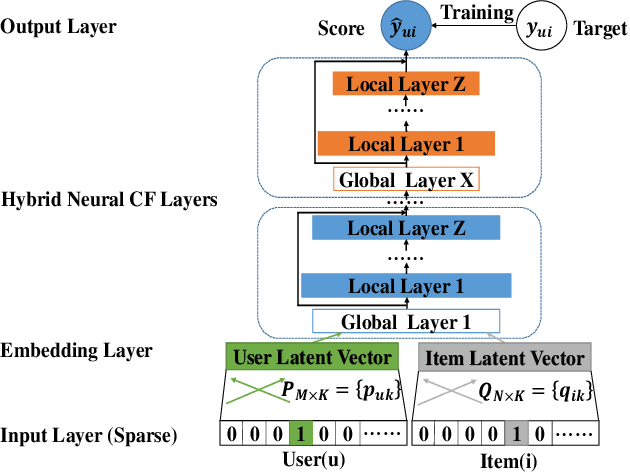
In recent years, deep neural network is introduced in recommender systems to solve the collaborative filtering problem, which has achieved immense success on computer vision, speech recognition and natural language processing. On one hand, deep neural network can be used to model the auxiliary information in recommender systems. On the other hand, it is also capable of modeling nonlinear relationships between users and items. One advantage of deep neural network is that the performance of the algorithm can be easily enhanced by augmenting the depth of the neural network. However, two potential problems may emerge when the deep neural work is exploited to model relationships between users and items. The fundamental problem is that the complexity of the algorithm grows significantly with the increment in the depth of the neural network. The second one is that a deeper neural network may undermine the accuracy of the algorithm. In order to alleviate these problems, we propose a hybrid neural network that combines heterogeneous neural networks with different structures. The experimental results on real datasets reveal that our method is superior to the state-of-the-art methods in terms of the item ranking.