 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlying in Clutter on Monocular RGB by Learning in 3D Radiance Fields with Domain Adaptation
Dec 19, 2025Modern autonomous navigation systems predominantly rely on lidar and depth cameras. However, a fundamental question remains: Can flying robots navigate in clutter using solely monocular RGB images? Given the prohibitive costs of real-world data collection, learning policies in simulation offers a promising path. Yet, deploying such policies directly in the physical world is hindered by the significant sim-to-real perception gap. Thus, we propose a framework that couples the photorealism of 3D Gaussian Splatting (3DGS) environments with Adversarial Domain Adaptation. By training in high-fidelity simulation while explicitly minimizing feature discrepancy, our method ensures the policy relies on domain-invariant cues. Experimental results demonstrate that our policy achieves robust zero-shot transfer to the physical world, enabling safe and agile flight in unstructured environments with varying illumination.
SAM 2++: Tracking Anything at Any Granularity
Oct 22, 2025Video tracking aims at finding the specific target in subsequent frames given its initial state. Due to the varying granularity of target states across different tasks, most existing trackers are tailored to a single task and heavily rely on custom-designed modules within the individual task, which limits their generalization and leads to redundancy in both model design and parameters. To unify video tracking tasks, we present SAM 2++, a unified model towards tracking at any granularity, including masks, boxes, and points. First, to extend target granularity, we design task-specific prompts to encode various task inputs into general prompt embeddings, and a unified decoder to unify diverse task results into a unified form pre-output. Next, to satisfy memory matching, the core operation of tracking, we introduce a task-adaptive memory mechanism that unifies memory across different granularities. Finally, we introduce a customized data engine to support tracking training at any granularity, producing a large and diverse video tracking dataset with rich annotations at three granularities, termed Tracking-Any-Granularity, which represents a comprehensive resource for training and benchmarking on unified tracking. Comprehensive experiments on multiple benchmarks confirm that SAM 2++ sets a new state of the art across diverse tracking tasks at different granularities, establishing a unified and robust tracking framework.
SecureAgentBench: Benchmarking Secure Code Generation under Realistic Vulnerability Scenarios
Sep 26, 2025Large language model (LLM) powered code agents are rapidly transforming software engineering by automating tasks such as testing, debugging, and repairing, yet the security risks of their generated code have become a critical concern. Existing benchmarks have offered valuable insights but remain insufficient: they often overlook the genuine context in which vulnerabilities were introduced or adopt narrow evaluation protocols that fail to capture either functional correctness or newly introduced vulnerabilities. We therefore introduce SecureAgentBench, a benchmark of 105 coding tasks designed to rigorously evaluate code agents' capabilities in secure code generation. Each task includes (i) realistic task settings that require multi-file edits in large repositories, (ii) aligned contexts based on real-world open-source vulnerabilities with precisely identified introduction points, and (iii) comprehensive evaluation that combines functionality testing, vulnerability checking through proof-of-concept exploits, and detection of newly introduced vulnerabilities using static analysis. We evaluate three representative agents (SWE-agent, OpenHands, and Aider) with three state-of-the-art LLMs (Claude 3.7 Sonnet, GPT-4.1, and DeepSeek-V3.1). Results show that (i) current agents struggle to produce secure code, as even the best-performing one, SWE-agent supported by DeepSeek-V3.1, achieves merely 15.2% correct-and-secure solutions, (ii) some agents produce functionally correct code but still introduce vulnerabilities, including new ones not previously recorded, and (iii) adding explicit security instructions for agents does not significantly improve secure coding, underscoring the need for further research. These findings establish SecureAgentBench as a rigorous benchmark for secure code generation and a step toward more reliable software development with LLMs.
SoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
TreePO: Bridging the Gap of Policy Optimization and Efficacy and Inference Efficiency with Heuristic Tree-based Modeling
Aug 24, 2025



Recent advancements in aligning large language models via reinforcement learning have achieved remarkable gains in solving complex reasoning problems, but at the cost of expensive on-policy rollouts and limited exploration of diverse reasoning paths. In this work, we introduce TreePO, involving a self-guided rollout algorithm that views sequence generation as a tree-structured searching process. Composed of dynamic tree sampling policy and fixed-length segment decoding, TreePO leverages local uncertainty to warrant additional branches. By amortizing computation across common prefixes and pruning low-value paths early, TreePO essentially reduces the per-update compute burden while preserving or enhancing exploration diversity. Key contributions include: (1) a segment-wise sampling algorithm that alleviates the KV cache burden through contiguous segments and spawns new branches along with an early-stop mechanism; (2) a tree-based segment-level advantage estimation that considers both global and local proximal policy optimization. and (3) analysis on the effectiveness of probability and quality-driven dynamic divergence and fallback strategy. We empirically validate the performance gain of TreePO on a set reasoning benchmarks and the efficiency saving of GPU hours from 22\% up to 43\% of the sampling design for the trained models, meanwhile showing up to 40\% reduction at trajectory-level and 35\% at token-level sampling compute for the existing models. While offering a free lunch of inference efficiency, TreePO reveals a practical path toward scaling RL-based post-training with fewer samples and less compute. Home page locates at https://m-a-p.ai/TreePO.
Semantic Item Graph Enhancement for Multimodal Recommendation
Aug 08, 2025Multimodal recommendation systems have attracted increasing attention for their improved performance by leveraging items' multimodal information. Prior methods often build modality-specific item-item semantic graphs from raw modality features and use them as supplementary structures alongside the user-item interaction graph to enhance user preference learning. However, these semantic graphs suffer from semantic deficiencies, including (1) insufficient modeling of collaborative signals among items and (2) structural distortions introduced by noise in raw modality features, ultimately compromising performance. To address these issues, we first extract collaborative signals from the interaction graph and infuse them into each modality-specific item semantic graph to enhance semantic modeling. Then, we design a modulus-based personalized embedding perturbation mechanism that injects perturbations with modulus-guided personalized intensity into embeddings to generate contrastive views. This enables the model to learn noise-robust representations through contrastive learning, thereby reducing the effect of structural noise in semantic graphs. Besides, we propose a dual representation alignment mechanism that first aligns multiple semantic representations via a designed Anchor-based InfoNCE loss using behavior representations as anchors, and then aligns behavior representations with the fused semantics by standard InfoNCE, to ensure representation consistency. Extensive experiments on four benchmark datasets validate the effectiveness of our framework.
First Return, Entropy-Eliciting Explore
Jul 09, 2025Reinforcement Learning from Verifiable Rewards (RLVR) improves the reasoning abilities of Large Language Models (LLMs) but it struggles with unstable exploration. We propose FR3E (First Return, Entropy-Eliciting Explore), a structured exploration framework that identifies high-uncertainty decision points in reasoning trajectories and performs targeted rollouts to construct semantically grounded intermediate feedback. Our method provides targeted guidance without relying on dense supervision. Empirical results on mathematical reasoning benchmarks(AIME24) show that FR3E promotes more stable training, produces longer and more coherent responses, and increases the proportion of fully correct trajectories. These results highlight the framework's effectiveness in improving LLM reasoning through more robust and structured exploration.
Less is Enough: Training-Free Video Diffusion Acceleration via Runtime-Adaptive Caching
Jul 03, 2025Video generation models have demonstrated remarkable performance, yet their broader adoption remains constrained by slow inference speeds and substantial computational costs, primarily due to the iterative nature of the denoising process. Addressing this bottleneck is essential for democratizing advanced video synthesis technologies and enabling their integration into real-world applications. This work proposes EasyCache, a training-free acceleration framework for video diffusion models. EasyCache introduces a lightweight, runtime-adaptive caching mechanism that dynamically reuses previously computed transformation vectors, avoiding redundant computations during inference. Unlike prior approaches, EasyCache requires no offline profiling, pre-computation, or extensive parameter tuning. We conduct comprehensive studies on various large-scale video generation models, including OpenSora, Wan2.1, and HunyuanVideo. Our method achieves leading acceleration performance, reducing inference time by up to 2.1-3.3$\times$ compared to the original baselines while maintaining high visual fidelity with a significant up to 36% PSNR improvement compared to the previous SOTA method. This improvement makes our EasyCache a efficient and highly accessible solution for high-quality video generation in both research and practical applications. The code is available at https://github.com/H-EmbodVis/EasyCache.
UniTac-NV: A Unified Tactile Representation For Non-Vision-Based Tactile Sensors
Jun 24, 2025Generalizable algorithms for tactile sensing remain underexplored, primarily due to the diversity of sensor modalities. Recently, many methods for cross-sensor transfer between optical (vision-based) tactile sensors have been investigated, yet little work focus on non-optical tactile sensors. To address this gap, we propose an encoder-decoder architecture to unify tactile data across non-vision-based sensors. By leveraging sensor-specific encoders, the framework creates a latent space that is sensor-agnostic, enabling cross-sensor data transfer with low errors and direct use in downstream applications. We leverage this network to unify tactile data from two commercial tactile sensors: the Xela uSkin uSPa 46 and the Contactile PapillArray. Both were mounted on a UR5e robotic arm, performing force-controlled pressing sequences against distinct object shapes (circular, square, and hexagonal prisms) and two materials (rigid PLA and flexible TPU). Another more complex unseen object was also included to investigate the model's generalization capabilities. We show that alignment in latent space can be implicitly learned from joint autoencoder training with matching contacts collected via different sensors. We further demonstrate the practical utility of our approach through contact geometry estimation, where downstream models trained on one sensor's latent representation can be directly applied to another without retraining.
An LLM-as-Judge Metric for Bridging the Gap with Human Evaluation in SE Tasks
May 27, 2025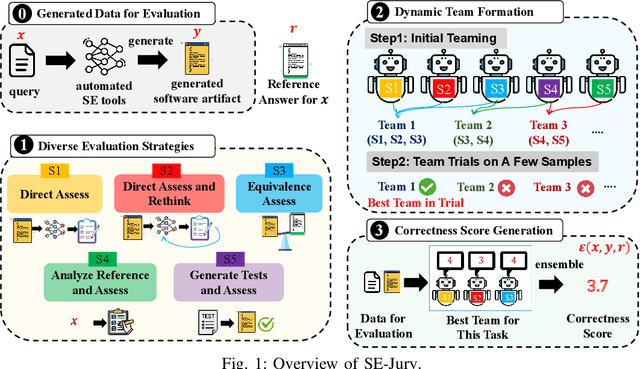
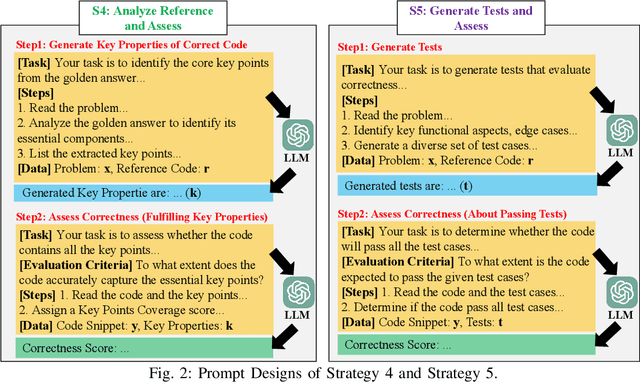
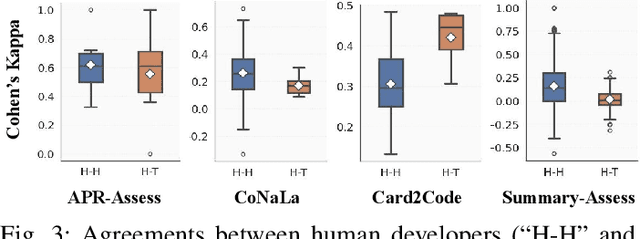
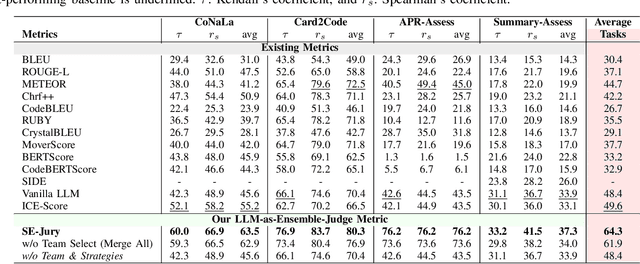
Large Language Models (LLMs) and other automated techniques have been increasingly used to support software developers by generating software artifacts such as code snippets, patches, and comments. However, accurately assessing the correctness of these generated artifacts remains a significant challenge. On one hand, human evaluation provides high accuracy but is labor-intensive and lacks scalability. On the other hand, other existing automatic evaluation metrics are scalable and require minimal human effort, but they often fail to accurately reflect the actual correctness of generated software artifacts. In this paper, we present SWE-Judge, the first evaluation metric for LLM-as-Ensemble-Judge specifically designed to accurately assess the correctness of generated software artifacts. SWE-Judge first defines five distinct evaluation strategies, each implemented as an independent judge. A dynamic team selection mechanism then identifies the most appropriate subset of judges to produce a final correctness score through ensembling. We evaluate SWE-Judge across a diverse set of software engineering (SE) benchmarks, including CoNaLa, Card2Code, HumanEval-X, APPS, APR-Assess, and Summary-Assess. These benchmarks span three SE tasks: code generation, automated program repair, and code summarization. Experimental results demonstrate that SWE-Judge consistently achieves a higher correlation with human judgments, with improvements ranging from 5.9% to 183.8% over existing automatic metrics. Furthermore, SWE-Judge reaches agreement levels with human annotators that are comparable to inter-annotator agreement in code generation and program repair tasks. These findings underscore SWE-Judge's potential as a scalable and reliable alternative to human evaluation.