 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-target Divergence Hypothesis: Toward Understanding Domain Gaps in Cross-Modal Knowledge Distillation
Sep 04, 2024



Compared to single-modal knowledge distillation, cross-modal knowledge distillation faces more severe challenges due to domain gaps between modalities. Although various methods have proposed various solutions to overcome these challenges, there is still limited research on how domain gaps affect cross-modal knowledge distillation. This paper provides an in-depth analysis and evaluation of this issue. We first introduce the Non-Target Divergence Hypothesis (NTDH) to reveal the impact of domain gaps on cross-modal knowledge distillation. Our key finding is that domain gaps between modalities lead to distribution differences in non-target classes, and the smaller these differences, the better the performance of cross-modal knowledge distillation. Subsequently, based on Vapnik-Chervonenkis (VC) theory, we derive the upper and lower bounds of the approximation error for cross-modal knowledge distillation, thereby theoretically validating the NTDH. Finally, experiments on five cross-modal datasets further confirm the validity, generalisability, and applicability of the NTDH.
COMOGen: A Controllable Text-to-3D Multi-object Generation Framework
Sep 01, 2024



The controllability of 3D object generation methods is achieved through input text. Existing text-to-3D object generation methods primarily focus on generating a single object based on a single object description. However, these methods often face challenges in producing results that accurately correspond to our desired positions when the input text involves multiple objects. To address the issue of controllability in generating multiple objects, this paper introduces COMOGen, a COntrollable text-to-3D Multi-Object Generation framework. COMOGen enables the simultaneous generation of multiple 3D objects by the distillation of layout and multi-view prior knowledge. The framework consists of three modules: the layout control module, the multi-view consistency control module, and the 3D content enhancement module. Moreover, to integrate these three modules as an integral framework, we propose Layout Multi-view Score Distillation, which unifies two prior knowledge and further enhances the diversity and quality of generated 3D content. Comprehensive experiments demonstrate the effectiveness of our approach compared to the state-of-the-art methods, which represents a significant step forward in enabling more controlled and versatile text-based 3D content generation.
TASeg: Temporal Aggregation Network for LiDAR Semantic Segmentation
Jul 13, 2024



Training deep models for LiDAR semantic segmentation is challenging due to the inherent sparsity of point clouds. Utilizing temporal data is a natural remedy against the sparsity problem as it makes the input signal denser. However, previous multi-frame fusion algorithms fall short in utilizing sufficient temporal information due to the memory constraint, and they also ignore the informative temporal images. To fully exploit rich information hidden in long-term temporal point clouds and images, we present the Temporal Aggregation Network, termed TASeg. Specifically, we propose a Temporal LiDAR Aggregation and Distillation (TLAD) algorithm, which leverages historical priors to assign different aggregation steps for different classes. It can largely reduce memory and time overhead while achieving higher accuracy. Besides, TLAD trains a teacher injected with gt priors to distill the model, further boosting the performance. To make full use of temporal images, we design a Temporal Image Aggregation and Fusion (TIAF) module, which can greatly expand the camera FOV and enhance the present features. Temporal LiDAR points in the camera FOV are used as mediums to transform temporal image features to the present coordinate for temporal multi-modal fusion. Moreover, we develop a Static-Moving Switch Augmentation (SMSA) algorithm, which utilizes sufficient temporal information to enable objects to switch their motion states freely, thus greatly increasing static and moving training samples. Our TASeg ranks 1st on three challenging tracks, i.e., SemanticKITTI single-scan track, multi-scan track and nuScenes LiDAR segmentation track, strongly demonstrating the superiority of our method. Codes are available at https://github.com/LittlePey/TASeg.
Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B
Jun 11, 2024



This paper introduces the MCT Self-Refine (MCTSr) algorithm, an innovative integration of Large Language Models (LLMs) with Monte Carlo Tree Search (MCTS), designed to enhance performance in complex mathematical reasoning tasks. Addressing the challenges of accuracy and reliability in LLMs, particularly in strategic and mathematical reasoning, MCTSr leverages systematic exploration and heuristic self-refine mechanisms to improve decision-making frameworks within LLMs. The algorithm constructs a Monte Carlo search tree through iterative processes of Selection, self-refine, self-evaluation, and Backpropagation, utilizing an improved Upper Confidence Bound (UCB) formula to optimize the exploration-exploitation balance. Extensive experiments demonstrate MCTSr's efficacy in solving Olympiad-level mathematical problems, significantly improving success rates across multiple datasets, including GSM8K, GSM Hard, MATH, and Olympiad-level benchmarks, including Math Odyssey, AIME, and OlympiadBench. The study advances the application of LLMs in complex reasoning tasks and sets a foundation for future AI integration, enhancing decision-making accuracy and reliability in LLM-driven applications.
Diverse Teacher-Students for Deep Safe Semi-Supervised Learning under Class Mismatch
May 25, 2024



Semi-supervised learning can significantly boost model performance by leveraging unlabeled data, particularly when labeled data is scarce. However, real-world unlabeled data often contain unseen-class samples, which can hinder the classification of seen classes. To address this issue, mainstream safe SSL methods suggest detecting and discarding unseen-class samples from unlabeled data. Nevertheless, these methods typically employ a single-model strategy to simultaneously tackle both the classification of seen classes and the detection of unseen classes. Our research indicates that such an approach may lead to conflicts during training, resulting in suboptimal model optimization. Inspired by this, we introduce a novel framework named Diverse Teacher-Students (\textbf{DTS}), which uniquely utilizes dual teacher-student models to individually and effectively handle these two tasks. DTS employs a novel uncertainty score to softly separate unseen-class and seen-class data from the unlabeled set, and intelligently creates an additional ($K$+1)-th class supervisory signal for training. By training both teacher-student models with all unlabeled samples, DTS can enhance the classification of seen classes while simultaneously improving the detection of unseen classes. Comprehensive experiments demonstrate that DTS surpasses baseline methods across a variety of datasets and configurations. Our code and models can be publicly accessible on the link https://github.com/Zhanlo/DTS.
3DBench: A Scalable 3D Benchmark and Instruction-Tuning Dataset
Apr 23, 2024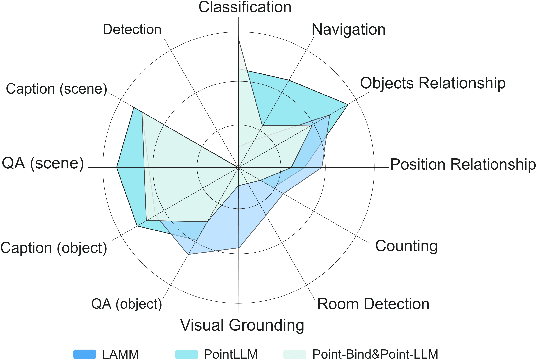
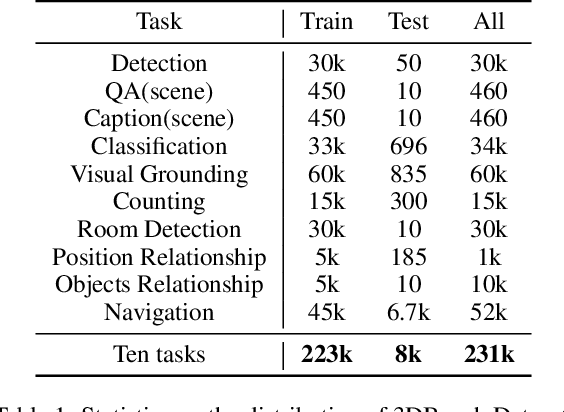
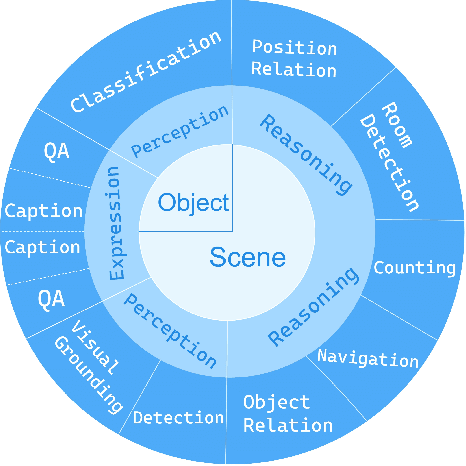

Evaluating the performance of Multi-modal Large Language Models (MLLMs), integrating both point cloud and language, presents significant challenges. The lack of a comprehensive assessment hampers determining whether these models truly represent advancements, thereby impeding further progress in the field. Current evaluations heavily rely on classification and caption tasks, falling short in providing a thorough assessment of MLLMs. A pressing need exists for a more sophisticated evaluation method capable of thoroughly analyzing the spatial understanding and expressive capabilities of these models. To address these issues, we introduce a scalable 3D benchmark, accompanied by a large-scale instruction-tuning dataset known as 3DBench, providing an extensible platform for a comprehensive evaluation of MLLMs. Specifically, we establish the benchmark that spans a wide range of spatial and semantic scales, from object-level to scene-level, addressing both perception and planning tasks. Furthermore, we present a rigorous pipeline for automatically constructing scalable 3D instruction-tuning datasets, covering 10 diverse multi-modal tasks with more than 0.23 million QA pairs generated in total. Thorough experiments evaluating trending MLLMs, comparisons against existing datasets, and variations of training protocols demonstrate the superiority of 3DBench, offering valuable insights into current limitations and potential research directions.
Taming Stable Diffusion for Text to 360° Panorama Image Generation
Apr 11, 2024Generative models, e.g., Stable Diffusion, have enabled the creation of photorealistic images from text prompts. Yet, the generation of 360-degree panorama images from text remains a challenge, particularly due to the dearth of paired text-panorama data and the domain gap between panorama and perspective images. In this paper, we introduce a novel dual-branch diffusion model named PanFusion to generate a 360-degree image from a text prompt. We leverage the stable diffusion model as one branch to provide prior knowledge in natural image generation and register it to another panorama branch for holistic image generation. We propose a unique cross-attention mechanism with projection awareness to minimize distortion during the collaborative denoising process. Our experiments validate that PanFusion surpasses existing methods and, thanks to its dual-branch structure, can integrate additional constraints like room layout for customized panorama outputs. Code is available at https://chengzhag.github.io/publication/panfusion.
GVGEN: Text-to-3D Generation with Volumetric Representation
Mar 19, 2024



In recent years, 3D Gaussian splatting has emerged as a powerful technique for 3D reconstruction and generation, known for its fast and high-quality rendering capabilities. To address these shortcomings, this paper introduces a novel diffusion-based framework, GVGEN, designed to efficiently generate 3D Gaussian representations from text input. We propose two innovative techniques:(1) Structured Volumetric Representation. We first arrange disorganized 3D Gaussian points as a structured form GaussianVolume. This transformation allows the capture of intricate texture details within a volume composed of a fixed number of Gaussians. To better optimize the representation of these details, we propose a unique pruning and densifying method named the Candidate Pool Strategy, enhancing detail fidelity through selective optimization. (2) Coarse-to-fine Generation Pipeline. To simplify the generation of GaussianVolume and empower the model to generate instances with detailed 3D geometry, we propose a coarse-to-fine pipeline. It initially constructs a basic geometric structure, followed by the prediction of complete Gaussian attributes. Our framework, GVGEN, demonstrates superior performance in qualitative and quantitative assessments compared to existing 3D generation methods. Simultaneously, it maintains a fast generation speed ($\sim$7 seconds), effectively striking a balance between quality and efficiency.
THOR: Text to Human-Object Interaction Diffusion via Relation Intervention
Mar 17, 2024



This paper addresses new methodologies to deal with the challenging task of generating dynamic Human-Object Interactions from textual descriptions (Text2HOI). While most existing works assume interactions with limited body parts or static objects, our task involves addressing the variation in human motion, the diversity of object shapes, and the semantic vagueness of object motion simultaneously. To tackle this, we propose a novel Text-guided Human-Object Interaction diffusion model with Relation Intervention (THOR). THOR is a cohesive diffusion model equipped with a relation intervention mechanism. In each diffusion step, we initiate text-guided human and object motion and then leverage human-object relations to intervene in object motion. This intervention enhances the spatial-temporal relations between humans and objects, with human-centric interaction representation providing additional guidance for synthesizing consistent motion from text. To achieve more reasonable and realistic results, interaction losses is introduced at different levels of motion granularity. Moreover, we construct Text-BEHAVE, a Text2HOI dataset that seamlessly integrates textual descriptions with the currently largest publicly available 3D HOI dataset. Both quantitative and qualitative experiments demonstrate the effectiveness of our proposed model.
NeRF-Det++: Incorporating Semantic Cues and Perspective-aware Depth Supervision for Indoor Multi-View 3D Detection
Feb 22, 2024



NeRF-Det has achieved impressive performance in indoor multi-view 3D detection by innovatively utilizing NeRF to enhance representation learning. Despite its notable performance, we uncover three decisive shortcomings in its current design, including semantic ambiguity, inappropriate sampling, and insufficient utilization of depth supervision. To combat the aforementioned problems, we present three corresponding solutions: 1) Semantic Enhancement. We project the freely available 3D segmentation annotations onto the 2D plane and leverage the corresponding 2D semantic maps as the supervision signal, significantly enhancing the semantic awareness of multi-view detectors. 2) Perspective-aware Sampling. Instead of employing the uniform sampling strategy, we put forward the perspective-aware sampling policy that samples densely near the camera while sparsely in the distance, more effectively collecting the valuable geometric clues. 3)Ordinal Residual Depth Supervision. As opposed to directly regressing the depth values that are difficult to optimize, we divide the depth range of each scene into a fixed number of ordinal bins and reformulate the depth prediction as the combination of the classification of depth bins as well as the regression of the residual depth values, thereby benefiting the depth learning process. The resulting algorithm, NeRF-Det++, has exhibited appealing performance in the ScanNetV2 and ARKITScenes datasets. Notably, in ScanNetV2, NeRF-Det++ outperforms the competitive NeRF-Det by +1.9% in mAP@0.25 and +3.5% in mAP@0.50$. The code will be publicly at https://github.com/mrsempress/NeRF-Detplusplus.