 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-target Divergence Hypothesis: Toward Understanding Domain Gaps in Cross-Modal Knowledge Distillation
Sep 04, 2024



Compared to single-modal knowledge distillation, cross-modal knowledge distillation faces more severe challenges due to domain gaps between modalities. Although various methods have proposed various solutions to overcome these challenges, there is still limited research on how domain gaps affect cross-modal knowledge distillation. This paper provides an in-depth analysis and evaluation of this issue. We first introduce the Non-Target Divergence Hypothesis (NTDH) to reveal the impact of domain gaps on cross-modal knowledge distillation. Our key finding is that domain gaps between modalities lead to distribution differences in non-target classes, and the smaller these differences, the better the performance of cross-modal knowledge distillation. Subsequently, based on Vapnik-Chervonenkis (VC) theory, we derive the upper and lower bounds of the approximation error for cross-modal knowledge distillation, thereby theoretically validating the NTDH. Finally, experiments on five cross-modal datasets further confirm the validity, generalisability, and applicability of the NTDH.
Hierarchical Point-based Active Learning for Semi-supervised Point Cloud Semantic Segmentation
Aug 22, 2023



Impressive performance on point cloud semantic segmentation has been achieved by fully-supervised methods with large amounts of labelled data. As it is labour-intensive to acquire large-scale point cloud data with point-wise labels, many attempts have been made to explore learning 3D point cloud segmentation with limited annotations. Active learning is one of the effective strategies to achieve this purpose but is still under-explored. The most recent methods of this kind measure the uncertainty of each pre-divided region for manual labelling but they suffer from redundant information and require additional efforts for region division. This paper aims at addressing this issue by developing a hierarchical point-based active learning strategy. Specifically, we measure the uncertainty for each point by a hierarchical minimum margin uncertainty module which considers the contextual information at multiple levels. Then, a feature-distance suppression strategy is designed to select important and representative points for manual labelling. Besides, to better exploit the unlabelled data, we build a semi-supervised segmentation framework based on our active strategy. Extensive experiments on the S3DIS and ScanNetV2 datasets demonstrate that the proposed framework achieves 96.5% and 100% performance of fully-supervised baseline with only 0.07% and 0.1% training data, respectively, outperforming the state-of-the-art weakly-supervised and active learning methods. The code will be available at https://github.com/SmiletoE/HPAL.
GenReg: Deep Generative Method for Fast Point Cloud Registration
Nov 23, 2021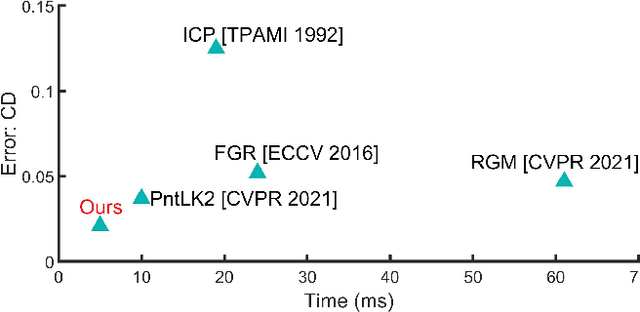
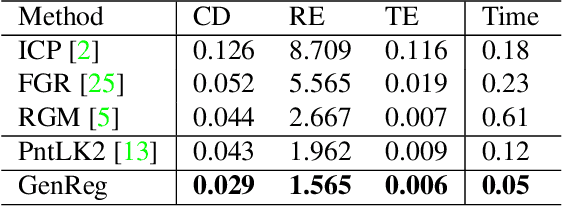


Accurate and efficient point cloud registration is a challenge because the noise and a large number of points impact the correspondence search. This challenge is still a remaining research problem since most of the existing methods rely on correspondence search. To solve this challenge, we propose a new data-driven registration algorithm by investigating deep generative neural networks to point cloud registration. Given two point clouds, the motivation is to generate the aligned point clouds directly, which is very useful in many applications like 3D matching and search. We design an end-to-end generative neural network for aligned point clouds generation to achieve this motivation, containing three novel components. Firstly, a point multi-perception layer (MLP) mixer (PointMixer) network is proposed to efficiently maintain both the global and local structure information at multiple levels from the self point clouds. Secondly, a feature interaction module is proposed to fuse information from cross point clouds. Thirdly, a parallel and differential sample consensus method is proposed to calculate the transformation matrix of the input point clouds based on the generated registration results. The proposed generative neural network is trained in a GAN framework by maintaining the data distribution and structure similarity. The experiments on both ModelNet40 and 7Scene datasets demonstrate that the proposed algorithm achieves state-of-the-art accuracy and efficiency. Notably, our method reduces $2\times$ in registration error (CD) and $12\times$ running time compared to the state-of-the-art correspondence-based algorithm.