 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Human Pose Editing Assessment via Layer-Selective MLLMs
Jan 15, 2026Text-guided human pose editing has gained significant traction in AIGC applications. However,it remains plagued by structural anomalies and generative artifacts. Existing evaluation metrics often isolate authenticity detection from quality assessment, failing to provide fine-grained insights into pose-specific inconsistencies. To address these limitations, we introduce HPE-Bench, a specialized benchmark comprising 1,700 standardized samples from 17 state-of-the-art editing models, offering both authenticity labels and multi-dimensional quality scores. Furthermore, we propose a unified framework based on layer-selective multimodal large language models (MLLMs). By employing contrastive LoRA tuning and a novel layer sensitivity analysis (LSA) mechanism, we identify the optimal feature layer for pose evaluation. Our framework achieves superior performance in both authenticity detection and multi-dimensional quality regression, effectively bridging the gap between forensic detection and quality assessment.
SingingBot: An Avatar-Driven System for Robotic Face Singing Performance
Jan 05, 2026Equipping robotic faces with singing capabilities is crucial for empathetic Human-Robot Interaction. However, existing robotic face driving research primarily focuses on conversations or mimicking static expressions, struggling to meet the high demands for continuous emotional expression and coherence in singing. To address this, we propose a novel avatar-driven framework for appealing robotic singing. We first leverage portrait video generation models embedded with extensive human priors to synthesize vivid singing avatars, providing reliable expression and emotion guidance. Subsequently, these facial features are transferred to the robot via semantic-oriented mapping functions that span a wide expression space. Furthermore, to quantitatively evaluate the emotional richness of robotic singing, we propose the Emotion Dynamic Range metric to measure the emotional breadth within the Valence-Arousal space, revealing that a broad emotional spectrum is crucial for appealing performances. Comprehensive experiments prove that our method achieves rich emotional expressions while maintaining lip-audio synchronization, significantly outperforming existing approaches.
POLAR: A Portrait OLAT Dataset and Generative Framework for Illumination-Aware Face Modeling
Dec 16, 2025Face relighting aims to synthesize realistic portraits under novel illumination while preserving identity and geometry. However, progress remains constrained by the limited availability of large-scale, physically consistent illumination data. To address this, we introduce POLAR, a large-scale and physically calibrated One-Light-at-a-Time (OLAT) dataset containing over 200 subjects captured under 156 lighting directions, multiple views, and diverse expressions. Building upon POLAR, we develop a flow-based generative model POLARNet that predicts per-light OLAT responses from a single portrait, capturing fine-grained and direction-aware illumination effects while preserving facial identity. Unlike diffusion or background-conditioned methods that rely on statistical or contextual cues, our formulation models illumination as a continuous, physically interpretable transformation between lighting states, enabling scalable and controllable relighting. Together, POLAR and POLARNet form a unified illumination learning framework that links real data, generative synthesis, and physically grounded relighting, establishing a self-sustaining "chicken-and-egg" cycle for scalable and reproducible portrait illumination. Our project page: https://rex0191.github.io/POLAR/.
MoRE: 3D Visual Geometry Reconstruction Meets Mixture-of-Experts
Oct 31, 2025Recent advances in language and vision have demonstrated that scaling up model capacity consistently improves performance across diverse tasks. In 3D visual geometry reconstruction, large-scale training has likewise proven effective for learning versatile representations. However, further scaling of 3D models is challenging due to the complexity of geometric supervision and the diversity of 3D data. To overcome these limitations, we propose MoRE, a dense 3D visual foundation model based on a Mixture-of-Experts (MoE) architecture that dynamically routes features to task-specific experts, allowing them to specialize in complementary data aspects and enhance both scalability and adaptability. Aiming to improve robustness under real-world conditions, MoRE incorporates a confidence-based depth refinement module that stabilizes and refines geometric estimation. In addition, it integrates dense semantic features with globally aligned 3D backbone representations for high-fidelity surface normal prediction. MoRE is further optimized with tailored loss functions to ensure robust learning across diverse inputs and multiple geometric tasks. Extensive experiments demonstrate that MoRE achieves state-of-the-art performance across multiple benchmarks and supports effective downstream applications without extra computation.
Scaling Up Occupancy-centric Driving Scene Generation: Dataset and Method
Oct 27, 2025



Driving scene generation is a critical domain for autonomous driving, enabling downstream applications, including perception and planning evaluation. Occupancy-centric methods have recently achieved state-of-the-art results by offering consistent conditioning across frames and modalities; however, their performance heavily depends on annotated occupancy data, which still remains scarce. To overcome this limitation, we curate Nuplan-Occ, the largest semantic occupancy dataset to date, constructed from the widely used Nuplan benchmark. Its scale and diversity facilitate not only large-scale generative modeling but also autonomous driving downstream applications. Based on this dataset, we develop a unified framework that jointly synthesizes high-quality semantic occupancy, multi-view videos, and LiDAR point clouds. Our approach incorporates a spatio-temporal disentangled architecture to support high-fidelity spatial expansion and temporal forecasting of 4D dynamic occupancy. To bridge modal gaps, we further propose two novel techniques: a Gaussian splatting-based sparse point map rendering strategy that enhances multi-view video generation, and a sensor-aware embedding strategy that explicitly models LiDAR sensor properties for realistic multi-LiDAR simulation. Extensive experiments demonstrate that our method achieves superior generation fidelity and scalability compared to existing approaches, and validates its practical value in downstream tasks. Repo: https://github.com/Arlo0o/UniScene-Unified-Occupancy-centric-Driving-Scene-Generation/tree/v2
FieldGen: From Teleoperated Pre-Manipulation Trajectories to Field-Guided Data Generation
Oct 23, 2025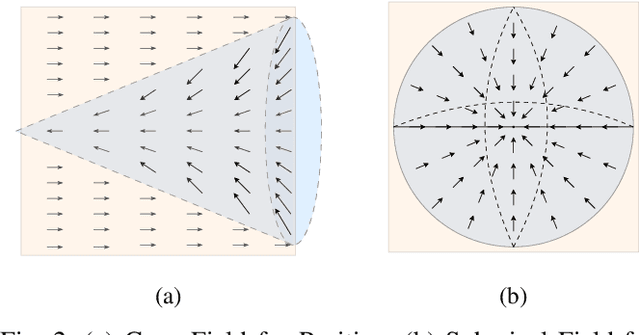

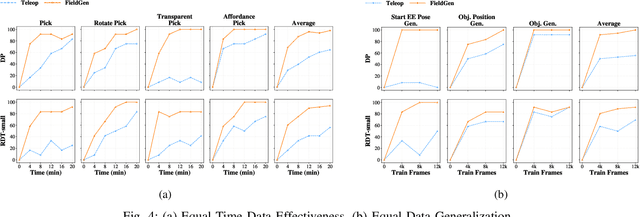

Large-scale and diverse datasets are vital for training robust robotic manipulation policies, yet existing data collection methods struggle to balance scale, diversity, and quality. Simulation offers scalability but suffers from sim-to-real gaps, while teleoperation yields high-quality demonstrations with limited diversity and high labor cost. We introduce FieldGen, a field-guided data generation framework that enables scalable, diverse, and high-quality real-world data collection with minimal human supervision. FieldGen decomposes manipulation into two stages: a pre-manipulation phase, allowing trajectory diversity, and a fine manipulation phase requiring expert precision. Human demonstrations capture key contact and pose information, after which an attraction field automatically generates diverse trajectories converging to successful configurations. This decoupled design combines scalable trajectory diversity with precise supervision. Moreover, FieldGen-Reward augments generated data with reward annotations to further enhance policy learning. Experiments demonstrate that policies trained with FieldGen achieve higher success rates and improved stability compared to teleoperation-based baselines, while significantly reducing human effort in long-term real-world data collection. Webpage is available at https://fieldgen.github.io/.
Expertise need not monopolize: Action-Specialized Mixture of Experts for Vision-Language-Action Learning
Oct 16, 2025Vision-Language-Action (VLA) models are experiencing rapid development and demonstrating promising capabilities in robotic manipulation tasks. However, scaling up VLA models presents several critical challenges: (1) Training new VLA models from scratch demands substantial computational resources and extensive datasets. Given the current scarcity of robot data, it becomes particularly valuable to fully leverage well-pretrained VLA model weights during the scaling process. (2) Real-time control requires carefully balancing model capacity with computational efficiency. To address these challenges, We propose AdaMoE, a Mixture-of-Experts (MoE) architecture that inherits pretrained weights from dense VLA models, and scales up the action expert by substituting the feedforward layers into sparsely activated MoE layers. AdaMoE employs a decoupling technique that decouples expert selection from expert weighting through an independent scale adapter working alongside the traditional router. This enables experts to be selected based on task relevance while contributing with independently controlled weights, allowing collaborative expert utilization rather than winner-takes-all dynamics. Our approach demonstrates that expertise need not monopolize. Instead, through collaborative expert utilization, we can achieve superior performance while maintaining computational efficiency. AdaMoE consistently outperforms the baseline model across key benchmarks, delivering performance gains of 1.8% on LIBERO and 9.3% on RoboTwin. Most importantly, a substantial 21.5% improvement in real-world experiments validates its practical effectiveness for robotic manipulation tasks.
Flow-Matching Guided Deep Unfolding for Hyperspectral Image Reconstruction
Oct 02, 2025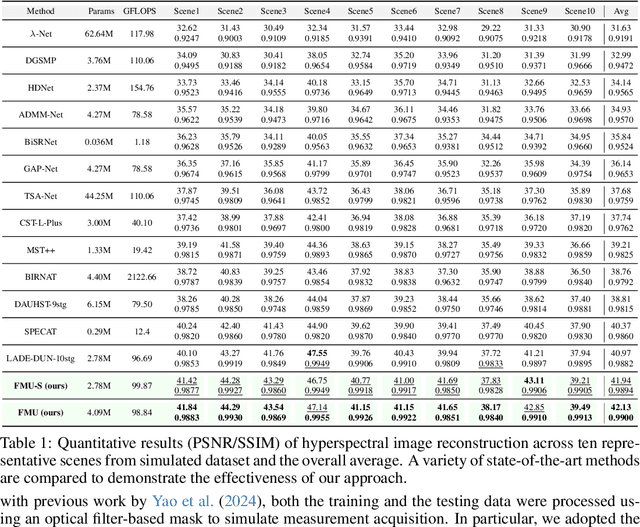

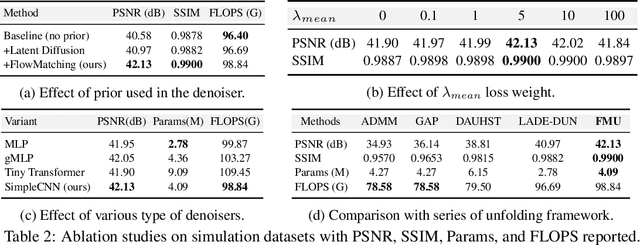
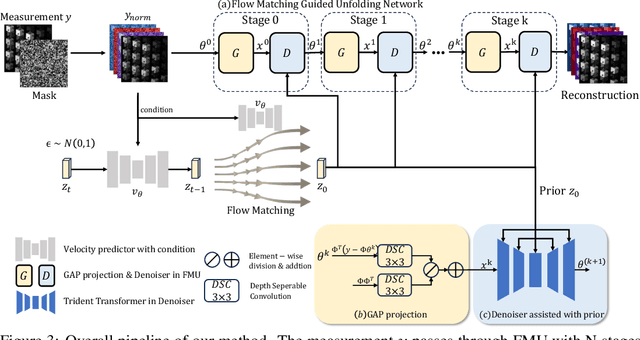
Hyperspectral imaging (HSI) provides rich spatial-spectral information but remains costly to acquire due to hardware limitations and the difficulty of reconstructing three-dimensional data from compressed measurements. Although compressive sensing systems such as CASSI improve efficiency, accurate reconstruction is still challenged by severe degradation and loss of fine spectral details. We propose the Flow-Matching-guided Unfolding network (FMU), which, to our knowledge, is the first to integrate flow matching into HSI reconstruction by embedding its generative prior within a deep unfolding framework. To further strengthen the learned dynamics, we introduce a mean velocity loss that enforces global consistency of the flow, leading to a more robust and accurate reconstruction. This hybrid design leverages the interpretability of optimization-based methods and the generative capacity of flow matching. Extensive experiments on both simulated and real datasets show that FMU significantly outperforms existing approaches in reconstruction quality. Code and models will be available at https://github.com/YiAi03/FMU.
FlashEdit: Decoupling Speed, Structure, and Semantics for Precise Image Editing
Sep 26, 2025Text-guided image editing with diffusion models has achieved remarkable quality but suffers from prohibitive latency, hindering real-world applications. We introduce FlashEdit, a novel framework designed to enable high-fidelity, real-time image editing. Its efficiency stems from three key innovations: (1) a One-Step Inversion-and-Editing (OSIE) pipeline that bypasses costly iterative processes; (2) a Background Shield (BG-Shield) technique that guarantees background preservation by selectively modifying features only within the edit region; and (3) a Sparsified Spatial Cross-Attention (SSCA) mechanism that ensures precise, localized edits by suppressing semantic leakage to the background. Extensive experiments demonstrate that FlashEdit maintains superior background consistency and structural integrity, while performing edits in under 0.2 seconds, which is an over 150$\times$ speedup compared to prior multi-step methods. Our code will be made publicly available at https://github.com/JunyiWuCode/FlashEdit.
Discrete Diffusion VLA: Bringing Discrete Diffusion to Action Decoding in Vision-Language-Action Policies
Aug 27, 2025Vision-Language-Action (VLA) models adapt large vision-language backbones to map images and instructions to robot actions. However, prevailing VLA decoders either generate actions autoregressively in a fixed left-to-right order or attach continuous diffusion or flow matching heads outside the backbone, demanding specialized training and iterative sampling that hinder a unified, scalable architecture. We present Discrete Diffusion VLA, a single-transformer policy that models discretized action chunks with discrete diffusion and is trained with the same cross-entropy objective as the VLM backbone. The design retains diffusion's progressive refinement paradigm while remaining natively compatible with the discrete token interface of VLMs. Our method achieves an adaptive decoding order that resolves easy action elements before harder ones and uses secondary remasking to revisit uncertain predictions across refinement rounds, which improves consistency and enables robust error correction. This unified decoder preserves pretrained vision language priors, supports parallel decoding, breaks the autoregressive bottleneck, and reduces the number of function evaluations. Discrete Diffusion VLA achieves 96.3% avg. SR on LIBERO, 71.2% visual matching on SimplerEnv Fractal and 49.3% overall on SimplerEnv Bridge, improving over both autoregressive and continuous diffusion baselines. These findings indicate that discrete-diffusion action decoder supports precise action modeling and consistent training, laying groundwork for scaling VLA to larger models and datasets.