 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoRE: 3D Visual Geometry Reconstruction Meets Mixture-of-Experts
Oct 31, 2025Recent advances in language and vision have demonstrated that scaling up model capacity consistently improves performance across diverse tasks. In 3D visual geometry reconstruction, large-scale training has likewise proven effective for learning versatile representations. However, further scaling of 3D models is challenging due to the complexity of geometric supervision and the diversity of 3D data. To overcome these limitations, we propose MoRE, a dense 3D visual foundation model based on a Mixture-of-Experts (MoE) architecture that dynamically routes features to task-specific experts, allowing them to specialize in complementary data aspects and enhance both scalability and adaptability. Aiming to improve robustness under real-world conditions, MoRE incorporates a confidence-based depth refinement module that stabilizes and refines geometric estimation. In addition, it integrates dense semantic features with globally aligned 3D backbone representations for high-fidelity surface normal prediction. MoRE is further optimized with tailored loss functions to ensure robust learning across diverse inputs and multiple geometric tasks. Extensive experiments demonstrate that MoRE achieves state-of-the-art performance across multiple benchmarks and supports effective downstream applications without extra computation.
Least Square Estimation Network for Depth Completion
Mar 07, 2022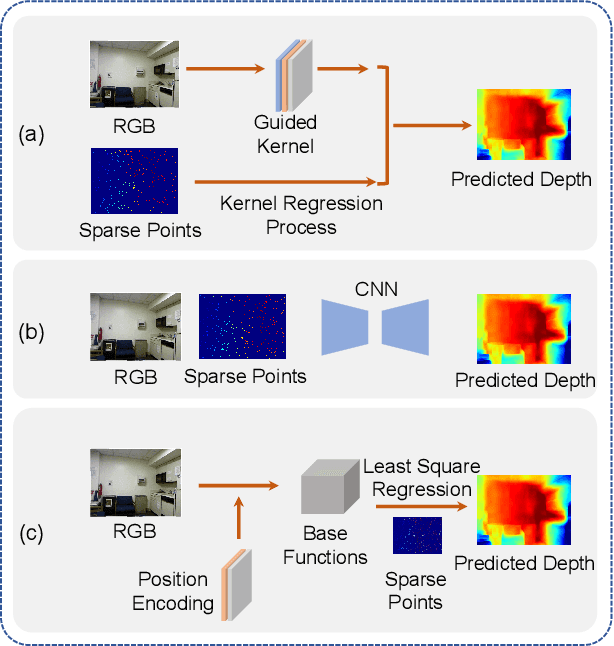
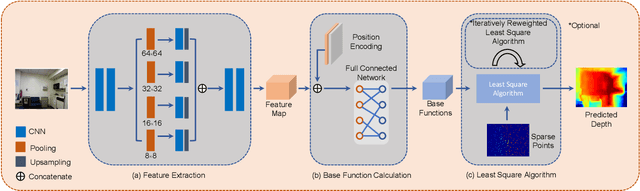
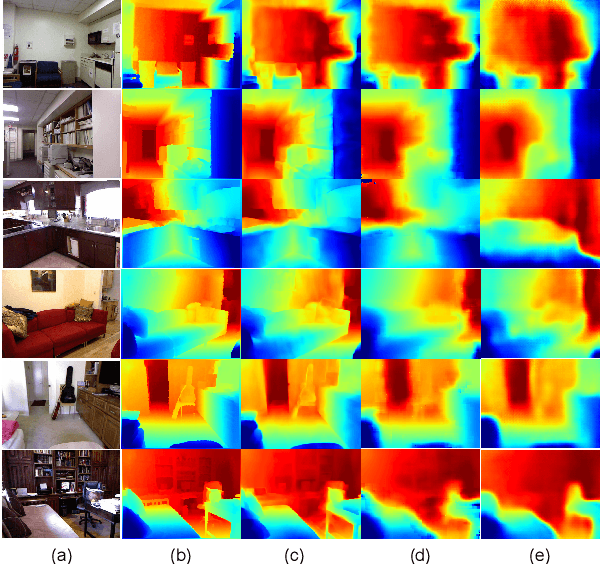
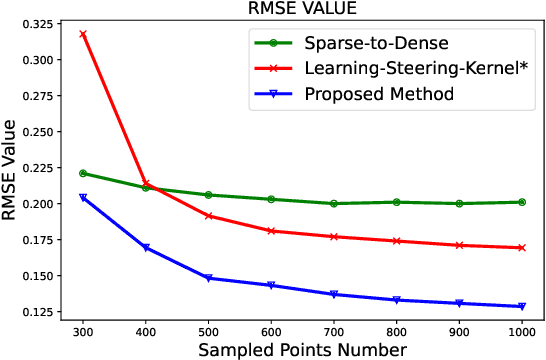
Depth completion is a fundamental task in computer vision and robotics research. Many previous works complete the dense depth map with neural networks directly but most of them are non-interpretable and can not generalize to different situations well. In this paper, we propose an effective image representation method for depth completion tasks. The input of our system is a monocular camera frame and the synchronous sparse depth map. The output of our system is a dense per-pixel depth map of the frame. First we use a neural network to transform each pixel into a feature vector, which we call base functions. Then we pick out the known pixels' base functions and their depth values. We use a linear least square algorithm to fit the base functions and the depth values. Then we get the weights estimated from the least square algorithm. Finally, we apply the weights to the whole image and predict the final depth map. Our method is interpretable so it can generalize well. Experiments show that our results beat the state-of-the-art on NYU-Depth-V2 dataset both in accuracy and runtime. Moreover, experiments show that our method can generalize well on different numbers of sparse points and different datasets.
Champion Team Paper: Dynamic Passing-Shooting Algorithm Based on CUDA of The RoboCup SSL 2019 Champion
Sep 17, 2019
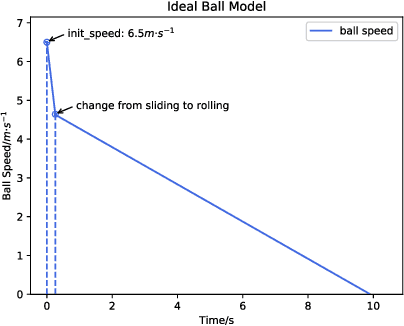
ZJUNlict became the Small Size League Champion of RoboCup 2019 with 6 victories and 1 tie for their 7 games. The overwhelming ability of ball-handling and passing allows ZJUNlict to greatly threaten its opponent and almost kept its goal clear without being threatened. This paper presents the core technology of its ball-handling and robot movement which consist of hardware optimization, dynamic passing and shooting strategy, and multi-agent cooperation and formation. We first describe the mechanical optimization on the placement of the capacitors, the redesign of the damping system of the dribbler and the electrical optimization on the replacement of the core chip. We then describe our passing point algorithm. The passing and shooting strategy can be separated into two different parts, where we search the passing point on SBIP-DPPS and evaluate the point based on the ball model. The statements and the conclusion should be supported by the performances and log of games on Small Size League RoboCup 2019.