 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Newton: A Concept-Driven Physical Law Discovery System without Prior Physical Knowledge
Apr 02, 2025Current limitations in human scientific discovery necessitate a new research paradigm. While advances in artificial intelligence (AI) offer a highly promising solution, enabling AI to emulate human-like scientific discovery remains an open challenge. To address this, we propose AI-Newton, a concept-driven discovery system capable of autonomously deriving physical laws from raw data -- without supervision or prior physical knowledge. The system integrates a knowledge base and knowledge representation centered on physical concepts, along with an autonomous discovery workflow. As a proof of concept, we apply AI-Newton to a large set of Newtonian mechanics problems. Given experimental data with noise, the system successfully rediscovers fundamental laws, including Newton's second law, energy conservation and law of gravitation, using autonomously defined concepts. This achievement marks a significant step toward AI-driven autonomous scientific discovery.
MedReason: Eliciting Factual Medical Reasoning Steps in LLMs via Knowledge Graphs
Apr 01, 2025

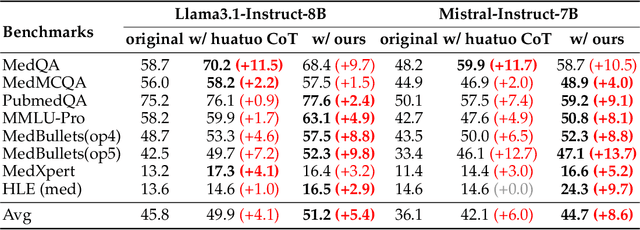
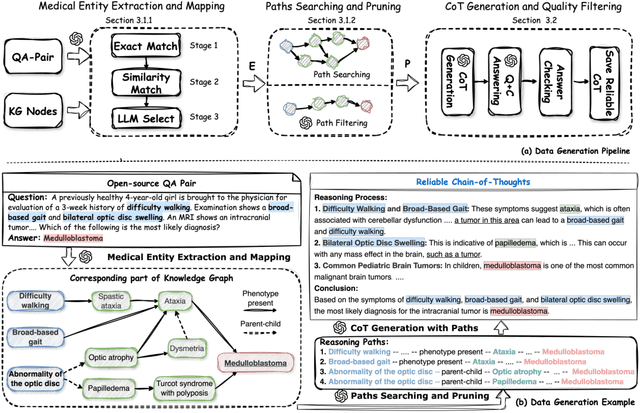
Medical tasks such as diagnosis and treatment planning require precise and complex reasoning, particularly in life-critical domains. Unlike mathematical reasoning, medical reasoning demands meticulous, verifiable thought processes to ensure reliability and accuracy. However, there is a notable lack of datasets that provide transparent, step-by-step reasoning to validate and enhance the medical reasoning ability of AI models. To bridge this gap, we introduce MedReason, a large-scale high-quality medical reasoning dataset designed to enable faithful and explainable medical problem-solving in large language models (LLMs). We utilize a structured medical knowledge graph (KG) to convert clinical QA pairs into logical chains of reasoning, or ``thinking paths'', which trace connections from question elements to answers via relevant KG entities. Each path is validated for consistency with clinical logic and evidence-based medicine. Our pipeline generates detailed reasoning for various medical questions from 7 medical datasets, resulting in a dataset of 32,682 question-answer pairs, each with detailed, step-by-step explanations. Experiments demonstrate that fine-tuning with our dataset consistently boosts medical problem-solving capabilities, achieving significant gains of up to 7.7% for DeepSeek-Ditill-8B. Our top-performing model, MedReason-8B, outperforms the Huatuo-o1-8B, a state-of-the-art medical reasoning model, by up to 4.2% on the clinical benchmark MedBullets. We also engage medical professionals from diverse specialties to assess our dataset's quality, ensuring MedReason offers accurate and coherent medical reasoning. Our data, models, and code will be publicly available.
Science Autonomy using Machine Learning for Astrobiology
Apr 01, 2025In recent decades, artificial intelligence (AI) including machine learning (ML) have become vital for space missions enabling rapid data processing, advanced pattern recognition, and enhanced insight extraction. These tools are especially valuable in astrobiology applications, where models must distinguish biotic patterns from complex abiotic backgrounds. Advancing the integration of autonomy through AI and ML into space missions is a complex challenge, and we believe that by focusing on key areas, we can make significant progress and offer practical recommendations for tackling these obstacles.
CAARMA: Class Augmentation with Adversarial Mixup Regularization
Mar 20, 2025



Speaker verification is a typical zero-shot learning task, where inference of unseen classes is performed by comparing embeddings of test instances to known examples. The models performing inference must hence naturally generate embeddings that cluster same-class instances compactly, while maintaining separation across classes. In order to learn to do so, they are typically trained on a large number of classes (speakers), often using specialized losses. However real-world speaker datasets often lack the class diversity needed to effectively learn this in a generalizable manner. We introduce CAARMA, a class augmentation framework that addresses this problem by generating synthetic classes through data mixing in the embedding space, expanding the number of training classes. To ensure the authenticity of the synthetic classes we adopt a novel adversarial refinement mechanism that minimizes categorical distinctions between synthetic and real classes. We evaluate CAARMA on multiple speaker verification tasks, as well as other representative zero-shot comparison-based speech analysis tasks and obtain consistent improvements: our framework demonstrates a significant improvement of 8\% over all baseline models. Code for CAARMA will be released.
Challenges and Trends in Egocentric Vision: A Survey
Mar 19, 2025With the rapid development of artificial intelligence technologies and wearable devices, egocentric vision understanding has emerged as a new and challenging research direction, gradually attracting widespread attention from both academia and industry. Egocentric vision captures visual and multimodal data through cameras or sensors worn on the human body, offering a unique perspective that simulates human visual experiences. This paper provides a comprehensive survey of the research on egocentric vision understanding, systematically analyzing the components of egocentric scenes and categorizing the tasks into four main areas: subject understanding, object understanding, environment understanding, and hybrid understanding. We explore in detail the sub-tasks within each category. We also summarize the main challenges and trends currently existing in the field. Furthermore, this paper presents an overview of high-quality egocentric vision datasets, offering valuable resources for future research. By summarizing the latest advancements, we anticipate the broad applications of egocentric vision technologies in fields such as augmented reality, virtual reality, and embodied intelligence, and propose future research directions based on the latest developments in the field.
MAST-Pro: Dynamic Mixture-of-Experts for Adaptive Segmentation of Pan-Tumors with Knowledge-Driven Prompts
Mar 18, 2025Accurate tumor segmentation is crucial for cancer diagnosis and treatment. While foundation models have advanced general-purpose segmentation, existing methods still struggle with: (1) limited incorporation of medical priors, (2) imbalance between generic and tumor-specific features, and (3) high computational costs for clinical adaptation. To address these challenges, we propose MAST-Pro (Mixture-of-experts for Adaptive Segmentation of pan-Tumors with knowledge-driven Prompts), a novel framework that integrates dynamic Mixture-of-Experts (D-MoE) and knowledge-driven prompts for pan-tumor segmentation. Specifically, text and anatomical prompts provide domain-specific priors, guiding tumor representation learning, while D-MoE dynamically selects experts to balance generic and tumor-specific feature learning, improving segmentation accuracy across diverse tumor types. To enhance efficiency, we employ Parameter-Efficient Fine-Tuning (PEFT), optimizing MAST-Pro with significantly reduced computational overhead. Experiments on multi-anatomical tumor datasets demonstrate that MAST-Pro outperforms state-of-the-art approaches, achieving up to a 5.20% improvement in average DSC while reducing trainable parameters by 91.04%, without compromising accuracy.
Flow-Aware Navigation of Magnetic Micro-Robots in Complex Fluids via PINN-Based Prediction
Mar 14, 2025While magnetic micro-robots have demonstrated significant potential across various applications, including drug delivery and microsurgery, the open issue of precise navigation and control in complex fluid environments is crucial for in vivo implementation. This paper introduces a novel flow-aware navigation and control strategy for magnetic micro-robots that explicitly accounts for the impact of fluid flow on their movement. First, the proposed method employs a Physics-Informed U-Net (PI-UNet) to refine the numerically predicted fluid velocity using local observations. Then, the predicted velocity is incorporated in a flow-aware A* path planning algorithm, ensuring efficient navigation while mitigating flow-induced disturbances. Finally, a control scheme is developed to compensate for the predicted fluid velocity, thereby optimizing the micro-robot's performance. A series of simulation studies and real-world experiments are conducted to validate the efficacy of the proposed approach. This method enhances both planning accuracy and control precision, expanding the potential applications of magnetic micro-robots in fluid-affected environments typical of many medical scenarios.
Robust Latent Matters: Boosting Image Generation with Sampling Error
Mar 11, 2025



Recent image generation schemes typically capture image distribution in a pre-constructed latent space relying on a frozen image tokenizer. Though the performance of tokenizer plays an essential role to the successful generation, its current evaluation metrics (e.g. rFID) fail to precisely assess the tokenizer and correlate its performance to the generation quality (e.g. gFID). In this paper, we comprehensively analyze the reason for the discrepancy of reconstruction and generation qualities in a discrete latent space, and, from which, we propose a novel plug-and-play tokenizer training scheme to facilitate latent space construction. Specifically, a latent perturbation approach is proposed to simulate sampling noises, i.e., the unexpected tokens sampled, from the generative process. With the latent perturbation, we further propose (1) a novel tokenizer evaluation metric, i.e., pFID, which successfully correlates the tokenizer performance to generation quality and (2) a plug-and-play tokenizer training scheme, which significantly enhances the robustness of tokenizer thus boosting the generation quality and convergence speed. Extensive benchmarking are conducted with 11 advanced discrete image tokenizers with 2 autoregressive generation models to validate our approach. The tokenizer trained with our proposed latent perturbation achieve a notable 1.60 gFID with classifier-free guidance (CFG) and 3.45 gFID without CFG with a $\sim$400M generator. Code: https://github.com/lxa9867/ImageFolder.
Human Cognition Inspired RAG with Knowledge Graph for Complex Problem Solving
Mar 09, 2025Large language models (LLMs) have demonstrated transformative potential across various domains, yet they face significant challenges in knowledge integration and complex problem reasoning, often leading to hallucinations and unreliable outputs. Retrieval-Augmented Generation (RAG) has emerged as a promising solution to enhance LLMs accuracy by incorporating external knowledge. However, traditional RAG systems struggle with processing complex relational information and multi-step reasoning, limiting their effectiveness in advanced problem-solving tasks. To address these limitations, we propose CogGRAG, a cognition inspired graph-based RAG framework, designed to improve LLMs performance in Knowledge Graph Question Answering (KGQA). Inspired by the human cognitive process of decomposing complex problems and performing self-verification, our framework introduces a three-stage methodology: decomposition, retrieval, and reasoning with self-verification. By integrating these components, CogGRAG enhances the accuracy of LLMs in complex problem solving. We conduct systematic experiments with three LLM backbones on four benchmark datasets, where CogGRAG outperforms the baselines.
Towards Ambiguity-Free Spatial Foundation Model: Rethinking and Decoupling Depth Ambiguity
Mar 08, 2025



Depth ambiguity is a fundamental challenge in spatial scene understanding, especially in transparent scenes where single-depth estimates fail to capture full 3D structure. Existing models, limited to deterministic predictions, overlook real-world multi-layer depth. To address this, we introduce a paradigm shift from single-prediction to multi-hypothesis spatial foundation models. We first present \texttt{MD-3k}, a benchmark exposing depth biases in expert and foundational models through multi-layer spatial relationship labels and new metrics. To resolve depth ambiguity, we propose Laplacian Visual Prompting (LVP), a training-free spectral prompting technique that extracts hidden depth from pre-trained models via Laplacian-transformed RGB inputs. By integrating LVP-inferred depth with standard RGB-based estimates, our approach elicits multi-layer depth without model retraining. Extensive experiments validate the effectiveness of LVP in zero-shot multi-layer depth estimation, unlocking more robust and comprehensive geometry-conditioned visual generation, 3D-grounded spatial reasoning, and temporally consistent video-level depth inference. Our benchmark and code will be available at https://github.com/Xiaohao-Xu/Ambiguity-in-Space.