 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Harness: Online Adaptation for Self-Improving Foundation Agents
May 11, 2026Coding harnesses such as Claude Code and OpenHands wrap foundation models with tools, memory, and planning, but no equivalent exists for embodied agents' long-horizon partial-observability decision-making. We first report our Gemini Plays Pokemon (GPP) experiments. With iterative human-in-the-loop harness refinement, GPP became the first AI system to complete Pokemon Blue, Yellow Legacy on hard mode, and Crystal without a lost battle. In the hardest stages, the agent itself began iterating on its strategy through long-context memory, surfacing emergent self-improvement signals alongside human-in-the-loop refinement. Continual Harness removes the human fully from this loop: a reset-free self-improving harness for embodied agents that formalizes and automates what we observed. Starting from only a minimal environment interface, the agent alternates between acting and refining its own prompt, sub-agents, skills, and memory, drawing on any past trajectory data. Prompt-optimization methods require episode resets; Continual Harness adapts online within a single run. On Pokemon Red and Emerald across frontier models, Continual Harness starting from scratch substantially reduces button-press cost relative to the minimalist baseline and recovers a majority of the gap to a hand-engineered expert harness, with capability-dependent gains, despite starting from the same raw interface with no curated knowledge, no hand-crafted tools, and no domain scaffolding. We then close the loop with the model itself: an online process-reward co-learning loop, in which an open-source agent's rollouts through the refining harness are relabeled by a frontier teacher and used to update the model, drives sustained in-game milestone progress on Pokemon Red without resetting the environment between training iterations.
The PokeAgent Challenge: Competitive and Long-Context Learning at Scale
Mar 17, 2026We present the PokeAgent Challenge, a large-scale benchmark for decision-making research built on Pokemon's multi-agent battle system and expansive role-playing game (RPG) environment. Partial observability, game-theoretic reasoning, and long-horizon planning remain open problems for frontier AI, yet few benchmarks stress all three simultaneously under realistic conditions. PokeAgent targets these limitations at scale through two complementary tracks: our Battling Track, which calls for strategic reasoning and generalization under partial observability in competitive Pokemon battles, and our Speedrunning Track, which requires long-horizon planning and sequential decision-making in the Pokemon RPG. Our Battling Track supplies a dataset of 20M+ battle trajectories alongside a suite of heuristic, RL, and LLM-based baselines capable of high-level competitive play. Our Speedrunning Track provides the first standardized evaluation framework for RPG speedrunning, including an open-source multi-agent orchestration system for modular, reproducible comparisons of harness-based LLM approaches. Our NeurIPS 2025 competition validates both the quality of our resources and the research community's interest in Pokemon, with over 100 teams competing across both tracks and winning solutions detailed in our paper. Participant submissions and our baselines reveal considerable gaps between generalist (LLM), specialist (RL), and elite human performance. Analysis against the BenchPress evaluation matrix shows that Pokemon battling is nearly orthogonal to standard LLM benchmarks, measuring capabilities not captured by existing suites and positioning Pokemon as an unsolved benchmark that can drive RL and LLM research forward. We transition to a living benchmark with a live leaderboard for Battling and self-contained evaluation for Speedrunning at https://pokeagentchallenge.com.
Automatic Generation of High-Performance RL Environments
Mar 12, 2026Translating complex reinforcement learning (RL) environments into high-performance implementations has traditionally required months of specialized engineering. We present a reusable recipe - a generic prompt template, hierarchical verification, and iterative agent-assisted repair - that produces semantically equivalent high-performance environments for <$10 in compute cost. We demonstrate three distinct workflows across five environments. Direct translation (no prior performance implementation exists): EmuRust (1.5x PPO speedup via Rust parallelism for a Game Boy emulator) and PokeJAX, the first GPU-parallel Pokemon battle simulator (500M SPS random action, 15.2M SPS PPO; 22,320x over the TypeScript reference). Translation verified against existing performance implementations: throughput parity with MJX (1.04x) and 5x over Brax at matched GPU batch sizes (HalfCheetah JAX); 42x PPO (Puffer Pong). New environment creation: TCGJax, the first deployable JAX Pokemon TCG engine (717K SPS random action, 153K SPS PPO; 6.6x over the Python reference), synthesized from a web-extracted specification. At 200M parameters, the environment overhead drops below 4% of training time. Hierarchical verification (property, interaction, and rollout tests) confirms semantic equivalence for all five environments; cross-backend policy transfer confirms zero sim-to-sim gap for all five environments. TCGJax, synthesized from a private reference absent from public repositories, serves as a contamination control for agent pretraining data concerns. The paper contains sufficient detail - including representative prompts, verification methodology, and complete results - that a coding agent could reproduce the translations directly from the manuscript.
GameDevBench: Evaluating Agentic Capabilities Through Game Development
Feb 11, 2026Despite rapid progress on coding agents, progress on their multimodal counterparts has lagged behind. A key challenge is the scarcity of evaluation testbeds that combine the complexity of software development with the need for deep multimodal understanding. Game development provides such a testbed as agents must navigate large, dense codebases while manipulating intrinsically multimodal assets such as shaders, sprites, and animations within a visual game scene. We present GameDevBench, the first benchmark for evaluating agents on game development tasks. GameDevBench consists of 132 tasks derived from web and video tutorials. Tasks require significant multimodal understanding and are complex -- the average solution requires over three times the amount of lines of code and file changes compared to prior software development benchmarks. Agents still struggle with game development, with the best agent solving only 54.5% of tasks. We find a strong correlation between perceived task difficulty and multimodal complexity, with success rates dropping from 46.9% on gameplay-oriented tasks to 31.6% on 2D graphics tasks. To improve multimodal capability, we introduce two simple image and video-based feedback mechanisms for agents. Despite their simplicity, these methods consistently improve performance, with the largest change being an increase in Claude Sonnet 4.5's performance from 33.3% to 47.7%. We release GameDevBench publicly to support further research into agentic game development.
PokéChamp: an Expert-level Minimax Language Agent
Mar 06, 2025We introduce Pok\'eChamp, a minimax agent powered by Large Language Models (LLMs) for Pok\'emon battles. Built on a general framework for two-player competitive games, Pok\'eChamp leverages the generalist capabilities of LLMs to enhance minimax tree search. Specifically, LLMs replace three key modules: (1) player action sampling, (2) opponent modeling, and (3) value function estimation, enabling the agent to effectively utilize gameplay history and human knowledge to reduce the search space and address partial observability. Notably, our framework requires no additional LLM training. We evaluate Pok\'eChamp in the popular Gen 9 OU format. When powered by GPT-4o, it achieves a win rate of 76% against the best existing LLM-based bot and 84% against the strongest rule-based bot, demonstrating its superior performance. Even with an open-source 8-billion-parameter Llama 3.1 model, Pok\'eChamp consistently outperforms the previous best LLM-based bot, Pok\'ellmon powered by GPT-4o, with a 64% win rate. Pok\'eChamp attains a projected Elo of 1300-1500 on the Pok\'emon Showdown online ladder, placing it among the top 30%-10% of human players. In addition, this work compiles the largest real-player Pok\'emon battle dataset, featuring over 3 million games, including more than 500k high-Elo matches. Based on this dataset, we establish a series of battle benchmarks and puzzles to evaluate specific battling skills. We further provide key updates to the local game engine. We hope this work fosters further research that leverage Pok\'emon battle as benchmark to integrate LLM technologies with game-theoretic algorithms addressing general multiagent problems. Videos, code, and dataset available at https://sites.google.com/view/pokechamp-llm.
FightLadder: A Benchmark for Competitive Multi-Agent Reinforcement Learning
Jun 04, 2024



Recent advances in reinforcement learning (RL) heavily rely on a variety of well-designed benchmarks, which provide environmental platforms and consistent criteria to evaluate existing and novel algorithms. Specifically, in multi-agent RL (MARL), a plethora of benchmarks based on cooperative games have spurred the development of algorithms that improve the scalability of cooperative multi-agent systems. However, for the competitive setting, a lightweight and open-sourced benchmark with challenging gaming dynamics and visual inputs has not yet been established. In this work, we present FightLadder, a real-time fighting game platform, to empower competitive MARL research. Along with the platform, we provide implementations of state-of-the-art MARL algorithms for competitive games, as well as a set of evaluation metrics to characterize the performance and exploitability of agents. We demonstrate the feasibility of this platform by training a general agent that consistently defeats 12 built-in characters in single-player mode, and expose the difficulty of training a non-exploitable agent without human knowledge and demonstrations in two-player mode. FightLadder provides meticulously designed environments to address critical challenges in competitive MARL research, aiming to catalyze a new era of discovery and advancement in the field. Videos and code at https://sites.google.com/view/fightladder/home.
On the Role of Emergent Communication for Social Learning in Multi-Agent Reinforcement Learning
Feb 28, 2023Explicit communication among humans is key to coordinating and learning. Social learning, which uses cues from experts, can greatly benefit from the usage of explicit communication to align heterogeneous policies, reduce sample complexity, and solve partially observable tasks. Emergent communication, a type of explicit communication, studies the creation of an artificial language to encode a high task-utility message directly from data. However, in most cases, emergent communication sends insufficiently compressed messages with little or null information, which also may not be understandable to a third-party listener. This paper proposes an unsupervised method based on the information bottleneck to capture both referential complexity and task-specific utility to adequately explore sparse social communication scenarios in multi-agent reinforcement learning (MARL). We show that our model is able to i) develop a natural-language-inspired lexicon of messages that is independently composed of a set of emergent concepts, which span the observations and intents with minimal bits, ii) develop communication to align the action policies of heterogeneous agents with dissimilar feature models, and iii) learn a communication policy from watching an expert's action policy, which we term `social shadowing'.
Towards True Lossless Sparse Communication in Multi-Agent Systems
Nov 30, 2022



Communication enables agents to cooperate to achieve their goals. Learning when to communicate, i.e., sparse (in time) communication, and whom to message is particularly important when bandwidth is limited. Recent work in learning sparse individualized communication, however, suffers from high variance during training, where decreasing communication comes at the cost of decreased reward, particularly in cooperative tasks. We use the information bottleneck to reframe sparsity as a representation learning problem, which we show naturally enables lossless sparse communication at lower budgets than prior art. In this paper, we propose a method for true lossless sparsity in communication via Information Maximizing Gated Sparse Multi-Agent Communication (IMGS-MAC). Our model uses two individualized regularization objectives, an information maximization autoencoder and sparse communication loss, to create informative and sparse communication. We evaluate the learned communication `language' through direct causal analysis of messages in non-sparse runs to determine the range of lossless sparse budgets, which allow zero-shot sparsity, and the range of sparse budgets that will inquire a reward loss, which is minimized by our learned gating function with few-shot sparsity. To demonstrate the efficacy of our results, we experiment in cooperative multi-agent tasks where communication is essential for success. We evaluate our model with both continuous and discrete messages. We focus our analysis on a variety of ablations to show the effect of message representations, including their properties, and lossless performance of our model.
Probe-Based Interventions for Modifying Agent Behavior
Jan 26, 2022Neural nets are powerful function approximators, but the behavior of a given neural net, once trained, cannot be easily modified. We wish, however, for people to be able to influence neural agents' actions despite the agents never training with humans, which we formalize as a human-assisted decision-making problem. Inspired by prior art initially developed for model explainability, we develop a method for updating representations in pre-trained neural nets according to externally-specified properties. In experiments, we show how our method may be used to improve human-agent team performance for a variety of neural networks from image classifiers to agents in multi-agent reinforcement learning settings.
The Enforcers: Consistent Sparse-Discrete Methods for Constraining Informative Emergent Communication
Jan 19, 2022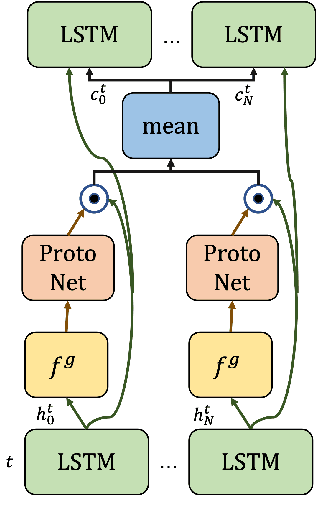
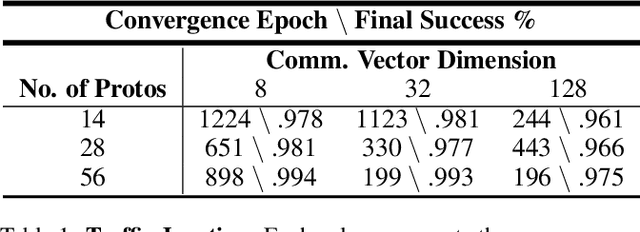
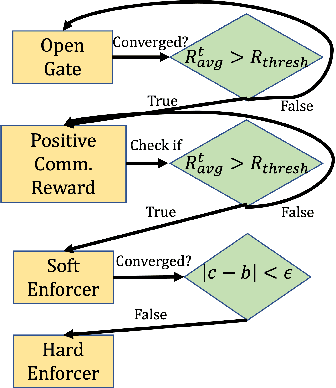
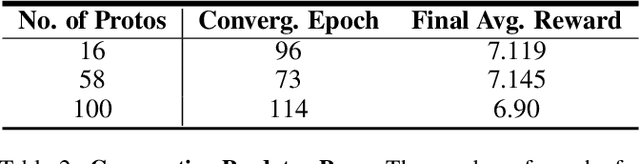
Communication enables agents to cooperate to achieve their goals. Learning when to communicate, i.e. sparse communication, is particularly important where bandwidth is limited, in situations where agents interact with humans, in partially observable scenarios where agents must convey information unavailable to others, and in non-cooperative scenarios where agents may hide information to gain a competitive advantage. Recent work in learning sparse communication, however, suffers from high variance training where, the price of decreasing communication is a decrease in reward, particularly in cooperative tasks. Sparse communications are necessary to match agent communication to limited human bandwidth. Humans additionally communicate via discrete linguistic tokens, previously shown to decrease task performance when compared to continuous communication vectors. This research addresses the above issues by limiting the loss in reward of decreasing communication and eliminating the penalty for discretization. In this work, we successfully constrain training using a learned gate to regulate when to communicate while using discrete prototypes that reflect what to communicate for cooperative tasks with partial observability. We provide two types of "Enforcers" for hard and soft budget constraints and present results of communication under different budgets. We show that our method satisfies constraints while yielding the same performance as comparable, unconstrained methods.