 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHIPPO: Accelerating Video Large Language Models Inference via Holistic-aware Parallel Speculative Decoding
Jan 13, 2026Speculative decoding (SD) has emerged as a promising approach to accelerate LLM inference without sacrificing output quality. Existing SD methods tailored for video-LLMs primarily focus on pruning redundant visual tokens to mitigate the computational burden of massive visual inputs. However, existing methods do not achieve inference acceleration comparable to text-only LLMs. We observe from extensive experiments that this phenomenon mainly stems from two limitations: (i) their pruning strategies inadequately preserve visual semantic tokens, degrading draft quality and acceptance rates; (ii) even with aggressive pruning (e.g., 90% visual tokens removed), the draft model's remaining inference cost limits overall speedup. To address these limitations, we propose HIPPO, a general holistic-aware parallel speculative decoding framework. Specifically, HIPPO proposes (i) a semantic-aware token preservation method, which fuses global attention scores with local visual semantics to retain semantic information at high pruning ratios; (ii) a video parallel SD algorithm that decouples and overlaps draft generation and target verification phases. Experiments on four video-LLMs across six benchmarks demonstrate HIPPO's effectiveness, yielding up to 3.51x speedup compared to vanilla auto-regressive decoding.
MENTOR: A Metacognition-Driven Self-Evolution Framework for Uncovering and Mitigating Implicit Risks in LLMs on Domain Tasks
Nov 10, 2025Ensuring the safety and value alignment of large language models (LLMs) is critical for their deployment. Current alignment efforts primarily target explicit risks such as bias, hate speech, and violence. However, they often fail to address deeper, domain-specific implicit risks and lack a flexible, generalizable framework applicable across diverse specialized fields. Hence, we proposed MENTOR: A MEtacognition-driveN self-evoluTion framework for uncOvering and mitigating implicit Risks in LLMs on Domain Tasks. To address the limitations of labor-intensive human evaluation, we introduce a novel metacognitive self-assessment tool. This enables LLMs to reflect on potential value misalignments in their responses using strategies like perspective-taking and consequential thinking. We also release a supporting dataset of 9,000 risk queries spanning education, finance, and management to enhance domain-specific risk identification. Subsequently, based on the outcomes of metacognitive reflection, the framework dynamically generates supplementary rule knowledge graphs that extend predefined static rule trees. This enables models to actively apply validated rules to future similar challenges, establishing a continuous self-evolution cycle that enhances generalization by reducing maintenance costs and inflexibility of static systems. Finally, we employ activation steering during inference to guide LLMs in following the rules, a cost-effective method to robustly enhance enforcement across diverse contexts. Experimental results show MENTOR's effectiveness: In defensive testing across three vertical domains, the framework substantially reduces semantic attack success rates, enabling a new level of implicit risk mitigation for LLMs. Furthermore, metacognitive assessment not only aligns closely with baseline human evaluators but also delivers more thorough and insightful analysis of LLMs value alignment.
SPEAR: A Unified SSL Framework for Learning Speech and Audio Representations
Oct 29, 2025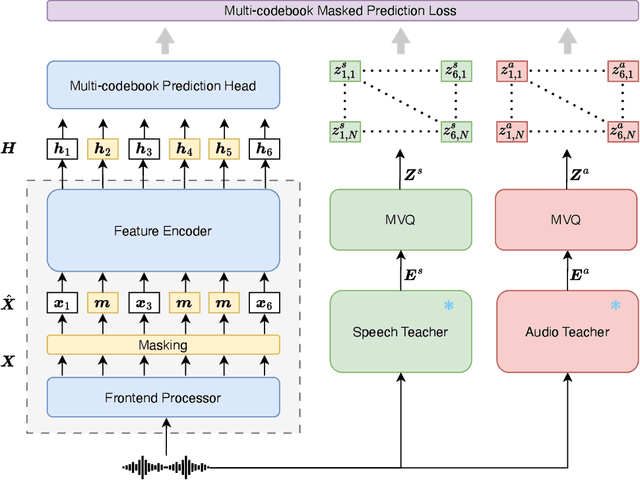



Self-Supervised Learning (SSL) excels at learning generic representations of acoustic signals, yet prevailing methods remain domain-specific, tailored to either speech or general audio, hindering the development of a unified representation model with a comprehensive capability over both domains. To address this, we present SPEAR (SPEech and Audio Representations), the first SSL framework to successfully learn unified speech and audio representations from a mixture of speech and audio data. SPEAR proposes a unified pre-training objective based on masked prediction of fine-grained discrete tokens for both speech and general audio. These tokens are derived from continuous speech and audio representations using a Multi-codebook Vector Quantisation (MVQ) method, retaining rich acoustic detail essential for modelling both speech and complex audio events. SPEAR is applied to pre-train both single-domain and unified speech-and-audio SSL models. Our speech-domain model establishes a new state-of-the-art on the SUPERB benchmark, a speech processing benchmark for SSL models, matching or surpassing the highly competitive WavLM Large on 12 out of 15 tasks with the same pre-training corpora and a similar model size. Crucially, our unified model learns complementary features and demonstrates comprehensive capabilities across two major benchmarks, SUPERB and HEAR, for evaluating audio representations. By further scaling up the model size and pre-training data, we present a unified model with 600M parameters that excels in both domains, establishing it as one of the most powerful and versatile open-source SSL models for auditory understanding. The inference code and pre-trained models will be made publicly available.
Speaker Anonymisation for Speech-based Suicide Risk Detection
Sep 26, 2025



Adolescent suicide is a critical global health issue, and speech provides a cost-effective modality for automatic suicide risk detection. Given the vulnerable population, protecting speaker identity is particularly important, as speech itself can reveal personally identifiable information if the data is leaked or maliciously exploited. This work presents the first systematic study of speaker anonymisation for speech-based suicide risk detection. A broad range of anonymisation methods are investigated, including techniques based on traditional signal processing, neural voice conversion, and speech synthesis. A comprehensive evaluation framework is built to assess the trade-off between protecting speaker identity and preserving information essential for suicide risk detection. Results show that combining anonymisation methods that retain complementary information yields detection performance comparable to that of original speech, while achieving protection of speaker identity for vulnerable populations.
Towards Cross-Task Suicide Risk Detection via Speech LLM
Sep 26, 2025Suicide risk among adolescents remains a critical public health concern, and speech provides a non-invasive and scalable approach for its detection. Existing approaches, however, typically focus on one single speech assessment task at a time. This paper, for the first time, investigates cross-task approaches that unify diverse speech suicide risk assessment tasks within a single model. Specifically, we leverage a speech large language model as the backbone and incorporate a mixture of DoRA experts (MoDE) approach to capture complementary cues across diverse assessments dynamically. The proposed approach was tested on 1,223 participants across ten spontaneous speech tasks. Results demonstrate that MoDE not only achieves higher detection accuracy than both single-task specialised models and conventional joint-tuning approaches, but also provides better confidence calibration, which is especially important for medical detection tasks.
Forget What's Sensitive, Remember What Matters: Token-Level Differential Privacy in Memory Sculpting for Continual Learning
Sep 16, 2025



Continual Learning (CL) models, while adept at sequential knowledge acquisition, face significant and often overlooked privacy challenges due to accumulating diverse information. Traditional privacy methods, like a uniform Differential Privacy (DP) budget, indiscriminately protect all data, leading to substantial model utility degradation and hindering CL deployment in privacy-sensitive areas. To overcome this, we propose a privacy-enhanced continual learning (PeCL) framework that forgets what's sensitive and remembers what matters. Our approach first introduces a token-level dynamic Differential Privacy strategy that adaptively allocates privacy budgets based on the semantic sensitivity of individual tokens. This ensures robust protection for private entities while minimizing noise injection for non-sensitive, general knowledge. Second, we integrate a privacy-guided memory sculpting module. This module leverages the sensitivity analysis from our dynamic DP mechanism to intelligently forget sensitive information from the model's memory and parameters, while explicitly preserving the task-invariant historical knowledge crucial for mitigating catastrophic forgetting. Extensive experiments show that PeCL achieves a superior balance between privacy preserving and model utility, outperforming baseline models by maintaining high accuracy on previous tasks while ensuring robust privacy.
Task-Core Memory Management and Consolidation for Long-term Continual Learning
May 15, 2025



In this paper, we focus on a long-term continual learning (CL) task, where a model learns sequentially from a stream of vast tasks over time, acquiring new knowledge while retaining previously learned information in a manner akin to human learning. Unlike traditional CL settings, long-term CL involves handling a significantly larger number of tasks, which exacerbates the issue of catastrophic forgetting. Our work seeks to address two critical questions: 1) How do existing CL methods perform in the context of long-term CL? and 2) How can we mitigate the catastrophic forgetting that arises from prolonged sequential updates? To tackle these challenges, we propose a novel framework inspired by human memory mechanisms for long-term continual learning (Long-CL). Specifically, we introduce a task-core memory management strategy to efficiently index crucial memories and adaptively update them as learning progresses. Additionally, we develop a long-term memory consolidation mechanism that selectively retains hard and discriminative samples, ensuring robust knowledge retention. To facilitate research in this area, we construct and release two multi-modal and textual benchmarks, MMLongCL-Bench and TextLongCL-Bench, providing a valuable resource for evaluating long-term CL approaches. Experimental results show that Long-CL outperforms the previous state-of-the-art by 7.4\% and 6.5\% AP on the two benchmarks, respectively, demonstrating the effectiveness of our approach.
Meta-Learning Driven Lightweight Phase Shift Compression for IRS-Assisted Wireless Systems
May 07, 2025



The phase shift information (PSI) overhead poses a critical challenge to enabling real-time intelligent reflecting surface (IRS)-assisted wireless systems, particularly under dynamic and resource-constrained conditions. In this paper, we propose a lightweight PSI compression framework, termed meta-learning-driven compression and reconstruction network (MCRNet). By leveraging a few-shot adaptation strategy via model-agnostic meta-learning (MAML), MCRNet enables rapid generalization across diverse IRS configurations with minimal retraining overhead. Furthermore, a novel depthwise convolutional gating (DWCG) module is incorporated into the decoder to achieve adaptive local feature modulation with low computational cost, significantly improving decoding efficiency. Extensive simulations demonstrate that MCRNet achieves competitive normalized mean square error performance compared to state-of-the-art baselines across various compression ratios, while substantially reducing model size and inference latency. These results validate the effectiveness of the proposed asymmetric architecture and highlight the practical scalability and real-time applicability of MCRNet for dynamic IRS-assisted wireless deployments.
MobiLLM: Enabling LLM Fine-Tuning on the Mobile Device via Server Assisted Side Tuning
Feb 27, 2025



Large Language Model (LLM) at mobile devices and its potential applications never fail to fascinate. However, on-device LLM fine-tuning poses great challenges due to extremely high memory requirements and slow training speeds. Even with parameter-efficient fine-tuning (PEFT) methods that update only a small subset of parameters, resource-constrained mobile devices cannot afford them. In this paper, we propose MobiLLM to enable memory-efficient transformer LLM fine-tuning on a mobile device via server-assisted side-tuning. Particularly, MobiLLM allows the resource-constrained mobile device to retain merely a frozen backbone model, while offloading the memory and computation-intensive backpropagation of a trainable side-network to a high-performance server. Unlike existing fine-tuning methods that keep trainable parameters inside the frozen backbone, MobiLLM separates a set of parallel adapters from the backbone to create a backpropagation bypass, involving only one-way activation transfers from the mobile device to the server with low-width quantization during forward propagation. In this way, the data never leaves the mobile device while the device can remove backpropagation through the local backbone model and its forward propagation can be paralyzed with the server-side execution. Thus, MobiLLM preserves data privacy while significantly reducing the memory and computational burdens for LLM fine-tuning. Through extensive experiments, we demonstrate that MobiLLM can enable a resource-constrained mobile device, even a CPU-only one, to fine-tune LLMs and significantly reduce convergence time and memory usage.
Terahertz Integrated Sensing and Communication-Empowered UAVs in 6G: A Transceiver Design Perspective
Feb 07, 2025Due to their high maneuverability, flexible deployment, and low cost, unmanned aerial vehicles (UAVs) are expected to play a pivotal role in not only communication, but also sensing. Especially by exploiting the ultra-wide bandwidth of terahertz (THz) bands, integrated sensing and communication (ISAC)-empowered UAV has been a promising technology of 6G space-air-ground integrated networks. In this article, we systematically investigate the key techniques and essential obstacles for THz-ISAC-empowered UAV from a transceiver design perspective, with the highlight of its major challenges and key technologies. Specifically, we discuss the THz-ISAC-UAV wireless propagation environment, based on which several channel characteristics for communication and sensing are revealed. We point out the transceiver payload design peculiarities for THz-ISAC-UAV from the perspective of antenna design, radio frequency front-end, and baseband signal processing. To deal with the specificities faced by the payload, we shed light on three key technologies, i.e., hybrid beamforming for ultra-massive MIMO-ISAC, power-efficient THz-ISAC waveform design, as well as communication and sensing channel state information acquisition, and extensively elaborate their concepts and key issues. More importantly, future research directions and associated open problems are presented, which may unleash the full potential of THz-ISAC-UAV for 6G wireless networks.