 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPEAR: A Unified SSL Framework for Learning Speech and Audio Representations
Oct 29, 2025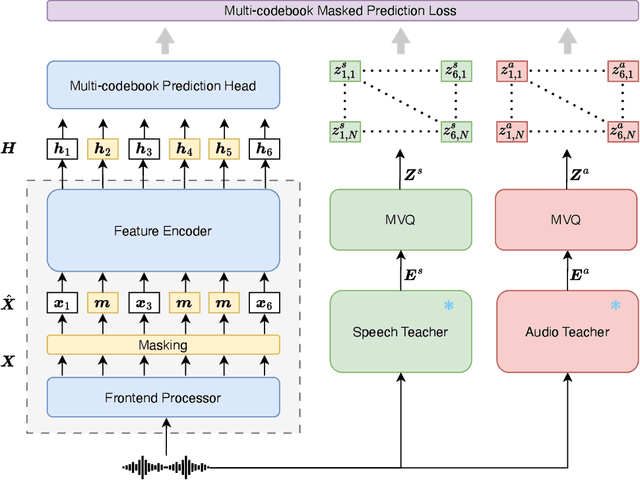



Self-Supervised Learning (SSL) excels at learning generic representations of acoustic signals, yet prevailing methods remain domain-specific, tailored to either speech or general audio, hindering the development of a unified representation model with a comprehensive capability over both domains. To address this, we present SPEAR (SPEech and Audio Representations), the first SSL framework to successfully learn unified speech and audio representations from a mixture of speech and audio data. SPEAR proposes a unified pre-training objective based on masked prediction of fine-grained discrete tokens for both speech and general audio. These tokens are derived from continuous speech and audio representations using a Multi-codebook Vector Quantisation (MVQ) method, retaining rich acoustic detail essential for modelling both speech and complex audio events. SPEAR is applied to pre-train both single-domain and unified speech-and-audio SSL models. Our speech-domain model establishes a new state-of-the-art on the SUPERB benchmark, a speech processing benchmark for SSL models, matching or surpassing the highly competitive WavLM Large on 12 out of 15 tasks with the same pre-training corpora and a similar model size. Crucially, our unified model learns complementary features and demonstrates comprehensive capabilities across two major benchmarks, SUPERB and HEAR, for evaluating audio representations. By further scaling up the model size and pre-training data, we present a unified model with 600M parameters that excels in both domains, establishing it as one of the most powerful and versatile open-source SSL models for auditory understanding. The inference code and pre-trained models will be made publicly available.
Discrete Audio Tokens: More Than a Survey!
Jun 12, 2025Discrete audio tokens are compact representations that aim to preserve perceptual quality, phonetic content, and speaker characteristics while enabling efficient storage and inference, as well as competitive performance across diverse downstream tasks.They provide a practical alternative to continuous features, enabling the integration of speech and audio into modern large language models (LLMs). As interest in token-based audio processing grows, various tokenization methods have emerged, and several surveys have reviewed the latest progress in the field. However, existing studies often focus on specific domains or tasks and lack a unified comparison across various benchmarks. This paper presents a systematic review and benchmark of discrete audio tokenizers, covering three domains: speech, music, and general audio. We propose a taxonomy of tokenization approaches based on encoder-decoder, quantization techniques, training paradigm, streamability, and application domains. We evaluate tokenizers on multiple benchmarks for reconstruction, downstream performance, and acoustic language modeling, and analyze trade-offs through controlled ablation studies. Our findings highlight key limitations, practical considerations, and open challenges, providing insight and guidance for future research in this rapidly evolving area. For more information, including our main results and tokenizer database, please refer to our website: https://poonehmousavi.github.io/dates-website/.
SkillAggregation: Reference-free LLM-Dependent Aggregation
Oct 14, 2024Large Language Models (LLMs) are increasingly used to assess NLP tasks due to their ability to generate human-like judgments. Single LLMs were used initially, however, recent work suggests using multiple LLMs as judges yields improved performance. An important step in exploiting multiple judgements is the combination stage, aggregation. Existing methods in NLP either assign equal weight to all LLM judgments or are designed for specific tasks such as hallucination detection. This work focuses on aggregating predictions from multiple systems where no reference labels are available. A new method called SkillAggregation is proposed, which learns to combine estimates from LLM judges without needing additional data or ground truth. It extends the Crowdlayer aggregation method, developed for image classification, to exploit the judge estimates during inference. The approach is compared to a range of standard aggregation methods on HaluEval-Dialogue, TruthfulQA and Chatbot Arena tasks. SkillAggregation outperforms Crowdlayer on all tasks, and yields the best performance over all approaches on the majority of tasks.
MT2KD: Towards A General-Purpose Encoder for Speech, Speaker, and Audio Events
Sep 25, 2024



With the advances in deep learning, the performance of end-to-end (E2E) single-task models for speech and audio processing has been constantly improving. However, it is still challenging to build a general-purpose model with high performance on multiple tasks, since different speech and audio processing tasks usually require different training data, input features, or model architectures to achieve optimal performance. In this work, MT2KD, a novel two-stage multi-task learning framework is proposed to build a general-purpose speech and audio encoder that jointly performs three fundamental tasks: automatic speech recognition (ASR), audio tagging (AT) and speaker verification (SV). In the first stage, multi-teacher knowledge distillation (KD) is applied to align the feature spaces of three single-task high-performance teacher encoders into a single student encoder using the same unlabelled data. In the second stage, multi-task supervised fine-tuning is carried out by initialising the model from the first stage and training on the separate labelled data of each single task. Experiments demonstrate that the proposed multi-task training pipeline significantly outperforms a baseline model trained with multi-task learning from scratch. The final system achieves good performance on ASR, AT and SV: with less than 4% relative word-error-rate increase on ASR, only 1.9 lower mean averaged precision on AT and 0.23% absolute higher equal error rate on SV compared to the best-performing single-task encoders, using only a 66M total model parameters.
CrossCheckGPT: Universal Hallucination Ranking for Multimodal Foundation Models
May 22, 2024Multimodal foundation models are prone to hallucination, generating outputs that either contradict the input or are not grounded by factual information. Given the diversity in architectures, training data and instruction tuning techniques, there can be large variations in systems' susceptibility to hallucinations. To assess system hallucination robustness, hallucination ranking approaches have been developed for specific tasks such as image captioning, question answering, summarization, or biography generation. However, these approaches typically compare model outputs to gold-standard references or labels, limiting hallucination benchmarking for new domains. This work proposes "CrossCheckGPT", a reference-free universal hallucination ranking for multimodal foundation models. The core idea of CrossCheckGPT is that the same hallucinated content is unlikely to be generated by different independent systems, hence cross-system consistency can provide meaningful and accurate hallucination assessment scores. CrossCheckGPT can be applied to any model or task, provided that the information consistency between outputs can be measured through an appropriate distance metric. Focusing on multimodal large language models that generate text, we explore two information consistency measures: CrossCheck-explicit and CrossCheck-implicit. We showcase the applicability of our method for hallucination ranking across various modalities, namely the text, image, and audio-visual domains. Further, we propose the first audio-visual hallucination benchmark, "AVHalluBench", and illustrate the effectiveness of CrossCheckGPT, achieving correlations of 98% and 89% with human judgements on MHaluBench and AVHalluBench, respectively.
Graph Neural Networks for Contextual ASR with the Tree-Constrained Pointer Generator
May 30, 2023The incorporation of biasing words obtained through contextual knowledge is of paramount importance in automatic speech recognition (ASR) applications. This paper proposes an innovative method for achieving end-to-end contextual ASR using graph neural network (GNN) encodings based on the tree-constrained pointer generator method. GNN node encodings facilitate lookahead for future word pieces in the process of ASR decoding at each tree node by incorporating information about all word pieces on the tree branches rooted from it. This results in a more precise prediction of the generation probability of the biasing words. The study explores three GNN encoding techniques, namely tree recursive neural networks, graph convolutional network (GCN), and GraphSAGE, along with different combinations of the complementary GCN and GraphSAGE structures. The performance of the systems was evaluated using the Librispeech and AMI corpus, following the visual-grounded contextual ASR pipeline. The findings indicate that using GNN encodings achieved consistent and significant reductions in word error rate (WER), particularly for words that are rare or have not been seen during the training process. Notably, the most effective combination of GNN encodings obtained more than 60% WER reduction for rare and unseen words compared to standard end-to-end systems.
Combination of Deep Speaker Embeddings for Diarisation
Oct 22, 2020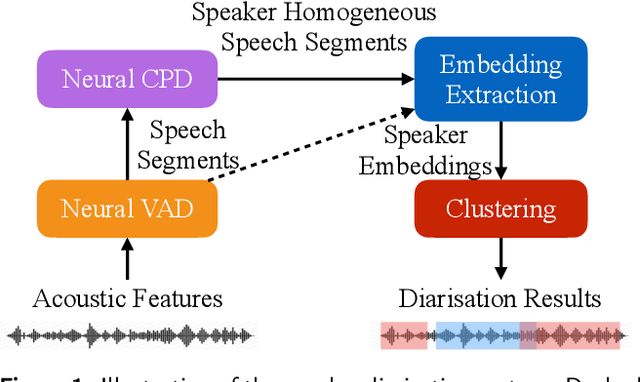
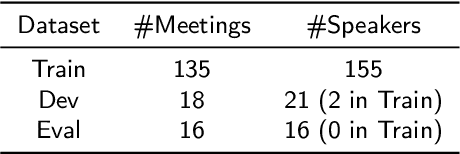
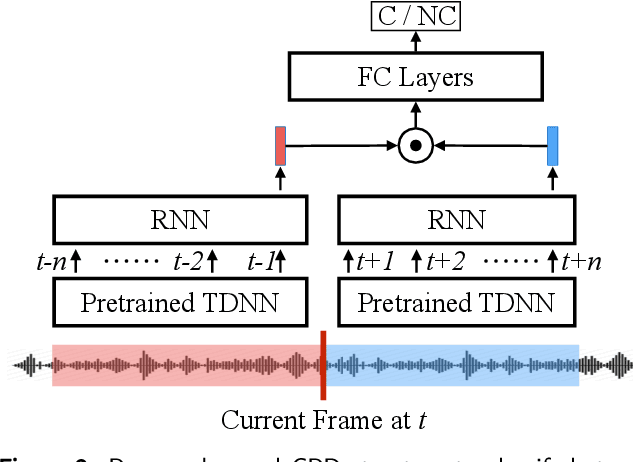
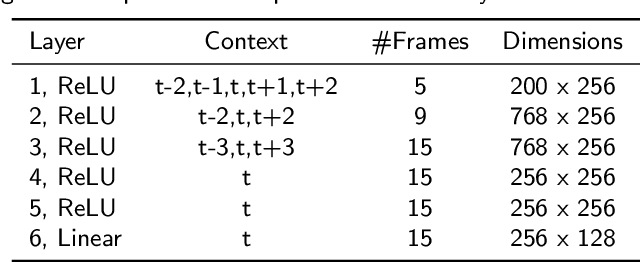
Recently, significant progress has been made in speaker diarisation after the introduction of d-vectors as speaker embeddings extracted from the neural network (NN) speaker classifiers for clustering speech segments. To extract better-performing and more robust speaker embeddings, this paper proposes a c-vector method by combining multiple sets of complementary d-vectors derived from systems with different NN components. Three structures are used to implement the c-vectors, namely 2D self-attentive, gated additive, and bilinear pooling structures, relying on attention mechanisms, a gating mechanism, and a low-rank bilinear pooling mechanism respectively. Furthermore, a neural-based single-pass speaker diarisation pipeline is also proposed in this paper, which uses NNs to achieve voice activity detection, speaker change point detection, and speaker embedding extraction. Experiments and detailed analyses are conducted on the challenging AMI and NIST RT05 datasets which consist of real meetings with 4--10 speakers and a wide range of acoustic conditions. Consistent improvements are obtained by using c-vectors instead of d-vectors, and similar relative improvements in diarisation error rates are observed on both AMI and RT05, which shows the robustness of the proposed methods.
Speaker diarisation using 2D self-attentive combination of embeddings
Feb 08, 2019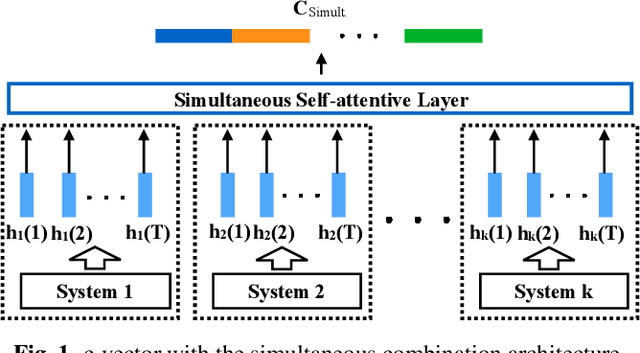
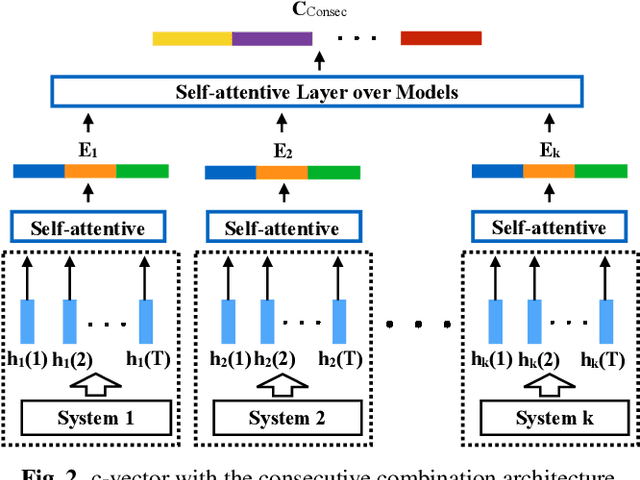

Speaker diarisation systems often cluster audio segments using speaker embeddings such as i-vectors and d-vectors. Since different types of embeddings are often complementary, this paper proposes a generic framework to improve performance by combining them into a single embedding, referred to as a c-vector. This combination uses a 2-dimensional (2D) self-attentive structure, which extends the standard self-attentive layer by averaging not only across time but also across different types of embeddings. Two types of 2D self-attentive structure in this paper are the simultaneous combination and the consecutive combination, adopting a single and multiple self-attentive layers respectively. The penalty term in the original self-attentive layer which is jointly minimised with the objective function to encourage diversity of annotation vectors is also modified to obtain not only different local peaks but also the overall trends in the multiple annotation vectors. Experiments on the AMI meeting corpus show that our modified penalty term improves the d- vector relative speaker error rate (SER) by 6% and 21% for d-vector systems, and a 10% further relative SER reduction can be obtained using the c-vector from our best 2D self-attentive structure.