 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Size, Many Fits: Aligning Diverse Group-Wise Click Preferences in Large-Scale Advertising Image Generation
Feb 02, 2026Advertising image generation has increasingly focused on online metrics like Click-Through Rate (CTR), yet existing approaches adopt a ``one-size-fits-all" strategy that optimizes for overall CTR while neglecting preference diversity among user groups. This leads to suboptimal performance for specific groups, limiting targeted marketing effectiveness. To bridge this gap, we present \textit{One Size, Many Fits} (OSMF), a unified framework that aligns diverse group-wise click preferences in large-scale advertising image generation. OSMF begins with product-aware adaptive grouping, which dynamically organizes users based on their attributes and product characteristics, representing each group with rich collective preference features. Building on these groups, preference-conditioned image generation employs a Group-aware Multimodal Large Language Model (G-MLLM) to generate tailored images for each group. The G-MLLM is pre-trained to simultaneously comprehend group features and generate advertising images. Subsequently, we fine-tune the G-MLLM using our proposed Group-DPO for group-wise preference alignment, which effectively enhances each group's CTR on the generated images. To further advance this field, we introduce the Grouped Advertising Image Preference Dataset (GAIP), the first large-scale public dataset of group-wise image preferences, including around 600K groups built from 40M users. Extensive experiments demonstrate that our framework achieves the state-of-the-art performance in both offline and online settings. Our code and datasets will be released at https://github.com/JD-GenX/OSMF.
MoFu: Scale-Aware Modulation and Fourier Fusion for Multi-Subject Video Generation
Dec 26, 2025Multi-subject video generation aims to synthesize videos from textual prompts and multiple reference images, ensuring that each subject preserves natural scale and visual fidelity. However, current methods face two challenges: scale inconsistency, where variations in subject size lead to unnatural generation, and permutation sensitivity, where the order of reference inputs causes subject distortion. In this paper, we propose MoFu, a unified framework that tackles both challenges. For scale inconsistency, we introduce Scale-Aware Modulation (SMO), an LLM-guided module that extracts implicit scale cues from the prompt and modulates features to ensure consistent subject sizes. To address permutation sensitivity, we present a simple yet effective Fourier Fusion strategy that processes the frequency information of reference features via the Fast Fourier Transform to produce a unified representation. Besides, we design a Scale-Permutation Stability Loss to jointly encourage scale-consistent and permutation-invariant generation. To further evaluate these challenges, we establish a dedicated benchmark with controlled variations in subject scale and reference permutation. Extensive experiments demonstrate that MoFu significantly outperforms existing methods in preserving natural scale, subject fidelity, and overall visual quality.
AutoPP: Towards Automated Product Poster Generation and Optimization
Dec 26, 2025Product posters blend striking visuals with informative text to highlight the product and capture customer attention. However, crafting appealing posters and manually optimizing them based on online performance is laborious and resource-consuming. To address this, we introduce AutoPP, an automated pipeline for product poster generation and optimization that eliminates the need for human intervention. Specifically, the generator, relying solely on basic product information, first uses a unified design module to integrate the three key elements of a poster (background, text, and layout) into a cohesive output. Then, an element rendering module encodes these elements into condition tokens, efficiently and controllably generating the product poster. Based on the generated poster, the optimizer enhances its Click-Through Rate (CTR) by leveraging online feedback. It systematically replaces elements to gather fine-grained CTR comparisons and utilizes Isolated Direct Preference Optimization (IDPO) to attribute CTR gains to isolated elements. Our work is supported by AutoPP1M, the largest dataset specifically designed for product poster generation and optimization, which contains one million high-quality posters and feedback collected from over one million users. Experiments demonstrate that AutoPP achieves state-of-the-art results in both offline and online settings. Our code and dataset are publicly available at: https://github.com/JD-GenX/AutoPP
Large Model Enabled Embodied Intelligence for 6G Integrated Perception, Communication, and Computation Network
Dec 22, 2025



The advent of sixth-generation (6G) places intelligence at the core of wireless architecture, fusing perception, communication, and computation into a single closed-loop. This paper argues that large artificial intelligence models (LAMs) can endow base stations with perception, reasoning, and acting capabilities, thus transforming them into intelligent base station agents (IBSAs). We first review the historical evolution of BSs from single-functional analog infrastructure to distributed, software-defined, and finally LAM-empowered IBSA, highlighting the accompanying changes in architecture, hardware platforms, and deployment. We then present an IBSA architecture that couples a perception-cognition-execution pipeline with cloud-edge-end collaboration and parameter-efficient adaptation. Subsequently,we study two representative scenarios: (i) cooperative vehicle-road perception for autonomous driving, and (ii) ubiquitous base station support for low-altitude uncrewed aerial vehicle safety monitoring and response against unauthorized drones. On this basis, we analyze key enabling technologies spanning LAM design and training, efficient edge-cloud inference, multi-modal perception and actuation, as well as trustworthy security and governance. We further propose a holistic evaluation framework and benchmark considerations that jointly cover communication performance, perception accuracy, decision-making reliability, safety, and energy efficiency. Finally, we distill open challenges on benchmarks, continual adaptation, trustworthy decision-making, and standardization. Together, this work positions LAM-enabled IBSAs as a practical path toward integrated perception, communication, and computation native, safety-critical 6G systems.
OBJVanish: Physically Realizable Text-to-3D Adv. Generation of LiDAR-Invisible Objects
Oct 08, 2025LiDAR-based 3D object detectors are fundamental to autonomous driving, where failing to detect objects poses severe safety risks. Developing effective 3D adversarial attacks is essential for thoroughly testing these detection systems and exposing their vulnerabilities before real-world deployment. However, existing adversarial attacks that add optimized perturbations to 3D points have two critical limitations: they rarely cause complete object disappearance and prove difficult to implement in physical environments. We introduce the text-to-3D adversarial generation method, a novel approach enabling physically realizable attacks that can generate 3D models of objects truly invisible to LiDAR detectors and be easily realized in the real world. Specifically, we present the first empirical study that systematically investigates the factors influencing detection vulnerability by manipulating the topology, connectivity, and intensity of individual pedestrian 3D models and combining pedestrians with multiple objects within the CARLA simulation environment. Building on the insights, we propose the physically-informed text-to-3D adversarial generation (Phy3DAdvGen) that systematically optimizes text prompts by iteratively refining verbs, objects, and poses to produce LiDAR-invisible pedestrians. To ensure physical realizability, we construct a comprehensive object pool containing 13 3D models of real objects and constrain Phy3DAdvGen to generate 3D objects based on combinations of objects in this set. Extensive experiments demonstrate that our approach can generate 3D pedestrians that evade six state-of-the-art (SOTA) LiDAR 3D detectors in both CARLA simulation and physical environments, thereby highlighting vulnerabilities in safety-critical applications.
SSL-SSAW: Self-Supervised Learning with Sigmoid Self-Attention Weighting for Question-Based Sign Language Translation
Sep 17, 2025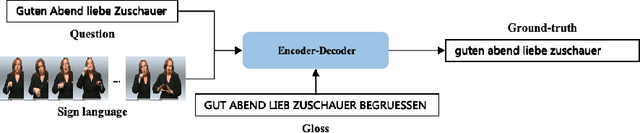
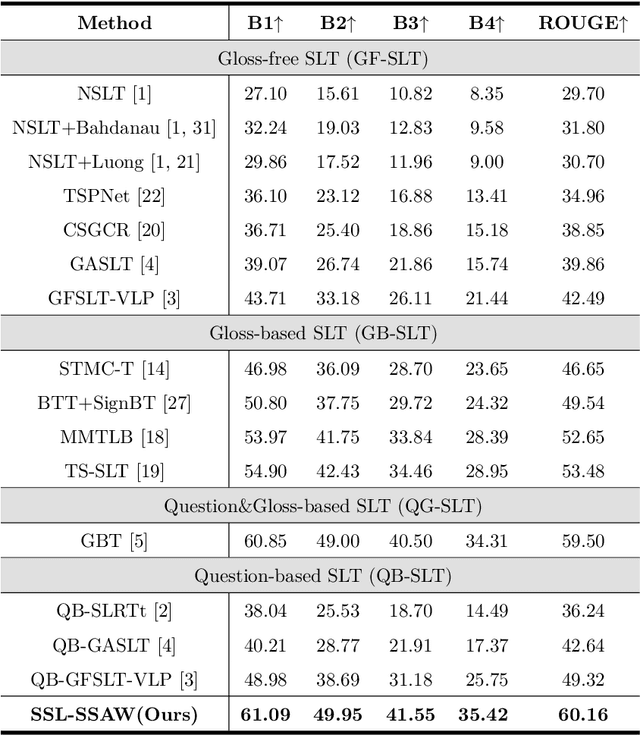
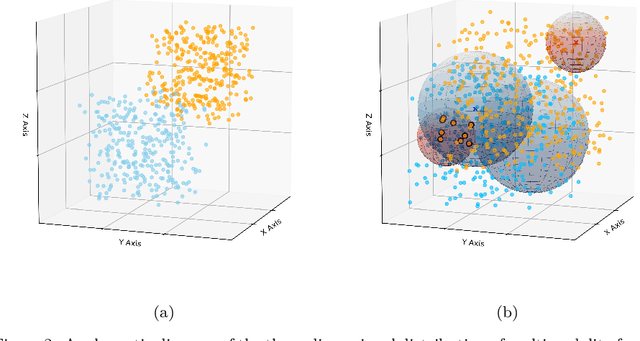
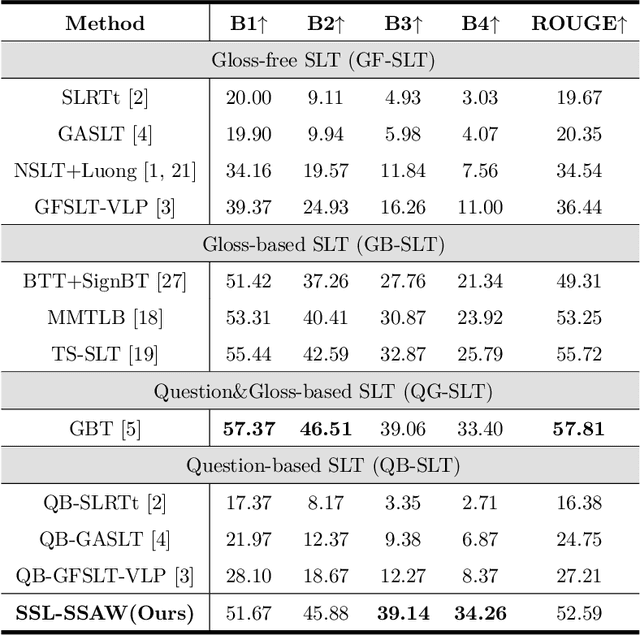
Sign Language Translation (SLT) bridges the communication gap between deaf people and hearing people, where dialogue provides crucial contextual cues to aid in translation. Building on this foundational concept, this paper proposes Question-based Sign Language Translation (QB-SLT), a novel task that explores the efficient integration of dialogue. Unlike gloss (sign language transcription) annotations, dialogue naturally occurs in communication and is easier to annotate. The key challenge lies in aligning multimodality features while leveraging the context of the question to improve translation. To address this issue, we propose a cross-modality Self-supervised Learning with Sigmoid Self-attention Weighting (SSL-SSAW) fusion method for sign language translation. Specifically, we employ contrastive learning to align multimodality features in QB-SLT, then introduce a Sigmoid Self-attention Weighting (SSAW) module for adaptive feature extraction from question and sign language sequences. Additionally, we leverage available question text through self-supervised learning to enhance representation and translation capabilities. We evaluated our approach on newly constructed CSL-Daily-QA and PHOENIX-2014T-QA datasets, where SSL-SSAW achieved SOTA performance. Notably, easily accessible question assistance can achieve or even surpass the performance of gloss assistance. Furthermore, visualization results demonstrate the effectiveness of incorporating dialogue in improving translation quality.
CLIPVehicle: A Unified Framework for Vision-based Vehicle Search
Aug 06, 2025



Vehicles, as one of the most common and significant objects in the real world, the researches on which using computer vision technologies have made remarkable progress, such as vehicle detection, vehicle re-identification, etc. To search an interested vehicle from the surveillance videos, existing methods first pre-detect and store all vehicle patches, and then apply vehicle re-identification models, which is resource-intensive and not very practical. In this work, we aim to achieve the joint detection and re-identification for vehicle search. However, the conflicting objectives between detection that focuses on shared vehicle commonness and re-identification that focuses on individual vehicle uniqueness make it challenging for a model to learn in an end-to-end system. For this problem, we propose a new unified framework, namely CLIPVehicle, which contains a dual-granularity semantic-region alignment module to leverage the VLMs (Vision-Language Models) for vehicle discrimination modeling, and a multi-level vehicle identification learning strategy to learn the identity representation from global, instance and feature levels. We also construct a new benchmark, including a real-world dataset CityFlowVS, and two synthetic datasets SynVS-Day and SynVS-All, for vehicle search. Extensive experimental results demonstrate that our method outperforms the state-of-the-art methods of both vehicle Re-ID and person search tasks.
Multi-Objective Trajectory Planning for a Robotic Arm in Curtain Wall Installation
Jul 23, 2025In the context of labor shortages and rising costs, construction robots are regarded as the key to revolutionizing traditional construction methods and improving efficiency and quality in the construction industry. In order to ensure that construction robots can perform tasks efficiently and accurately in complex construction environments, traditional single-objective trajectory optimization methods are difficult to meet the complex requirements of the changing construction environment. Therefore, we propose a multi-objective trajectory optimization for the robotic arm used in the curtain wall installation. First, we design a robotic arm for curtain wall installation, integrating serial, parallel, and folding arm elements, while considering its physical properties and motion characteristics. In addition, this paper proposes an NSGA-III-FO algorithm (NSGA-III with Focused Operator, NSGA-III-FO) that incorporates a focus operator screening mechanism to accelerate the convergence of the algorithm towards the Pareto front, thereby effectively balancing the multi-objective constraints of construction robots. The proposed algorithm is tested against NSGA-III, MOEA/D, and MSOPS-II in ten consecutive trials on the DTLZ3 and WFG3 test functions, showing significantly better convergence efficiency than the other algorithms. Finally, we conduct two sets of experiments on the designed robotic arm platform, which confirm the efficiency and practicality of the NSGA-III-FO algorithm in solving multi-objective trajectory planning problems for curtain wall installation tasks.
Dynamic Modeling and Dimensional Optimization of Legged Mechanisms for Construction Robot
Jul 23, 2025With the rapid development of the construction industry, issues such as harsh working environments, high-intensity and high-risk tasks, and labor shortages have become increasingly prominent. This drives higher demands for construction robots in terms of low energy consumption, high mobility, and high load capacity. This paper focuses on the design and optimization of leg structures for construction robots, aiming to improve their dynamic performance, reduce energy consumption, and enhance load-bearing capabilities. Firstly, based on the leg configuration of ants in nature, we design a structure for the robot's leg. Secondly, we propose a novel structural optimization method. Using the Lagrangian approach, a dynamic model of the leg was established. Combining the dynamic model with the leg's motion trajectory, we formulated multiple dynamic evaluation metrics and conducted a comprehensive optimization study on the geometric parameters of each leg segment. The results show that the optimized leg structure reduces peak joint torques and energy consumption by over 20%. Finally, dynamic simulation experiments were conducted using ADAMS. The results demonstrate a significant reduction in the driving power of each joint after optimization, validating the effectiveness and rationality of the proposed strategy. This study provides a theoretical foundation and technical support for the design of heavy-load, high-performance construction robots.
Dynamic Parameter Identification of a Curtain Wall Installation Robotic Arm
Jul 23, 2025In the construction industry, traditional methods fail to meet the modern demands for efficiency and quality. The curtain wall installation is a critical component of construction projects. We design a hydraulically driven robotic arm for curtain wall installation and a dynamic parameter identification method. We establish a Denavit-Hartenberg (D-H) model based on measured robotic arm structural parameters and integrate hydraulic cylinder dynamics to construct a composite parametric system driven by a Stribeck friction model. By designing high-signal-to-noise ratio displacement excitation signals for hydraulic cylinders and combining Fourier series to construct optimal excitation trajectories that satisfy joint constraints, this method effectively excites the characteristics of each parameter in the minimal parameter set of the dynamic model of the robotic arm. On this basis, a hierarchical progressive parameter identification strategy is proposed: least squares estimation is employed to separately identify and jointly calibrate the dynamic parameters of both the hydraulic cylinder and the robotic arm, yielding Stribeck model curves for each joint. Experimental validation on a robotic arm platform demonstrates residual standard deviations below 0.4 Nm between theoretical and measured joint torques, confirming high-precision dynamic parameter identification for the hydraulic-driven curtain wall installation robotic arm. This significantly contributes to enhancing the intelligence level of curtain wall installation operations.