 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCFCML: A Coarse-to-Fine Crossmodal Learning Framework For Disease Diagnosis Using Multimodal Images and Tabular Data
Mar 20, 2026In clinical practice, crossmodal information including medical images and tabular data is essential for disease diagnosis. There exists a significant modality gap between these data types, which obstructs advancements in crossmodal diagnostic accuracy. Most existing crossmodal learning (CML) methods primarily focus on exploring relationships among high-level encoder outputs, leading to the neglect of local information in images. Additionally, these methods often overlook the extraction of task-relevant information. In this paper, we propose a novel coarse-to-fine crossmodal learning (CFCML) framework to progressively reduce the modality gap between multimodal images and tabular data, by thoroughly exploring inter-modal relationships. At the coarse stage, we explore the relationships between multi-granularity features from various image encoder stages and tabular information, facilitating a preliminary reduction of the modality gap. At the fine stage, we generate unimodal and crossmodal prototypes that incorporate class-aware information, and establish hierarchical anchor-based relationship mining (HRM) strategy to further diminish the modality gap and extract discriminative crossmodal information. This strategy utilize modality samples, unimodal prototypes, and crossmodal prototypes as anchors to develop contrastive learning approaches, effectively enhancing inter-class disparity while reducing intra-class disparity from multiple perspectives. Experimental results indicate that our method outperforms the state-of-the-art (SOTA) methods, achieving improvements of 1.53% and 0.91% in AUC metrics on the MEN and Derm7pt datasets, respectively. The code is available at https://github.com/IsDling/CFCML.
FedBCD:Communication-Efficient Accelerated Block Coordinate Gradient Descent for Federated Learning
Mar 05, 2026Although Federated Learning has been widely studied in recent years, there are still high overhead expenses in each communication round for large-scale models such as Vision Transformer. To lower the communication complexity, we propose a novel Federated Block Coordinate Gradient Descent (FedBCGD) method for communication efficiency. The proposed method splits model parameters into several blocks, including a shared block and enables uploading a specific parameter block by each client, which can significantly reduce communication overhead. Moreover, we also develop an accelerated FedBCGD algorithm (called FedBCGD+) with client drift control and stochastic variance reduction. To the best of our knowledge, this paper is the first work on parameter block communication for training large-scale deep models. We also provide the convergence analysis for the proposed algorithms. Our theoretical results show that the communication complexities of our algorithms are a factor $1/N$ lower than those of existing methods, where $N$ is the number of parameter blocks, and they enjoy much faster convergence than their counterparts. Empirical results indicate the superiority of the proposed algorithms compared to state-of-the-art algorithms. The code is available at https://github.com/junkangLiu0/FedBCGD.
FedNSAM:Consistency of Local and Global Flatness for Federated Learning
Feb 27, 2026In federated learning (FL), multi-step local updates and data heterogeneity usually lead to sharper global minima, which degrades the performance of the global model. Popular FL algorithms integrate sharpness-aware minimization (SAM) into local training to address this issue. However, in the high data heterogeneity setting, the flatness in local training does not imply the flatness of the global model. Therefore, minimizing the sharpness of the local loss surfaces on the client data does not enable the effectiveness of SAM in FL to improve the generalization ability of the global model. We define the \textbf{flatness distance} to explain this phenomenon. By rethinking the SAM in FL and theoretically analyzing the \textbf{flatness distance}, we propose a novel \textbf{FedNSAM} algorithm that accelerates the SAM algorithm by introducing global Nesterov momentum into the local update to harmonize the consistency of global and local flatness. \textbf{FedNSAM} uses the global Nesterov momentum as the direction of local estimation of client global perturbations and extrapolation. Theoretically, we prove a tighter convergence bound than FedSAM by Nesterov extrapolation. Empirically, we conduct comprehensive experiments on CNN and Transformer models to verify the superior performance and efficiency of \textbf{FedNSAM}. The code is available at https://github.com/junkangLiu0/FedNSAM.
Taming Preconditioner Drift: Unlocking the Potential of Second-Order Optimizers for Federated Learning on Non-IID Data
Feb 22, 2026Second-order optimizers can significantly accelerate large-scale training, yet their naive federated variants are often unstable or even diverge on non-IID data. We show that a key culprit is \emph{preconditioner drift}: client-side second-order training induces heterogeneous \emph{curvature-defined geometries} (i.e., preconditioner coordinate systems), and server-side model averaging updates computed under incompatible metrics, corrupting the global descent direction. To address this geometric mismatch, we propose \texttt{FedPAC}, a \emph{preconditioner alignment and correction} framework for reliable federated second-order optimization. \texttt{FedPAC} explicitly decouples parameter aggregation from geometry synchronization by: (i) \textbf{Alignment} (i.e.,aggregating local preconditioners into a global reference and warm-starting clients via global preconditioner); and (ii) \textbf{Correction} (i.e., steering local preconditioned updates using a global preconditioned direction to suppress long-term drift). We provide drift-coupled non-convex convergence guarantees with linear speedup under partial participation. Empirically, \texttt{FedPAC} consistently improves stability and accuracy across vision and language tasks, achieving up to $5.8\%$ absolute accuracy gain on CIFAR-100 with ViTs. Code is available at https://anonymous.4open.science/r/FedPAC-8B24.
FedAdamW: A Communication-Efficient Optimizer with Convergence and Generalization Guarantees for Federated Large Models
Oct 31, 2025



AdamW has become one of the most effective optimizers for training large-scale models. We have also observed its effectiveness in the context of federated learning (FL). However, directly applying AdamW in federated learning settings poses significant challenges: (1) due to data heterogeneity, AdamW often yields high variance in the second-moment estimate $\boldsymbol{v}$; (2) the local overfitting of AdamW may cause client drift; and (3) Reinitializing moment estimates ($\boldsymbol{v}$, $\boldsymbol{m}$) at each round slows down convergence. To address these challenges, we propose the first \underline{Fed}erated \underline{AdamW} algorithm, called \texttt{FedAdamW}, for training and fine-tuning various large models. \texttt{FedAdamW} aligns local updates with the global update using both a \textbf{local correction mechanism} and decoupled weight decay to mitigate local overfitting. \texttt{FedAdamW} efficiently aggregates the \texttt{mean} of the second-moment estimates to reduce their variance and reinitialize them. Theoretically, we prove that \texttt{FedAdamW} achieves a linear speedup convergence rate of $\mathcal{O}(\sqrt{(L \Delta \sigma_l^2)/(S K R \epsilon^2)}+(L \Delta)/R)$ without \textbf{heterogeneity assumption}, where $S$ is the number of participating clients per round, $K$ is the number of local iterations, and $R$ is the total number of communication rounds. We also employ PAC-Bayesian generalization analysis to explain the effectiveness of decoupled weight decay in local training. Empirically, we validate the effectiveness of \texttt{FedAdamW} on language and vision Transformer models. Compared to several baselines, \texttt{FedAdamW} significantly reduces communication rounds and improves test accuracy. The code is available in https://github.com/junkangLiu0/FedAdamW.
FedMuon: Accelerating Federated Learning with Matrix Orthogonalization
Oct 31, 2025The core bottleneck of Federated Learning (FL) lies in the communication rounds. That is, how to achieve more effective local updates is crucial for reducing communication rounds. Existing FL methods still primarily use element-wise local optimizers (Adam/SGD), neglecting the geometric structure of the weight matrices. This often leads to the amplification of pathological directions in the weights during local updates, leading deterioration in the condition number and slow convergence. Therefore, we introduce the Muon optimizer in local, which has matrix orthogonalization to optimize matrix-structured parameters. Experimental results show that, in IID setting, Local Muon significantly accelerates the convergence of FL and reduces communication rounds compared to Local SGD and Local AdamW. However, in non-IID setting, independent matrix orthogonalization based on the local distributions of each client induces strong client drift. Applying Muon in non-IID FL poses significant challenges: (1) client preconditioner leading to client drift; (2) moment reinitialization. To address these challenges, we propose a novel Federated Muon optimizer (FedMuon), which incorporates two key techniques: (1) momentum aggregation, where clients use the aggregated momentum for local initialization; (2) local-global alignment, where the local gradients are aligned with the global update direction to significantly reduce client drift. Theoretically, we prove that \texttt{FedMuon} achieves a linear speedup convergence rate without the heterogeneity assumption, where $S$ is the number of participating clients per round, $K$ is the number of local iterations, and $R$ is the total number of communication rounds. Empirically, we validate the effectiveness of FedMuon on language and vision models. Compared to several baselines, FedMuon significantly reduces communication rounds and improves test accuracy.
DP-FedPGN: Finding Global Flat Minima for Differentially Private Federated Learning via Penalizing Gradient Norm
Oct 31, 2025To prevent inference attacks in Federated Learning (FL) and reduce the leakage of sensitive information, Client-level Differentially Private Federated Learning (CL-DPFL) is widely used. However, current CL-DPFL methods usually result in sharper loss landscapes, which leads to a decrease in model generalization after differential privacy protection. By using Sharpness Aware Minimization (SAM), the current popular federated learning methods are to find a local flat minimum value to alleviate this problem. However, the local flatness may not reflect the global flatness in CL-DPFL. Therefore, to address this issue and seek global flat minima of models, we propose a new CL-DPFL algorithm, DP-FedPGN, in which we introduce a global gradient norm penalty to the local loss to find the global flat minimum. Moreover, by using our global gradient norm penalty, we not only find a flatter global minimum but also reduce the locally updated norm, which means that we further reduce the error of gradient clipping. From a theoretical perspective, we analyze how DP-FedPGN mitigates the performance degradation caused by DP. Meanwhile, the proposed DP-FedPGN algorithm eliminates the impact of data heterogeneity and achieves fast convergence. We also use R\'enyi DP to provide strict privacy guarantees and provide sensitivity analysis for local updates. Finally, we conduct effectiveness tests on both ResNet and Transformer models, and achieve significant improvements in six visual and natural language processing tasks compared to existing state-of-the-art algorithms. The code is available at https://github.com/junkangLiu0/DP-FedPGN
SSL-SSAW: Self-Supervised Learning with Sigmoid Self-Attention Weighting for Question-Based Sign Language Translation
Sep 17, 2025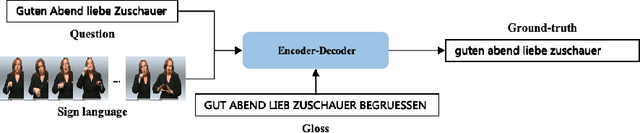
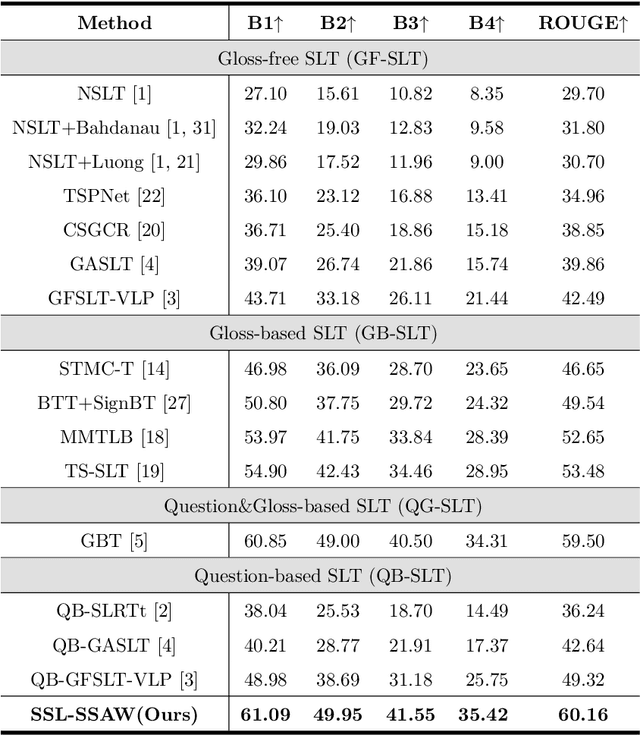
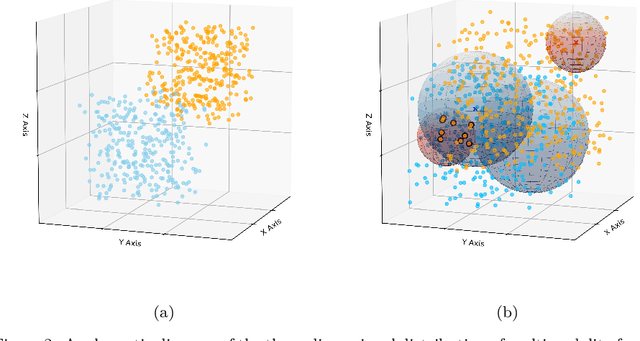
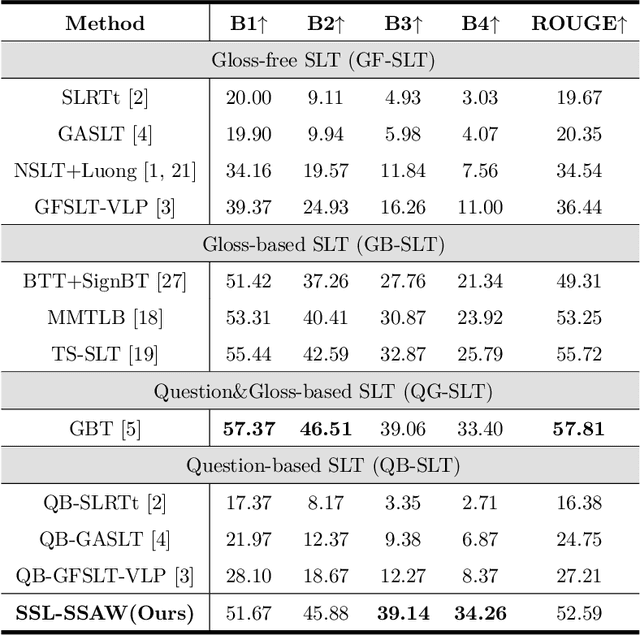
Sign Language Translation (SLT) bridges the communication gap between deaf people and hearing people, where dialogue provides crucial contextual cues to aid in translation. Building on this foundational concept, this paper proposes Question-based Sign Language Translation (QB-SLT), a novel task that explores the efficient integration of dialogue. Unlike gloss (sign language transcription) annotations, dialogue naturally occurs in communication and is easier to annotate. The key challenge lies in aligning multimodality features while leveraging the context of the question to improve translation. To address this issue, we propose a cross-modality Self-supervised Learning with Sigmoid Self-attention Weighting (SSL-SSAW) fusion method for sign language translation. Specifically, we employ contrastive learning to align multimodality features in QB-SLT, then introduce a Sigmoid Self-attention Weighting (SSAW) module for adaptive feature extraction from question and sign language sequences. Additionally, we leverage available question text through self-supervised learning to enhance representation and translation capabilities. We evaluated our approach on newly constructed CSL-Daily-QA and PHOENIX-2014T-QA datasets, where SSL-SSAW achieved SOTA performance. Notably, easily accessible question assistance can achieve or even surpass the performance of gloss assistance. Furthermore, visualization results demonstrate the effectiveness of incorporating dialogue in improving translation quality.
Beyond Background Shift: Rethinking Instance Replay in Continual Semantic Segmentation
Mar 28, 2025



In this work, we focus on continual semantic segmentation (CSS), where segmentation networks are required to continuously learn new classes without erasing knowledge of previously learned ones. Although storing images of old classes and directly incorporating them into the training of new models has proven effective in mitigating catastrophic forgetting in classification tasks, this strategy presents notable limitations in CSS. Specifically, the stored and new images with partial category annotations leads to confusion between unannotated categories and the background, complicating model fitting. To tackle this issue, this paper proposes a novel Enhanced Instance Replay (EIR) method, which not only preserves knowledge of old classes while simultaneously eliminating background confusion by instance storage of old classes, but also mitigates background shifts in the new images by integrating stored instances with new images. By effectively resolving background shifts in both stored and new images, EIR alleviates catastrophic forgetting in the CSS task, thereby enhancing the model's capacity for CSS. Experimental results validate the efficacy of our approach, which significantly outperforms state-of-the-art CSS methods.
iLLaVA: An Image is Worth Fewer Than 1/3 Input Tokens in Large Multimodal Models
Dec 09, 2024



In this paper, we introduce iLLaVA, a simple method that can be seamlessly deployed upon current Large Vision-Language Models (LVLMs) to greatly increase the throughput with nearly lossless model performance, without a further requirement to train. iLLaVA achieves this by finding and gradually merging the redundant tokens with an accurate and fast algorithm, which can merge hundreds of tokens within only one step. While some previous methods have explored directly pruning or merging tokens in the inference stage to accelerate models, our method excels in both performance and throughput by two key designs. First, while most previous methods only try to save the computations of Large Language Models (LLMs), our method accelerates the forward pass of both image encoders and LLMs in LVLMs, which both occupy a significant part of time during inference. Second, our method recycles the beneficial information from the pruned tokens into existing tokens, which avoids directly dropping context tokens like previous methods to cause performance loss. iLLaVA can nearly 2$\times$ the throughput, and reduce the memory costs by half with only a 0.2\% - 0.5\% performance drop across models of different scales including 7B, 13B and 34B. On tasks across different domains including single-image, multi-images and videos, iLLaVA demonstrates strong generalizability with consistently promising efficiency. We finally offer abundant visualizations to show the merging processes of iLLaVA in each step, which show insights into the distribution of computing resources in LVLMs. Code is available at https://github.com/hulianyuyy/iLLaVA.