 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTagLLM: A Fine-Grained Tag Generation Approach for Note Recommendation
Mar 23, 2026Large Language Models (LLMs) have shown promising potential in E-commerce community recommendation. While LLMs and Multimodal LLMs (MLLMs) are widely used to encode notes into implicit embeddings, leveraging their generative capabilities to represent notes with interpretable tags remains unexplored. In the field of tag generation, traditional close-ended methods heavily rely on the design of tag pools, while existing open-ended methods applied directly to note recommendations face two limitations: (1) MLLMs lack guidance during generation, resulting in redundant tags that fail to capture user interests; (2) The generated tags are often coarse and lack fine-grained representation of notes, interfering with downstream recommendations. To address these limitations, we propose TagLLM, a fine-grained tag generation method for note recommendation. TagLLM captures user interests across note categories through a User Interest Handbook and constructs fine-grained tag data using multimodal CoT Extraction. A Tag Knowledge Distillation method is developed to equip small models with competitive generation capabilities, enhancing inference efficiency. In online A/B test, TagLLM increases average view duration per user by 0.31%, average interactions per user by 0.96%, and page view click-through rate in cold-start scenario by 32.37%, demonstrating its effectiveness.
Power Interpretable Causal ODE Networks: A Unified Model for Explainable Anomaly Detection and Root Cause Analysis in Power Systems
Feb 13, 2026Anomaly detection and root cause analysis (RCA) are critical for ensuring the safety and resilience of cyber-physical systems such as power grids. However, existing machine learning models for time series anomaly detection often operate as black boxes, offering only binary outputs without any explanation, such as identifying anomaly type and origin. To address this challenge, we propose Power Interpretable Causality Ordinary Differential Equation (PICODE) Networks, a unified, causality-informed architecture that jointly performs anomaly detection along with the explanation why it is detected as an anomaly, including root cause localization, anomaly type classification, and anomaly shape characterization. Experimental results in power systems demonstrate that PICODE achieves competitive detection performance while offering improved interpretability and reduced reliance on labeled data or external causal graphs. We provide theoretical results demonstrating the alignment between the shape of anomaly functions and the changes in the weights of the extracted causal graphs.
CLIPVehicle: A Unified Framework for Vision-based Vehicle Search
Aug 06, 2025



Vehicles, as one of the most common and significant objects in the real world, the researches on which using computer vision technologies have made remarkable progress, such as vehicle detection, vehicle re-identification, etc. To search an interested vehicle from the surveillance videos, existing methods first pre-detect and store all vehicle patches, and then apply vehicle re-identification models, which is resource-intensive and not very practical. In this work, we aim to achieve the joint detection and re-identification for vehicle search. However, the conflicting objectives between detection that focuses on shared vehicle commonness and re-identification that focuses on individual vehicle uniqueness make it challenging for a model to learn in an end-to-end system. For this problem, we propose a new unified framework, namely CLIPVehicle, which contains a dual-granularity semantic-region alignment module to leverage the VLMs (Vision-Language Models) for vehicle discrimination modeling, and a multi-level vehicle identification learning strategy to learn the identity representation from global, instance and feature levels. We also construct a new benchmark, including a real-world dataset CityFlowVS, and two synthetic datasets SynVS-Day and SynVS-All, for vehicle search. Extensive experimental results demonstrate that our method outperforms the state-of-the-art methods of both vehicle Re-ID and person search tasks.
A Privacy-Preserving Domain Adversarial Federated learning for multi-site brain functional connectivity analysis
Feb 03, 2025



Resting-state functional magnetic resonance imaging (rs-fMRI) and its derived functional connectivity networks (FCNs) have become critical for understanding neurological disorders. However, collaborative analyses and the generalizability of models still face significant challenges due to privacy regulations and the non-IID (non-independent and identically distributed) property of multiple data sources. To mitigate these difficulties, we propose Domain Adversarial Federated Learning (DAFed), a novel federated deep learning framework specifically designed for non-IID fMRI data analysis in multi-site settings. DAFed addresses these challenges through feature disentanglement, decomposing the latent feature space into domain-invariant and domain-specific components, to ensure robust global learning while preserving local data specificity. Furthermore, adversarial training facilitates effective knowledge transfer between labeled and unlabeled datasets, while a contrastive learning module enhances the global representation of domain-invariant features. We evaluated DAFed on the diagnosis of ASD and further validated its generalizability in the classification of AD, demonstrating its superior classification accuracy compared to state-of-the-art methods. Additionally, an enhanced Score-CAM module identifies key brain regions and functional connectivity significantly associated with ASD and MCI, respectively, uncovering shared neurobiological patterns across sites. These findings highlight the potential of DAFed to advance multi-site collaborative research in neuroimaging while protecting data confidentiality.
A Benchmark of Video-Based Clothes-Changing Person Re-Identification
Nov 21, 2022



Person re-identification (Re-ID) is a classical computer vision task and has achieved great progress so far. Recently, long-term Re-ID with clothes-changing has attracted increasing attention. However, existing methods mainly focus on image-based setting, where richer temporal information is overlooked. In this paper, we focus on the relatively new yet practical problem of clothes-changing video-based person re-identification (CCVReID), which is less studied. We systematically study this problem by simultaneously considering the challenge of the clothes inconsistency issue and the temporal information contained in the video sequence for the person Re-ID problem. Based on this, we develop a two-branch confidence-aware re-ranking framework for handling the CCVReID problem. The proposed framework integrates two branches that consider both the classical appearance features and cloth-free gait features through a confidence-guided re-ranking strategy. This method provides the baseline method for further studies. Also, we build two new benchmark datasets for CCVReID problem, including a large-scale synthetic video dataset and a real-world one, both containing human sequences with various clothing changes. We will release the benchmark and code in this work to the public.
From Indoor To Outdoor: Unsupervised Domain Adaptive Gait Recognition
Nov 21, 2022Gait recognition is an important AI task, which has been progressed rapidly with the development of deep learning. However, existing learning based gait recognition methods mainly focus on the single domain, especially the constrained laboratory environment. In this paper, we study a new problem of unsupervised domain adaptive gait recognition (UDA-GR), that learns a gait identifier with supervised labels from the indoor scenes (source domain), and is applied to the outdoor wild scenes (target domain). For this purpose, we develop an uncertainty estimation and regularization based UDA-GR method. Specifically, we investigate the characteristic of gaits in the indoor and outdoor scenes, for estimating the gait sample uncertainty, which is used in the unsupervised fine-tuning on the target domain to alleviate the noises of the pseudo labels. We also establish a new benchmark for the proposed problem, experimental results on which show the effectiveness of the proposed method. We will release the benchmark and source code in this work to the public.
Combining the Silhouette and Skeleton Data for Gait Recognition
Mar 29, 2022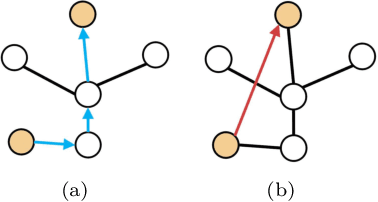
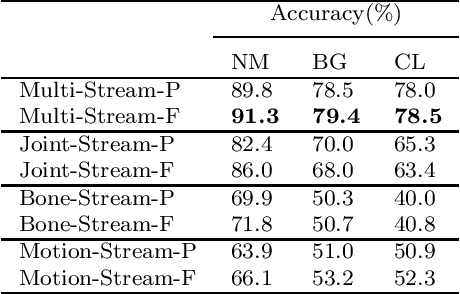
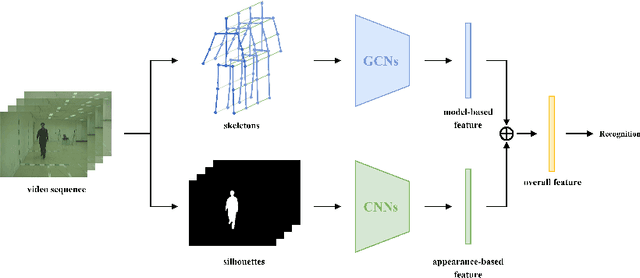
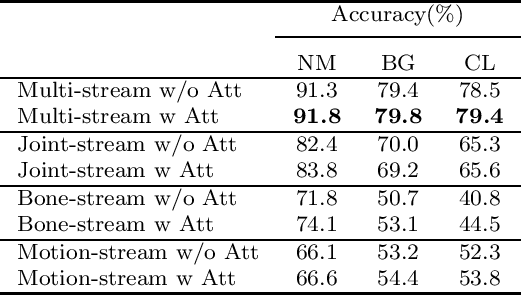
Gait recognition, a promising long-distance biometric technology, has aroused intense interest in computer vision. Existing works on gait recognition can be divided into appearance-based methods and model-based methods, which extract features from silhouettes and skeleton data, respectively. However, since appearance-based methods are greatly affected by clothing changing and carrying condition, and model-based methods are limited by the accuracy of pose estimation approaches, gait recognition remains challenging in practical applications. In order to integrate the advantages of such two approaches, a two-branch neural network (NN) is proposed in this paper. Our method contains two branches, namely a CNN-based branch taking silhouettes as input and a GCN-based branch taking skeletons as input. In addition, two new modules are proposed in the GCN-based branch for better gait representation. First, we present a simple yet effective fully connected graph convolution operator to integrate the multi-scale graph convolutions and alleviate the dependence on natural human joint connections. Second, we deploy a multi-dimension attention module named STC-Att to learn spatial, temporal and channel-wise attention simultaneously. We evaluated the proposed two-branch neural network on the CASIA-B dataset. The experimental results show that our method achieves state-of-the-art performance in various conditions.
Neural Network based Deep Transfer Learning for Cross-domain Dependency Parsing
Aug 08, 2019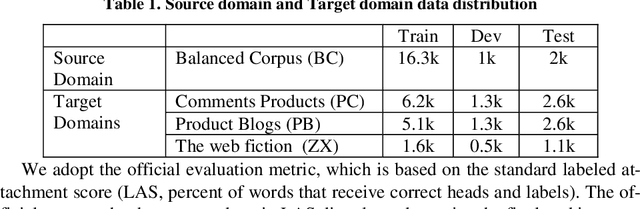
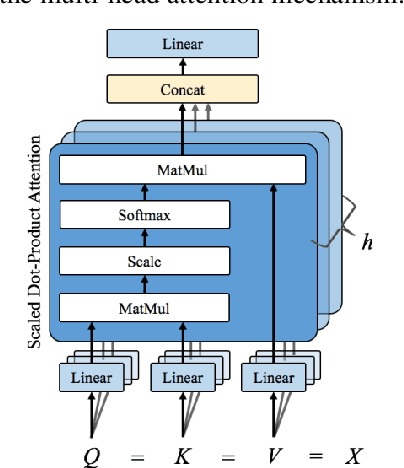

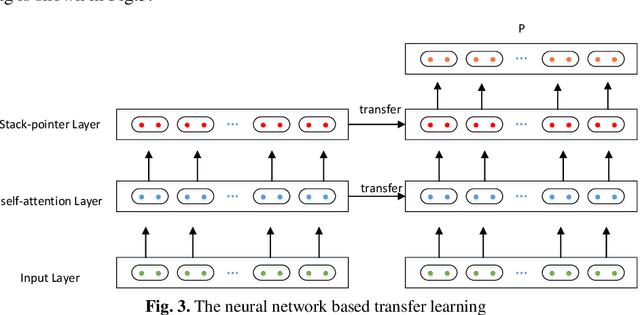
In this paper, we describe the details of the neural dependency parser sub-mitted by our team to the NLPCC 2019 Shared Task of Semi-supervised do-main adaptation subtask on Cross-domain Dependency Parsing. Our system is based on the stack-pointer networks(STACKPTR). Considering the im-portance of context, we utilize self-attention mechanism for the representa-tion vectors to capture the meaning of words. In addition, to adapt three dif-ferent domains, we utilize neural network based deep transfer learning which transfers the pre-trained partial network in the source domain to be a part of deep neural network in the three target domains (product comments, product blogs and web fiction) respectively. Results on the three target domains demonstrate that our model performs competitively.