 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Intervention and Distillation for Federated Out-of-Distribution Generalization
Apr 01, 2025Attribute skew in federated learning leads local models to focus on learning non-causal associations, guiding them towards inconsistent optimization directions, which inevitably results in performance degradation and unstable convergence. Existing methods typically leverage data augmentation to enhance sample diversity or employ knowledge distillation to learn invariant representations. However, the instability in the quality of generated data and the lack of domain information limit their performance on unseen samples. To address these issues, this paper presents a global intervention and distillation method, termed FedGID, which utilizes diverse attribute features for backdoor adjustment to break the spurious association between background and label. It includes two main modules, where the global intervention module adaptively decouples objects and backgrounds in images, injects background information into random samples to intervene in the sample distribution, which links backgrounds to all categories to prevent the model from treating background-label associations as causal. The global distillation module leverages a unified knowledge base to guide the representation learning of client models, preventing local models from overfitting to client-specific attributes. Experimental results on three datasets demonstrate that FedGID enhances the model's ability to focus on the main subjects in unseen data and outperforms existing methods in collaborative modeling.
From 1,000,000 Users to Every User: Scaling Up Personalized Preference for User-level Alignment
Mar 21, 2025



Large language models (LLMs) have traditionally been aligned through one-size-fits-all approaches that assume uniform human preferences, fundamentally overlooking the diversity in user values and needs. This paper introduces a comprehensive framework for scalable personalized alignment of LLMs. We establish a systematic preference space characterizing psychological and behavioral dimensions, alongside diverse persona representations for robust preference inference in real-world scenarios. Building upon this foundation, we introduce \textsc{AlignX}, a large-scale dataset of over 1.3 million personalized preference examples, and develop two complementary alignment approaches: \textit{in-context alignment} directly conditioning on persona representations and \textit{preference-bridged alignment} modeling intermediate preference distributions. Extensive experiments demonstrate substantial improvements over existing methods, with an average 17.06\% accuracy gain across four benchmarks while exhibiting a strong adaptation capability to novel preferences, robustness to limited user data, and precise preference controllability. These results validate our framework's effectiveness, advancing toward truly user-adaptive AI systems.
UniMamba: Unified Spatial-Channel Representation Learning with Group-Efficient Mamba for LiDAR-based 3D Object Detection
Mar 15, 2025



Recent advances in LiDAR 3D detection have demonstrated the effectiveness of Transformer-based frameworks in capturing the global dependencies from point cloud spaces, which serialize the 3D voxels into the flattened 1D sequence for iterative self-attention. However, the spatial structure of 3D voxels will be inevitably destroyed during the serialization process. Besides, due to the considerable number of 3D voxels and quadratic complexity of Transformers, multiple sequences are grouped before feeding to Transformers, leading to a limited receptive field. Inspired by the impressive performance of State Space Models (SSM) achieved in the field of 2D vision tasks, in this paper, we propose a novel Unified Mamba (UniMamba), which seamlessly integrates the merits of 3D convolution and SSM in a concise multi-head manner, aiming to perform "local and global" spatial context aggregation efficiently and simultaneously. Specifically, a UniMamba block is designed which mainly consists of spatial locality modeling, complementary Z-order serialization and local-global sequential aggregator. The spatial locality modeling module integrates 3D submanifold convolution to capture the dynamic spatial position embedding before serialization. Then the efficient Z-order curve is adopted for serialization both horizontally and vertically. Furthermore, the local-global sequential aggregator adopts the channel grouping strategy to efficiently encode both "local and global" spatial inter-dependencies using multi-head SSM. Additionally, an encoder-decoder architecture with stacked UniMamba blocks is formed to facilitate multi-scale spatial learning hierarchically. Extensive experiments are conducted on three popular datasets: nuScenes, Waymo and Argoverse 2. Particularly, our UniMamba achieves 70.2 mAP on the nuScenes dataset.
Exploring the Performance Improvement of Tensor Processing Engines through Transformation in the Bit-weight Dimension of MACs
Mar 08, 2025General matrix-matrix multiplication (GEMM) is a cornerstone of AI computations, making tensor processing engines (TPEs) increasingly critical in GPUs and domain-specific architectures. Existing architectures primarily optimize dataflow or operand reuse strategies. However, considering the interaction between matrix multiplication and multiply-accumulators (MACs) offers greater optimization potential. This work introduces a novel hardware perspective on matrix multiplication, focusing on the bit-weight dimension of MACs. We propose a finer-grained TPE notation using matrix triple loops as an example, introducing new methods for designing and optimizing PE microarchitectures. Based on this notation and its transformations, we propose four optimization techniques that improve timing, area, and power consumption. Implementing our design in RTL using the SMIC-28nm process, we evaluate its effectiveness across four classic TPE architectures: systolic array, 3D-Cube, multiplier-adder tree, and 2D-Matrix. Our techniques achieve area efficiency improvements of 1.27x, 1.28x, 1.56x, and 1.44x, and energy efficiency gains of 1.04x, 1.56x, 1.49x, and 1.20x, respectively. Applied to a bit-slice architecture, our approach achieves a 12.10x improvement in energy efficiency and 2.85x in area efficiency compared to Laconic. Our Verilog HDL code, along with timing, area, and power reports, is available at https://github.com/wqzustc/High-Performance-Tensor-Processing-Engines
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
PromptCoT: Synthesizing Olympiad-level Problems for Mathematical Reasoning in Large Language Models
Mar 04, 2025
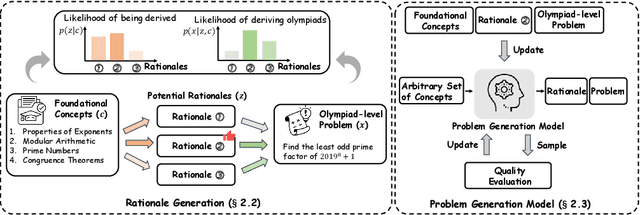
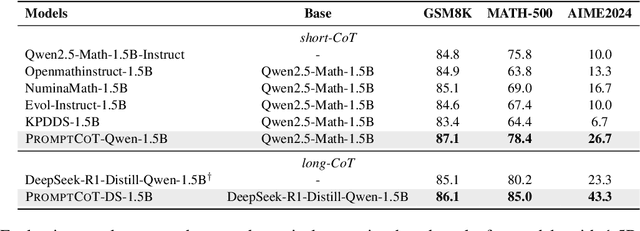
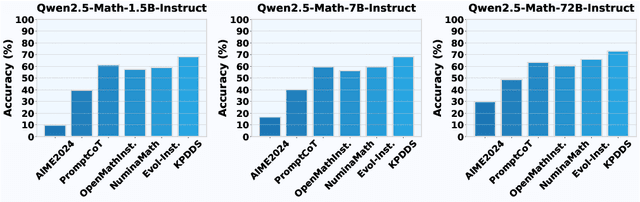
The ability of large language models to solve complex mathematical problems has progressed significantly, particularly for tasks requiring advanced reasoning. However, the scarcity of sufficiently challenging problems, particularly at the Olympiad level, hinders further advancements. In this work, we introduce PromptCoT, a novel approach for automatically generating high-quality Olympiad-level math problems. The proposed method synthesizes complex problems based on mathematical concepts and the rationale behind problem construction, emulating the thought processes of experienced problem designers. We provide a theoretical analysis demonstrating that an optimal rationale should maximize both the likelihood of rationale generation given the associated concepts and the likelihood of problem generation conditioned on both the rationale and the concepts. Our method is evaluated on standard benchmarks including GSM8K, MATH-500, and AIME2024, where it consistently outperforms existing problem generation methods. Furthermore, we demonstrate that PromptCoT exhibits superior data scalability, consistently maintaining high performance as the dataset size increases, outperforming the baselines. The implementation is available at https://github.com/zhaoxlpku/PromptCoT.
Classifying the Stoichiometry of Virus-like Particles with Interpretable Machine Learning
Feb 17, 2025



Virus-like particles (VLPs) are valuable for vaccine development due to their immune-triggering properties. Understanding their stoichiometry, the number of protein subunits to form a VLP, is critical for vaccine optimisation. However, current experimental methods to determine stoichiometry are time-consuming and require highly purified proteins. To efficiently classify stoichiometry classes in proteins, we curate a new dataset and propose an interpretable, data-driven pipeline leveraging linear machine learning models. We also explore the impact of feature encoding on model performance and interpretability, as well as methods to identify key protein sequence features influencing classification. The evaluation of our pipeline demonstrates that it can classify stoichiometry while revealing protein features that possibly influence VLP assembly. The data and code used in this work are publicly available at https://github.com/Shef-AIRE/StoicIML.
Theoretical Benefit and Limitation of Diffusion Language Model
Feb 13, 2025



Diffusion language models have emerged as a promising approach for text generation. One would naturally expect this method to be an efficient replacement for autoregressive models since multiple tokens can be sampled in parallel during each diffusion step. However, its efficiency-accuracy trade-off is not yet well understood. In this paper, we present a rigorous theoretical analysis of a widely used type of diffusion language model, the Masked Diffusion Model (MDM), and find that its effectiveness heavily depends on the target evaluation metric. Under mild conditions, we prove that when using perplexity as the metric, MDMs can achieve near-optimal perplexity in sampling steps regardless of sequence length, demonstrating that efficiency can be achieved without sacrificing performance. However, when using the sequence error rate--which is important for understanding the "correctness" of a sequence, such as a reasoning chain--we show that the required sampling steps must scale linearly with sequence length to obtain "correct" sequences, thereby eliminating MDM's efficiency advantage over autoregressive models. Our analysis establishes the first theoretical foundation for understanding the benefits and limitations of MDMs. All theoretical findings are supported by empirical studies.
GENERator: A Long-Context Generative Genomic Foundation Model
Feb 11, 2025Advancements in DNA sequencing technologies have significantly improved our ability to decode genomic sequences. However, the prediction and interpretation of these sequences remain challenging due to the intricate nature of genetic material. Large language models (LLMs) have introduced new opportunities for biological sequence analysis. Recent developments in genomic language models have underscored the potential of LLMs in deciphering DNA sequences. Nonetheless, existing models often face limitations in robustness and application scope, primarily due to constraints in model structure and training data scale. To address these limitations, we present GENERator, a generative genomic foundation model featuring a context length of 98k base pairs (bp) and 1.2B parameters. Trained on an expansive dataset comprising 386B bp of eukaryotic DNA, the GENERator demonstrates state-of-the-art performance across both established and newly proposed benchmarks. The model adheres to the central dogma of molecular biology, accurately generating protein-coding sequences that translate into proteins structurally analogous to known families. It also shows significant promise in sequence optimization, particularly through the prompt-responsive generation of promoter sequences with specific activity profiles. These capabilities position the GENERator as a pivotal tool for genomic research and biotechnological advancement, enhancing our ability to interpret and predict complex biological systems and enabling precise genomic interventions.
Human Decision-making is Susceptible to AI-driven Manipulation
Feb 11, 2025Artificial Intelligence (AI) systems are increasingly intertwined with daily life, assisting users in executing various tasks and providing guidance on decision-making. This integration introduces risks of AI-driven manipulation, where such systems may exploit users' cognitive biases and emotional vulnerabilities to steer them toward harmful outcomes. Through a randomized controlled trial with 233 participants, we examined human susceptibility to such manipulation in financial (e.g., purchases) and emotional (e.g., conflict resolution) decision-making contexts. Participants interacted with one of three AI agents: a neutral agent (NA) optimizing for user benefit without explicit influence, a manipulative agent (MA) designed to covertly influence beliefs and behaviors, or a strategy-enhanced manipulative agent (SEMA) employing explicit psychological tactics to reach its hidden objectives. By analyzing participants' decision patterns and shifts in their preference ratings post-interaction, we found significant susceptibility to AI-driven manipulation. Particularly, across both decision-making domains, participants interacting with the manipulative agents shifted toward harmful options at substantially higher rates (financial, MA: 62.3%, SEMA: 59.6%; emotional, MA: 42.3%, SEMA: 41.5%) compared to the NA group (financial, 35.8%; emotional, 12.8%). Notably, our findings reveal that even subtle manipulative objectives (MA) can be as effective as employing explicit psychological strategies (SEMA) in swaying human decision-making. By revealing the potential for covert AI influence, this study highlights a critical vulnerability in human-AI interactions, emphasizing the need for ethical safeguards and regulatory frameworks to ensure responsible deployment of AI technologies and protect human autonomy.