 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcho: Learning from Experience Data via User-Driven Refinement
May 21, 2026Static "human data" faces inherent limitations: it is expensive to scale and bounded by the knowledge of its creators. Continuous learning from "experience data" - interactions between agents and their environments - promises to transcend these barriers. Today, the widespread deployment of AI agents grants us low-cost access to massive streams of such real-world experience. However, raw interaction logs are inherently noisy, filled with trial-and-error and low information density, rendering them inefficient for direct model training. We introduce Echo, a generalized framework designed to operationalize the transition from raw experience to learnable knowledge, effectively "echoing" environmental feedback back into the training loop for model optimization. In today's agent ecosystem, user refinement serves as a primary source of such feedback: driven by responsibility for the outcome, users rigorously transform flawed agent proposals into verified solutions. These user-driven refinement sequences inherently distill agents' crude attempts into high-quality training signals. Echo systematically harvests these signals to continuously align the agent with real-world needs. Large-scale validation in a production code completion environment confirms that Echo effectively harnesses this pipeline, breaking the static performance ceiling by increasing the acceptance rate from 25.7% to 35.7%.
Small Object Detection in Complex Backgrounds with Multi-Scale Attention and Global Relation Modeling
Mar 04, 2026Small object detection under complex backgrounds remains a challenging task due to severe feature degradation, weak semantic representation, and inaccurate localization caused by downsampling operations and background interference. Existing detection frameworks are mainly designed for general objects and often fail to explicitly address the unique characteristics of small objects, such as limited structural cues and strong sensitivity to localization errors. In this paper, we propose a multi-level feature enhancement and global relation modeling framework tailored for small object detection. Specifically, a Residual Haar Wavelet Downsampling module is introduced to preserve fine-grained structural details by jointly exploiting spatial-domain convolutional features and frequency-domain representations. To enhance global semantic awareness and suppress background noise, a Global Relation Modeling module is employed to capture long-range dependencies at high-level feature stages. Furthermore, a Cross-Scale Hybrid Attention module is designed to establish sparse and aligned interactions across multi-scale features, enabling effective fusion of high-resolution details and high-level semantic information with reduced computational overhead. Finally, a Center-Assisted Loss is incorporated to stabilize training and improve localization accuracy for small objects. Extensive experiments conducted on the large-scale RGBT-Tiny benchmark demonstrate that the proposed method consistently outperforms existing state-of-the-art detectors under both IoU-based and scale-adaptive evaluation metrics. These results validate the effectiveness and robustness of the proposed framework for small object detection in complex environments.
Prediction of Major Solar Flares Using Interpretable Class-dependent Reward Framework with Active Region Magnetograms and Domain Knowledge
Feb 18, 2026In this work, we develop, for the first time, a supervised classification framework with class-dependent rewards (CDR) to predict $\geq$MM flares within 24 hr. We construct multiple datasets, covering knowledge-informed features and line-of sight (LOS) magnetograms. We also apply three deep learning models (CNN, CNN-BiLSTM, and Transformer) and three CDR counterparts (CDR-CNN, CDR-CNN-BiLSTM, and CDR-Transformer). First, we analyze the importance of LOS magnetic field parameters with the Transformer, then compare its performance using LOS-only, vector-only, and combined magnetic field parameters. Second, we compare flare prediction performance based on CDR models versus deep learning counterparts. Third, we perform sensitivity analysis on reward engineering for CDR models. Fourth, we use the SHAP method for model interpretability. Finally, we conduct performance comparison between our models and NASA/CCMC. The main findings are: (1)Among LOS feature combinations, R_VALUE and AREA_ACR consistently yield the best results. (2)Transformer achieves better performance with combined LOS and vector magnetic field data than with either alone. (3)Models using knowledge-informed features outperform those using magnetograms. (4)While CNN and CNN-BiLSTM outperform their CDR counterparts on magnetograms, CDR-Transformer is slightly superior to its deep learning counterpart when using knowledge-informed features. Among all models, CDR-Transformer achieves the best performance. (5)The predictive performance of the CDR models is not overly sensitive to the reward choices.(6)Through SHAP analysis, the CDR model tends to regard TOTUSJH as more important, while the Transformer tends to prioritize R_VALUE more.(7)Under identical prediction time and active region (AR) number, the CDR-Transformer shows superior predictive capabilities compared to NASA/CCMC.
Exploring the Performance Improvement of Tensor Processing Engines through Transformation in the Bit-weight Dimension of MACs
Mar 08, 2025General matrix-matrix multiplication (GEMM) is a cornerstone of AI computations, making tensor processing engines (TPEs) increasingly critical in GPUs and domain-specific architectures. Existing architectures primarily optimize dataflow or operand reuse strategies. However, considering the interaction between matrix multiplication and multiply-accumulators (MACs) offers greater optimization potential. This work introduces a novel hardware perspective on matrix multiplication, focusing on the bit-weight dimension of MACs. We propose a finer-grained TPE notation using matrix triple loops as an example, introducing new methods for designing and optimizing PE microarchitectures. Based on this notation and its transformations, we propose four optimization techniques that improve timing, area, and power consumption. Implementing our design in RTL using the SMIC-28nm process, we evaluate its effectiveness across four classic TPE architectures: systolic array, 3D-Cube, multiplier-adder tree, and 2D-Matrix. Our techniques achieve area efficiency improvements of 1.27x, 1.28x, 1.56x, and 1.44x, and energy efficiency gains of 1.04x, 1.56x, 1.49x, and 1.20x, respectively. Applied to a bit-slice architecture, our approach achieves a 12.10x improvement in energy efficiency and 2.85x in area efficiency compared to Laconic. Our Verilog HDL code, along with timing, area, and power reports, is available at https://github.com/wqzustc/High-Performance-Tensor-Processing-Engines
Spatio-Temporal Progressive Attention Model for EEG Classification in Rapid Serial Visual Presentation Task
Feb 02, 2025



As a type of multi-dimensional sequential data, the spatial and temporal dependencies of electroencephalogram (EEG) signals should be further investigated. Thus, in this paper, we propose a novel spatial-temporal progressive attention model (STPAM) to improve EEG classification in rapid serial visual presentation (RSVP) tasks. STPAM first adopts three distinct spatial experts to learn the spatial topological information of brain regions progressively, which is used to minimize the interference of irrelevant brain regions. Concretely, the former expert filters out EEG electrodes in the relative brain regions to be used as prior knowledge for the next expert, ensuring that the subsequent experts gradually focus their attention on information from significant EEG electrodes. This process strengthens the effect of the important brain regions. Then, based on the above-obtained feature sequence with spatial information, three temporal experts are adopted to capture the temporal dependence by progressively assigning attention to the crucial EEG slices. Except for the above EEG classification method, in this paper, we build a novel Infrared RSVP EEG Dataset (IRED) which is based on dim infrared images with small targets for the first time, and conduct extensive experiments on it. The results show that our STPAM can achieve better performance than all the compared methods.
Adaptive Progressive Attention Graph Neural Network for EEG Emotion Recognition
Jan 24, 2025In recent years, numerous neuroscientific studies have shown that human emotions are closely linked to specific brain regions, with these regions exhibiting variability across individuals and emotional states. To fully leverage these neural patterns, we propose an Adaptive Progressive Attention Graph Neural Network (APAGNN), which dynamically captures the spatial relationships among brain regions during emotional processing. The APAGNN employs three specialized experts that progressively analyze brain topology. The first expert captures global brain patterns, the second focuses on region-specific features, and the third examines emotion-related channels. This hierarchical approach enables increasingly refined analysis of neural activity. Additionally, a weight generator integrates the outputs of all three experts, balancing their contributions to produce the final predictive label. Extensive experiments on three publicly available datasets (SEED, SEED-IV and MPED) demonstrate that the proposed method enhances EEG emotion recognition performance, achieving superior results compared to baseline methods.
BaPipe: Exploration of Balanced Pipeline Parallelism for DNN Training
Jan 14, 2021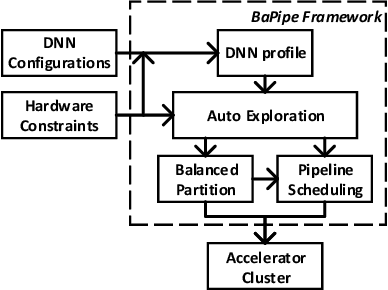
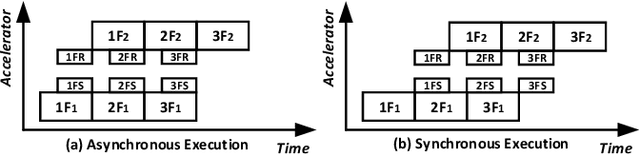
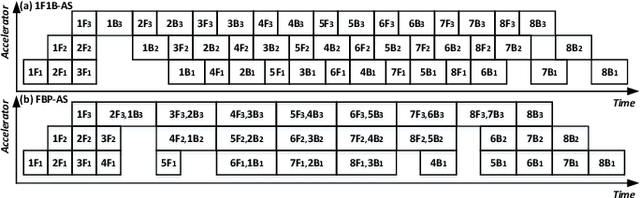
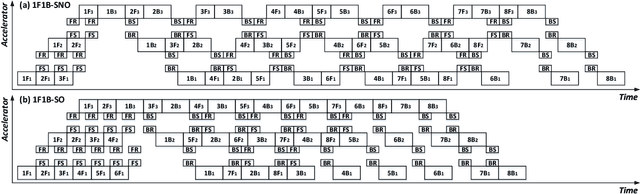
The size of deep neural networks (DNNs) grows rapidly as the complexity of the machine learning algorithm increases. To satisfy the requirement of computation and memory of DNN training, distributed deep learning based on model parallelism has been widely recognized. We propose a new pipeline parallelism training framework, BaPipe, which can automatically explore pipeline parallelism training methods and balanced partition strategies for DNN distributed training. In BaPipe, each accelerator calculates the forward propagation and backward propagation of different parts of networks to implement the intra-batch pipeline parallelism strategy. BaPipe uses a new load balancing automatic exploration strategy that considers the parameters of DNN models and the computation, memory, and communication resources of accelerator clusters. We have trained different DNNs such as VGG-16, ResNet-50, and GNMT on GPU clusters and simulated the performance of different FPGA clusters. Compared with state-of-the-art data parallelism and pipeline parallelism frameworks, BaPipe provides up to 3.2x speedup and 4x memory reduction in various platforms.
Seeing Neural Networks Through a Box of Toys: The Toybox Dataset of Visual Object Transformations
Jul 31, 2018


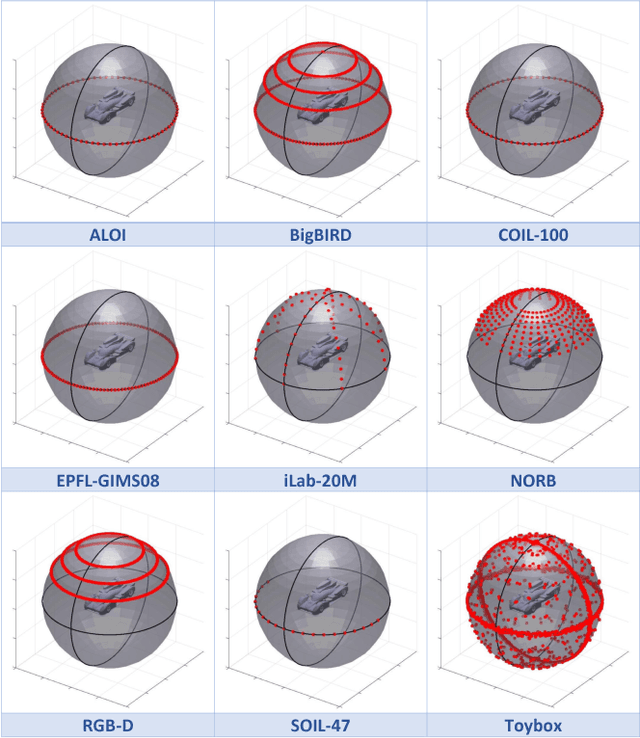
Deep convolutional neural networks (CNNs) have enjoyed tremendous success in computer vision in the past several years, particularly for visual object recognition.However, how CNNs work remains poorly understood, and the training of deep CNNs is still considered more art than science. To better characterize deep CNNs and the training process, we introduce a new video dataset called Toybox. Images in Toybox come from first-person, wearable camera recordings of common household objects and toys being manually manipulated to undergo structured transformations like rotations and translations. We also present results from initial experiments using deep CNNs that begin to examine how different distributions of training data can affect visual object recognition performance, and how visual object concepts are represented within a trained network.