 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake LoRA Great Again: Boosting LoRA with Adaptive Singular Values and Mixture-of-Experts Optimization Alignment
Feb 26, 2025



While Low-Rank Adaptation (LoRA) enables parameter-efficient fine-tuning for Large Language Models (LLMs), its performance often falls short of Full Fine-Tuning (Full FT). Current methods optimize LoRA by initializing with static singular value decomposition (SVD) subsets, leading to suboptimal leveraging of pre-trained knowledge. Another path for improving LoRA is incorporating a Mixture-of-Experts (MoE) architecture. However, weight misalignment and complex gradient dynamics make it challenging to adopt SVD prior to the LoRA MoE architecture. To mitigate these issues, we propose \underline{G}reat L\underline{o}R\underline{A} Mixture-of-Exper\underline{t} (GOAT), a framework that (1) adaptively integrates relevant priors using an SVD-structured MoE, and (2) aligns optimization with full fine-tuned MoE by deriving a theoretical scaling factor. We demonstrate that proper scaling, without modifying the architecture or training algorithms, boosts LoRA MoE's efficiency and performance. Experiments across 25 datasets, including natural language understanding, commonsense reasoning, image classification, and natural language generation, demonstrate GOAT's state-of-the-art performance, closing the gap with Full FT.
KVLink: Accelerating Large Language Models via Efficient KV Cache Reuse
Feb 21, 2025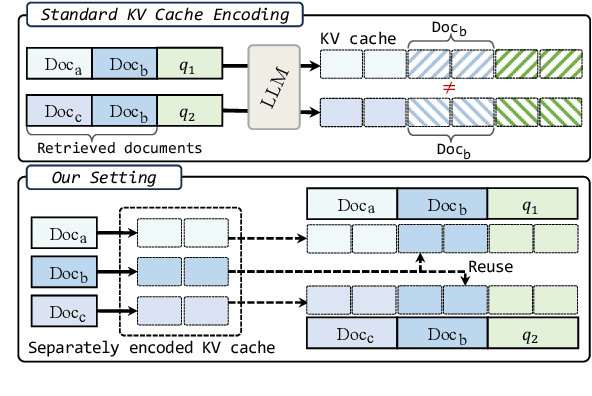
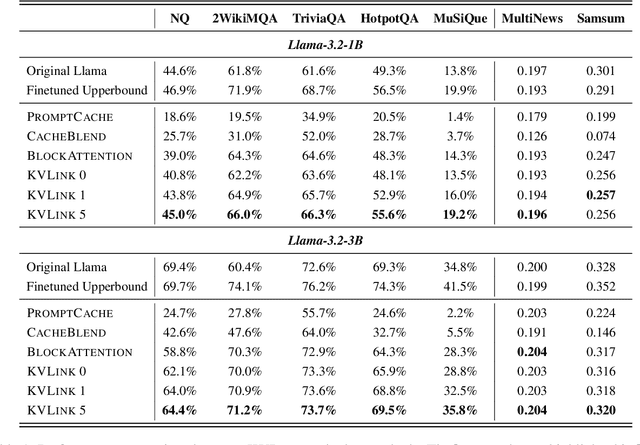
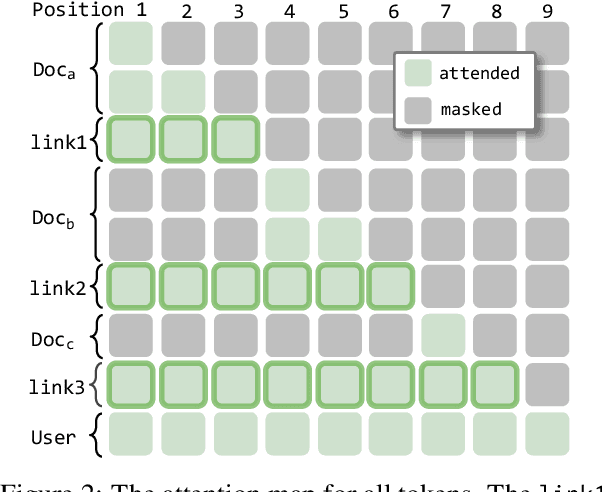
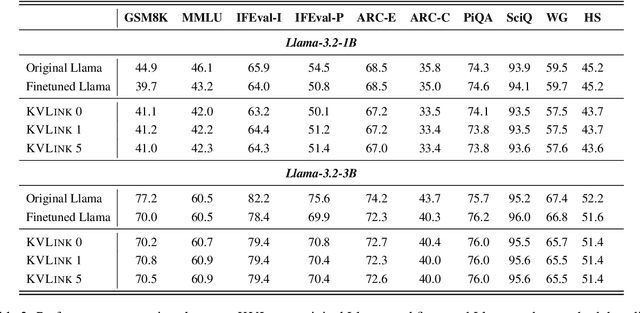
We describe KVLink, an approach for efficient key-value (KV) cache reuse in large language models (LLMs). In many LLM applications, different inputs can share overlapping context, such as the same retrieved document appearing in multiple queries. However, the LLMs still need to encode the entire context for each query, leading to redundant computation. In this paper, we propose a new strategy to eliminate such inefficiency, where the KV cache of each document is precomputed independently. During inference, the KV caches of retrieved documents are concatenated, allowing the model to reuse cached representations instead of recomputing them. To mitigate the performance degradation of LLMs when using KV caches computed independently for each document, KVLink introduces three key components: adjusting positional embeddings of the KV cache at inference to match the global position after concatenation, using trainable special tokens to restore self-attention across independently encoded documents, and applying mixed-data fine-tuning to enhance performance while preserving the model's original capabilities. Experiments across 7 datasets demonstrate that KVLink improves question answering accuracy by an average of 4% over state-of-the-art methods. Furthermore, by leveraging precomputed KV caches, our approach reduces time-to-first-token by up to 90% compared to standard LLM inference, making it a scalable and efficient solution for context reuse.
H-CoT: Hijacking the Chain-of-Thought Safety Reasoning Mechanism to Jailbreak Large Reasoning Models, Including OpenAI o1/o3, DeepSeek-R1, and Gemini 2.0 Flash Thinking
Feb 18, 2025



Large Reasoning Models (LRMs) have recently extended their powerful reasoning capabilities to safety checks-using chain-of-thought reasoning to decide whether a request should be answered. While this new approach offers a promising route for balancing model utility and safety, its robustness remains underexplored. To address this gap, we introduce Malicious-Educator, a benchmark that disguises extremely dangerous or malicious requests beneath seemingly legitimate educational prompts. Our experiments reveal severe security flaws in popular commercial-grade LRMs, including OpenAI o1/o3, DeepSeek-R1, and Gemini 2.0 Flash Thinking. For instance, although OpenAI's o1 model initially maintains a high refusal rate of about 98%, subsequent model updates significantly compromise its safety; and attackers can easily extract criminal strategies from DeepSeek-R1 and Gemini 2.0 Flash Thinking without any additional tricks. To further highlight these vulnerabilities, we propose Hijacking Chain-of-Thought (H-CoT), a universal and transferable attack method that leverages the model's own displayed intermediate reasoning to jailbreak its safety reasoning mechanism. Under H-CoT, refusal rates sharply decline-dropping from 98% to below 2%-and, in some instances, even transform initially cautious tones into ones that are willing to provide harmful content. We hope these findings underscore the urgent need for more robust safety mechanisms to preserve the benefits of advanced reasoning capabilities without compromising ethical standards.
UniQ: Unified Decoder with Task-specific Queries for Efficient Scene Graph Generation
Jan 10, 2025



Scene Graph Generation(SGG) is a scene understanding task that aims at identifying object entities and reasoning their relationships within a given image. In contrast to prevailing two-stage methods based on a large object detector (e.g., Faster R-CNN), one-stage methods integrate a fixed-size set of learnable queries to jointly reason relational triplets <subject, predicate, object>. This paradigm demonstrates robust performance with significantly reduced parameters and computational overhead. However, the challenge in one-stage methods stems from the issue of weak entanglement, wherein entities involved in relationships require both coupled features shared within triplets and decoupled visual features. Previous methods either adopt a single decoder for coupled triplet feature modeling or multiple decoders for separate visual feature extraction but fail to consider both. In this paper, we introduce UniQ, a Unified decoder with task-specific Queries architecture, where task-specific queries generate decoupled visual features for subjects, objects, and predicates respectively, and unified decoder enables coupled feature modeling within relational triplets. Experimental results on the Visual Genome dataset demonstrate that UniQ has superior performance to both one-stage and two-stage methods.
Overcoming Language Priors for Visual Question Answering Based on Knowledge Distillation
Jan 10, 2025



Previous studies have pointed out that visual question answering (VQA) models are prone to relying on language priors for answer predictions. In this context, predictions often depend on linguistic shortcuts rather than a comprehensive grasp of multimodal knowledge, which diminishes their generalization ability. In this paper, we propose a novel method, namely, KDAR, leveraging knowledge distillation to address the prior-dependency dilemmas within the VQA task. Specifically, the regularization effect facilitated by soft labels from a well-trained teacher is employed to penalize overfitting to the most common answers. The soft labels, which serve a regularization role, also provide semantic guidance that narrows the range of candidate answers. Additionally, we design an adaptive sample-wise reweighting learning strategy to further mitigate bias by dynamically adjusting the importance of each sample. Experimental results demonstrate that our method enhances performance in both OOD and IID settings. Our method achieves state-of-the-art performance on the VQA-CPv2 out-of-distribution (OOD) benchmark, significantly outperforming previous state-of-the-art approaches.
Bridged Semantic Alignment for Zero-shot 3D Medical Image Diagnosis
Jan 07, 20253D medical images such as Computed tomography (CT) are widely used in clinical practice, offering a great potential for automatic diagnosis. Supervised learning-based approaches have achieved significant progress but rely heavily on extensive manual annotations, limited by the availability of training data and the diversity of abnormality types. Vision-language alignment (VLA) offers a promising alternative by enabling zero-shot learning without additional annotations. However, we empirically discover that the visual and textural embeddings after alignment endeavors from existing VLA methods form two well-separated clusters, presenting a wide gap to be bridged. To bridge this gap, we propose a Bridged Semantic Alignment (BrgSA) framework. First, we utilize a large language model to perform semantic summarization of reports, extracting high-level semantic information. Second, we design a Cross-Modal Knowledge Interaction (CMKI) module that leverages a cross-modal knowledge bank as a semantic bridge, facilitating interaction between the two modalities, narrowing the gap, and improving their alignment. To comprehensively evaluate our method, we construct a benchmark dataset that includes 15 underrepresented abnormalities as well as utilize two existing benchmark datasets. Experimental results demonstrate that BrgSA achieves state-of-the-art performances on both public benchmark datasets and our custom-labeled dataset, with significant improvements in zero-shot diagnosis of underrepresented abnormalities.
Integrating Language-Image Prior into EEG Decoding for Cross-Task Zero-Calibration RSVP-BCI
Jan 06, 2025



Rapid Serial Visual Presentation (RSVP)-based Brain-Computer Interface (BCI) is an effective technology used for information detection by detecting Event-Related Potentials (ERPs). The current RSVP decoding methods can perform well in decoding EEG signals within a single RSVP task, but their decoding performance significantly decreases when directly applied to different RSVP tasks without calibration data from the new tasks. This limits the rapid and efficient deployment of RSVP-BCI systems for detecting different categories of targets in various scenarios. To overcome this limitation, this study aims to enhance the cross-task zero-calibration RSVP decoding performance. First, we design three distinct RSVP tasks for target image retrieval and build an open-source dataset containing EEG signals and corresponding stimulus images. Then we propose an EEG with Language-Image Prior fusion Transformer (ELIPformer) for cross-task zero-calibration RSVP decoding. Specifically, we propose a prompt encoder based on the language-image pre-trained model to extract language-image features from task-specific prompts and stimulus images as prior knowledge for enhancing EEG decoding. A cross bidirectional attention mechanism is also adopted to facilitate the effective feature fusion and alignment between the EEG and language-image features. Extensive experiments demonstrate that the proposed model achieves superior performance in cross-task zero-calibration RSVP decoding, which promotes the RSVP-BCI system from research to practical application.
Tackling the Dynamicity in a Production LLM Serving System with SOTA Optimizations via Hybrid Prefill/Decode/Verify Scheduling on Efficient Meta-kernels
Dec 24, 2024



Meeting growing demands for low latency and cost efficiency in production-grade large language model (LLM) serving systems requires integrating advanced optimization techniques. However, dynamic and unpredictable input-output lengths of LLM, compounded by these optimizations, exacerbate the issues of workload variability, making it difficult to maintain high efficiency on AI accelerators, especially DSAs with tile-based programming models. To address this challenge, we introduce XY-Serve, a versatile, Ascend native, end-to-end production LLM-serving system. The core idea is an abstraction mechanism that smooths out the workload variability by decomposing computations into unified, hardware-friendly, fine-grained meta primitives. For attention, we propose a meta-kernel that computes the basic pattern of matmul-softmax-matmul with architectural-aware tile sizes. For GEMM, we introduce a virtual padding scheme that adapts to dynamic shape changes while using highly efficient GEMM primitives with assorted fixed tile sizes. XY-Serve sits harmoniously with vLLM. Experimental results show up to 89% end-to-end throughput improvement compared with current publicly available baselines on Ascend NPUs. Additionally, our approach outperforms existing GEMM (average 14.6% faster) and attention (average 21.5% faster) kernels relative to existing libraries. While the work is Ascend native, we believe the approach can be readily applicable to SIMT architectures as well.
SpatialMe: Stereo Video Conversion Using Depth-Warping and Blend-Inpainting
Dec 16, 2024Stereo video conversion aims to transform monocular videos into immersive stereo format. Despite the advancements in novel view synthesis, it still remains two major challenges: i) difficulty of achieving high-fidelity and stable results, and ii) insufficiency of high-quality stereo video data. In this paper, we introduce SpatialMe, a novel stereo video conversion framework based on depth-warping and blend-inpainting. Specifically, we propose a mask-based hierarchy feature update (MHFU) refiner, which integrate and refine the outputs from designed multi-branch inpainting module, using feature update unit (FUU) and mask mechanism. We also propose a disparity expansion strategy to address the problem of foreground bleeding. Furthermore, we conduct a high-quality real-world stereo video dataset -- StereoV1K, to alleviate the data shortage. It contains 1000 stereo videos captured in real-world at a resolution of 1180 x 1180, covering various indoor and outdoor scenes. Extensive experiments demonstrate the superiority of our approach in generating stereo videos over state-of-the-art methods.
Unbiased General Annotated Dataset Generation
Dec 14, 2024



Pre-training backbone networks on a general annotated dataset (e.g., ImageNet) that comprises numerous manually collected images with category annotations has proven to be indispensable for enhancing the generalization capacity of downstream visual tasks. However, those manually collected images often exhibit bias, which is non-transferable across either categories or domains, thus causing the model's generalization capacity degeneration. To mitigate this problem, we present an unbiased general annotated dataset generation framework (ubGen). Instead of expensive manual collection, we aim at directly generating unbiased images with category annotations. To achieve this goal, we propose to leverage the advantage of a multimodal foundation model (e.g., CLIP), in terms of aligning images in an unbiased semantic space defined by language. Specifically, we develop a bi-level semantic alignment loss, which not only forces all generated images to be consistent with the semantic distribution of all categories belonging to the target dataset in an adversarial learning manner, but also requires each generated image to match the semantic description of its category name. In addition, we further cast an existing image quality scoring model into a quality assurance loss to preserve the quality of the generated image. By leveraging these two loss functions, we can obtain an unbiased image generation model by simply fine-tuning a pre-trained diffusion model using only all category names in the target dataset as input. Experimental results confirm that, compared with the manually labeled dataset or other synthetic datasets, the utilization of our generated unbiased datasets leads to stable generalization capacity enhancement of different backbone networks across various tasks, especially in tasks where the manually labeled samples are scarce.