 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKVLink: Accelerating Large Language Models via Efficient KV Cache Reuse
Paper and Code
Feb 21, 2025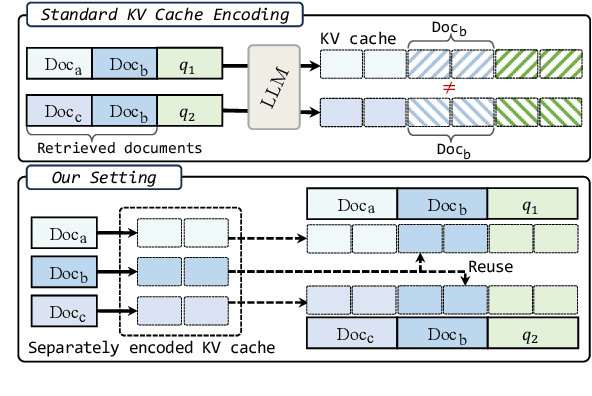
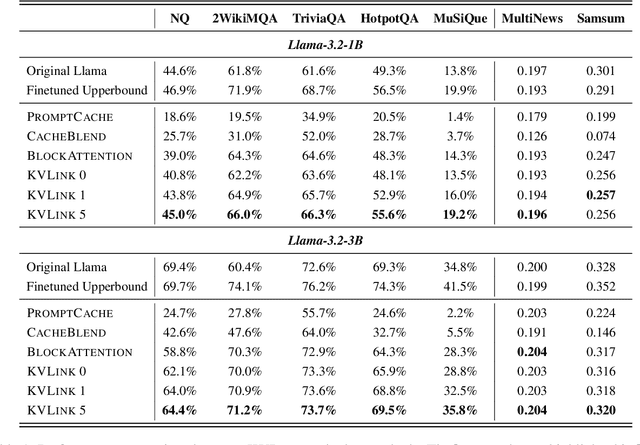
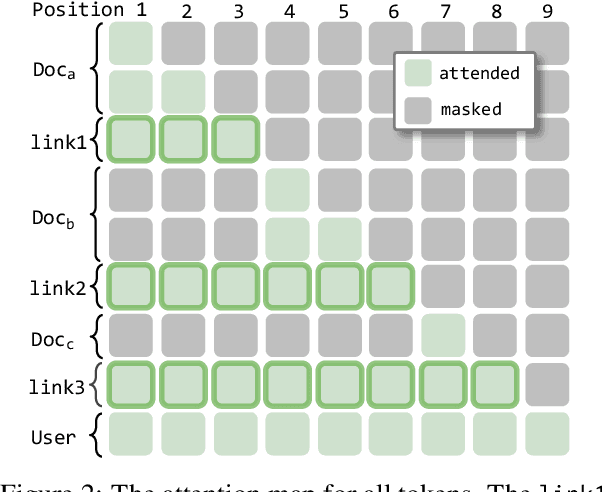
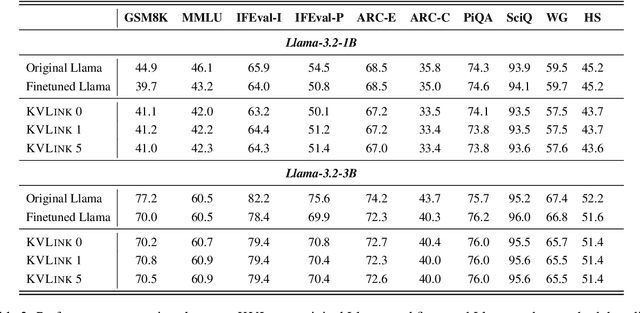
We describe KVLink, an approach for efficient key-value (KV) cache reuse in large language models (LLMs). In many LLM applications, different inputs can share overlapping context, such as the same retrieved document appearing in multiple queries. However, the LLMs still need to encode the entire context for each query, leading to redundant computation. In this paper, we propose a new strategy to eliminate such inefficiency, where the KV cache of each document is precomputed independently. During inference, the KV caches of retrieved documents are concatenated, allowing the model to reuse cached representations instead of recomputing them. To mitigate the performance degradation of LLMs when using KV caches computed independently for each document, KVLink introduces three key components: adjusting positional embeddings of the KV cache at inference to match the global position after concatenation, using trainable special tokens to restore self-attention across independently encoded documents, and applying mixed-data fine-tuning to enhance performance while preserving the model's original capabilities. Experiments across 7 datasets demonstrate that KVLink improves question answering accuracy by an average of 4% over state-of-the-art methods. Furthermore, by leveraging precomputed KV caches, our approach reduces time-to-first-token by up to 90% compared to standard LLM inference, making it a scalable and efficient solution for context reuse.