 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2S-Bench & Structure-of-Thought: Benchmarking and Prompting Comprehensive Text-to-Structure Reasoning
Mar 04, 2026Think about how human handles complex reading tasks: marking key points, inferring their relationships, and structuring information to guide understanding and responses. Likewise, can a large language model benefit from text structure to enhance text-processing performance? To explore it, in this work, we first introduce Structure of Thought (SoT), a prompting technique that explicitly guides models to construct intermediate text structures, consistently boosting performance across eight tasks and three model families. Building upon this insight, we present T2S-Bench, the first benchmark designed to evaluate and improve text-to-structure capabilities of models. T2S-Bench includes 1.8K samples across 6 scientific domains and 32 structural types, rigorously constructed to ensure accuracy, fairness, and quality. Evaluation on 45 mainstream models reveals substantial improvement potential: the average accuracy on the multi-hop reasoning task is only 52.1%, and even the most advanced model achieves 58.1% node accuracy in end-to-end extraction. Furthermore, on Qwen2.5-7B-Instruct, SoT alone yields an average +5.7% improvement across eight diverse text-processing tasks, and fine-tuning on T2S-Bench further increases this gain to +8.6%. These results highlight the value of explicit text structuring and the complementary contributions of SoT and T2S-Bench. Dataset and eval code have been released at https://t2s-bench.github.io/T2S-Bench-Page/.
CoreMatching: A Co-adaptive Sparse Inference Framework with Token and Neuron Pruning for Comprehensive Acceleration of Vision-Language Models
May 25, 2025Vision-Language Models (VLMs) excel across diverse tasks but suffer from high inference costs in time and memory. Token sparsity mitigates inefficiencies in token usage, while neuron sparsity reduces high-dimensional computations, both offering promising solutions to enhance efficiency. Recently, these two sparsity paradigms have evolved largely in parallel, fostering the prevailing assumption that they function independently. However, a fundamental yet underexplored question remains: Do they truly operate in isolation, or is there a deeper underlying interplay that has yet to be uncovered? In this paper, we conduct the first comprehensive investigation into this question. By introducing and analyzing the matching mechanism between Core Neurons and Core Tokens, we found that key neurons and tokens for inference mutually influence and reinforce each other. Building on this insight, we propose CoreMatching, a co-adaptive sparse inference framework, which leverages the synergy between token and neuron sparsity to enhance inference efficiency. Through theoretical analysis and efficiency evaluations, we demonstrate that the proposed method surpasses state-of-the-art baselines on ten image understanding tasks and three hardware devices. Notably, on the NVIDIA Titan Xp, it achieved 5x FLOPs reduction and a 10x overall speedup. Code is released at https://github.com/wangqinsi1/2025-ICML-CoreMatching/tree/main.
Proactive Privacy Amnesia for Large Language Models: Safeguarding PII with Negligible Impact on Model Utility
Feb 24, 2025With the rise of large language models (LLMs), increasing research has recognized their risk of leaking personally identifiable information (PII) under malicious attacks. Although efforts have been made to protect PII in LLMs, existing methods struggle to balance privacy protection with maintaining model utility. In this paper, inspired by studies of amnesia in cognitive science, we propose a novel approach, Proactive Privacy Amnesia (PPA), to safeguard PII in LLMs while preserving their utility. This mechanism works by actively identifying and forgetting key memories most closely associated with PII in sequences, followed by a memory implanting using suitable substitute memories to maintain the LLM's functionality. We conduct evaluations across multiple models to protect common PII, such as phone numbers and physical addresses, against prevalent PII-targeted attacks, demonstrating the superiority of our method compared with other existing defensive techniques. The results show that our PPA method completely eliminates the risk of phone number exposure by 100% and significantly reduces the risk of physical address exposure by 9.8% - 87.6%, all while maintaining comparable model utility performance.
H-CoT: Hijacking the Chain-of-Thought Safety Reasoning Mechanism to Jailbreak Large Reasoning Models, Including OpenAI o1/o3, DeepSeek-R1, and Gemini 2.0 Flash Thinking
Feb 18, 2025



Large Reasoning Models (LRMs) have recently extended their powerful reasoning capabilities to safety checks-using chain-of-thought reasoning to decide whether a request should be answered. While this new approach offers a promising route for balancing model utility and safety, its robustness remains underexplored. To address this gap, we introduce Malicious-Educator, a benchmark that disguises extremely dangerous or malicious requests beneath seemingly legitimate educational prompts. Our experiments reveal severe security flaws in popular commercial-grade LRMs, including OpenAI o1/o3, DeepSeek-R1, and Gemini 2.0 Flash Thinking. For instance, although OpenAI's o1 model initially maintains a high refusal rate of about 98%, subsequent model updates significantly compromise its safety; and attackers can easily extract criminal strategies from DeepSeek-R1 and Gemini 2.0 Flash Thinking without any additional tricks. To further highlight these vulnerabilities, we propose Hijacking Chain-of-Thought (H-CoT), a universal and transferable attack method that leverages the model's own displayed intermediate reasoning to jailbreak its safety reasoning mechanism. Under H-CoT, refusal rates sharply decline-dropping from 98% to below 2%-and, in some instances, even transform initially cautious tones into ones that are willing to provide harmful content. We hope these findings underscore the urgent need for more robust safety mechanisms to preserve the benefits of advanced reasoning capabilities without compromising ethical standards.
Min-K%++: Improved Baseline for Detecting Pre-Training Data from Large Language Models
Apr 03, 2024



The problem of pre-training data detection for large language models (LLMs) has received growing attention due to its implications in critical issues like copyright violation and test data contamination. The current state-of-the-art approach, Min-K%, measures the raw token probability which we argue may not be the most informative signal. Instead, we propose Min-K%++ to normalize the token probability with statistics of the categorical distribution over the whole vocabulary, which accurately reflects the relative likelihood of the target token compared with other candidate tokens in the vocabulary. Theoretically, we back up our method by showing that the statistic it estimates is explicitly optimized during LLM training, thus serving as a reliable indicator for detecting training data. Empirically, on the WikiMIA benchmark, Min-K%++ outperforms the SOTA Min-K% by 6.2% to 10.5% in detection AUROC averaged over five models. On the more challenging MIMIR benchmark, Min-K%++ consistently improves upon Min-K% and performs on par with reference-based method, despite not requiring an extra reference model.
DACBERT: Leveraging Dependency Agreement for Cost-Efficient Bert Pretraining
Nov 08, 2023



Building on the cost-efficient pretraining advancements brought about by Crammed BERT, we enhance its performance and interpretability further by introducing a novel pretrained model Dependency Agreement Crammed BERT (DACBERT) and its two-stage pretraining framework - Dependency Agreement Pretraining. This framework, grounded by linguistic theories, seamlessly weaves syntax and semantic information into the pretraining process. The first stage employs four dedicated submodels to capture representative dependency agreements at the chunk level, effectively converting these agreements into embeddings. The second stage uses these refined embeddings, in tandem with conventional BERT embeddings, to guide the pretraining of the rest of the model. Evaluated on the GLUE benchmark, our DACBERT demonstrates notable improvement across various tasks, surpassing Crammed BERT by 3.13% in the RTE task and by 2.26% in the MRPC task. Furthermore, our method boosts the average GLUE score by 0.83%, underscoring its significant potential. The pretraining process can be efficiently executed on a single GPU within a 24-hour cycle, necessitating no supplementary computational resources or extending the pretraining duration compared with the Crammed BERT. Extensive studies further illuminate our approach's instrumental role in bolstering the interpretability of pretrained language models for natural language understanding tasks.
Towards Building the Federated GPT: Federated Instruction Tuning
May 09, 2023



While ``instruction-tuned" generative large language models (LLMs) have demonstrated an impressive ability to generalize to new tasks, the training phases heavily rely on large amounts of diverse and high-quality instruction data (such as ChatGPT and GPT-4). Unfortunately, acquiring high-quality data, especially when it comes to human-written data, can pose significant challenges both in terms of cost and accessibility. Moreover, concerns related to privacy can further limit access to such data, making the process of obtaining it a complex and nuanced undertaking. Consequently, this hinders the generality of the tuned models and may restrict their effectiveness in certain contexts. To tackle this issue, our study introduces a new approach called Federated Instruction Tuning (FedIT), which leverages federated learning (FL) as the learning framework for the instruction tuning of LLMs. This marks the first exploration of FL-based instruction tuning for LLMs. This is especially important since text data is predominantly generated by end users. Therefore, it is imperative to design and adapt FL approaches to effectively leverage these users' diverse instructions stored on local devices, while preserving privacy and ensuring data security. In the current paper, by conducting widely used GPT-4 auto-evaluation, we demonstrate that by exploiting the heterogeneous and diverse sets of instructions on the client's end with the proposed framework FedIT, we improved the performance of LLMs compared to centralized training with only limited local instructions. Further, in this paper, we developed a Github repository named Shepherd. This repository offers a foundational framework for exploring federated fine-tuning of LLMs using heterogeneous instructions across diverse categories.
Tag and Correct: Question aware Open Information Extraction with Two-stage Decoding
Sep 16, 2020
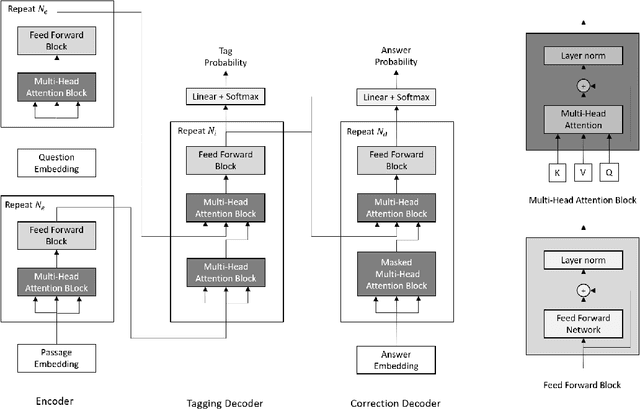


Question Aware Open Information Extraction (Question aware Open IE) takes question and passage as inputs, outputting an answer tuple which contains a subject, a predicate, and one or more arguments. Each field of answer is a natural language word sequence and is extracted from the passage. The semi-structured answer has two advantages which are more readable and falsifiable compared to span answer. There are two approaches to solve this problem. One is an extractive method which extracts candidate answers from the passage with the Open IE model, and ranks them by matching with questions. It fully uses the passage information at the extraction step, but the extraction is independent to the question. The other one is the generative method which uses a sequence to sequence model to generate answers directly. It combines the question and passage as input at the same time, but it generates the answer from scratch, which does not use the facts that most of the answer words come from in the passage. To guide the generation by passage, we present a two-stage decoding model which contains a tagging decoder and a correction decoder. At the first stage, the tagging decoder will tag keywords from the passage. At the second stage, the correction decoder will generate answers based on tagged keywords. Our model could be trained end-to-end although it has two stages. Compared to previous generative models, we generate better answers by generating coarse to fine. We evaluate our model on WebAssertions (Yan et al., 2018) which is a Question aware Open IE dataset. Our model achieves a BLEU score of 59.32, which is better than previous generative methods.