 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepetitionCurse: Measuring and Understanding Router Imbalance in Mixture-of-Experts LLMs under DoS Stress
Dec 30, 2025Mixture-of-Experts architectures have become the standard for scaling large language models due to their superior parameter efficiency. To accommodate the growing number of experts in practice, modern inference systems commonly adopt expert parallelism to distribute experts across devices. However, the absence of explicit load balancing constraints during inference allows adversarial inputs to trigger severe routing concentration. We demonstrate that out-of-distribution prompts can manipulate the routing strategy such that all tokens are consistently routed to the same set of top-$k$ experts, which creates computational bottlenecks on certain devices while forcing others to idle. This converts an efficiency mechanism into a denial-of-service attack vector, leading to violations of service-level agreements for time to first token. We propose RepetitionCurse, a low-cost black-box strategy to exploit this vulnerability. By identifying a universal flaw in MoE router behavior, RepetitionCurse constructs adversarial prompts using simple repetitive token patterns in a model-agnostic manner. On widely deployed MoE models like Mixtral-8x7B, our method increases end-to-end inference latency by 3.063x, degrading service availability significantly.
On Exact Editing of Flow-Based Diffusion Models
Dec 30, 2025Recent methods in flow-based diffusion editing have enabled direct transformations between source and target image distribution without explicit inversion. However, the latent trajectories in these methods often exhibit accumulated velocity errors, leading to semantic inconsistency and loss of structural fidelity. We propose Conditioned Velocity Correction (CVC), a principled framework that reformulates flow-based editing as a distribution transformation problem driven by a known source prior. CVC rethinks the role of velocity in inter-distribution transformation by introducing a dual-perspective velocity conversion mechanism. This mechanism explicitly decomposes the latent evolution into two components: a structure-preserving branch that remains consistent with the source trajectory, and a semantically-guided branch that drives a controlled deviation toward the target distribution. The conditional velocity field exhibits an absolute velocity error relative to the true underlying distribution trajectory, which inherently introduces potential instability and trajectory drift in the latent space. To address this quantifiable deviation and maintain fidelity to the true flow, we apply a posterior-consistent update to the resulting conditional velocity field. This update is derived from Empirical Bayes Inference and Tweedie correction, which ensures a mathematically grounded error compensation over time. Our method yields stable and interpretable latent dynamics, achieving faithful reconstruction alongside smooth local semantic conversion. Comprehensive experiments demonstrate that CVC consistently achieves superior fidelity, better semantic alignment, and more reliable editing behavior across diverse tasks.
Spectral Analysis of Hard-Constraint PINNs: The Spatial Modulation Mechanism of Boundary Functions
Dec 29, 2025Physics-Informed Neural Networks with hard constraints (HC-PINNs) are increasingly favored for their ability to strictly enforce boundary conditions via a trial function ansatz $\tilde{u} = A + B \cdot N$, yet the theoretical mechanisms governing their training dynamics have remained unexplored. Unlike soft-constrained formulations where boundary terms act as additive penalties, this work reveals that the boundary function $B$ introduces a multiplicative spatial modulation that fundamentally alters the learning landscape. A rigorous Neural Tangent Kernel (NTK) framework for HC-PINNs is established, deriving the explicit kernel composition law. This relationship demonstrates that the boundary function $B(\vec{x})$ functions as a spectral filter, reshaping the eigenspectrum of the neural network's native kernel. Through spectral analysis, the effective rank of the residual kernel is identified as a deterministic predictor of training convergence, superior to classical condition numbers. It is shown that widely used boundary functions can inadvertently induce spectral collapse, leading to optimization stagnation despite exact boundary satisfaction. Validated across multi-dimensional benchmarks, this framework transforms the design of boundary functions from a heuristic choice into a principled spectral optimization problem, providing a solid theoretical foundation for geometric hard constraints in scientific machine learning.
MindWatcher: Toward Smarter Multimodal Tool-Integrated Reasoning
Dec 29, 2025Traditional workflow-based agents exhibit limited intelligence when addressing real-world problems requiring tool invocation. Tool-integrated reasoning (TIR) agents capable of autonomous reasoning and tool invocation are rapidly emerging as a powerful approach for complex decision-making tasks involving multi-step interactions with external environments. In this work, we introduce MindWatcher, a TIR agent integrating interleaved thinking and multimodal chain-of-thought (CoT) reasoning. MindWatcher can autonomously decide whether and how to invoke diverse tools and coordinate their use, without relying on human prompts or workflows. The interleaved thinking paradigm enables the model to switch between thinking and tool calling at any intermediate stage, while its multimodal CoT capability allows manipulation of images during reasoning to yield more precise search results. We implement automated data auditing and evaluation pipelines, complemented by manually curated high-quality datasets for training, and we construct a benchmark, called MindWatcher-Evaluate Bench (MWE-Bench), to evaluate its performance. MindWatcher is equipped with a comprehensive suite of auxiliary reasoning tools, enabling it to address broad-domain multimodal problems. A large-scale, high-quality local image retrieval database, covering eight categories including cars, animals, and plants, endows model with robust object recognition despite its small size. Finally, we design a more efficient training infrastructure for MindWatcher, enhancing training speed and hardware utilization. Experiments not only demonstrate that MindWatcher matches or exceeds the performance of larger or more recent models through superior tool invocation, but also uncover critical insights for agent training, such as the genetic inheritance phenomenon in agentic RL.
RollArt: Scaling Agentic RL Training via Disaggregated Infrastructure
Dec 27, 2025Agentic Reinforcement Learning (RL) enables Large Language Models (LLMs) to perform autonomous decision-making and long-term planning. Unlike standard LLM post-training, agentic RL workloads are highly heterogeneous, combining compute-intensive prefill phases, bandwidth-bound decoding, and stateful, CPU-heavy environment simulations. We argue that efficient agentic RL training requires disaggregated infrastructure to leverage specialized, best-fit hardware. However, naive disaggregation introduces substantial synchronization overhead and resource underutilization due to the complex dependencies between stages. We present RollArc, a distributed system designed to maximize throughput for multi-task agentic RL on disaggregated infrastructure. RollArc is built on three core principles: (1) hardware-affinity workload mapping, which routes compute-bound and bandwidth-bound tasks to bestfit GPU devices, (2) fine-grained asynchrony, which manages execution at the trajectory level to mitigate resource bubbles, and (3) statefulness-aware computation, which offloads stateless components (e.g., reward models) to serverless infrastructure for elastic scaling. Our results demonstrate that RollArc effectively improves training throughput and achieves 1.35-2.05\(\times\) end-to-end training time reduction compared to monolithic and synchronous baselines. We also evaluate RollArc by training a hundreds-of-billions-parameter MoE model for Qoder product on an Alibaba cluster with more than 3,000 GPUs, further demonstrating RollArc scalability and robustness. The code is available at https://github.com/alibaba/ROLL.
Generative Actor Critic
Dec 25, 2025Conventional Reinforcement Learning (RL) algorithms, typically focused on estimating or maximizing expected returns, face challenges when refining offline pretrained models with online experiences. This paper introduces Generative Actor Critic (GAC), a novel framework that decouples sequential decision-making by reframing \textit{policy evaluation} as learning a generative model of the joint distribution over trajectories and returns, $p(τ, y)$, and \textit{policy improvement} as performing versatile inference on this learned model. To operationalize GAC, we introduce a specific instantiation based on a latent variable model that features continuous latent plan vectors. We develop novel inference strategies for both \textit{exploitation}, by optimizing latent plans to maximize expected returns, and \textit{exploration}, by sampling latent plans conditioned on dynamically adjusted target returns. Experiments on Gym-MuJoCo and Maze2D benchmarks demonstrate GAC's strong offline performance and significantly enhanced offline-to-online improvement compared to state-of-the-art methods, even in absence of step-wise rewards.
Efficient MoE Inference with Fine-Grained Scheduling of Disaggregated Expert Parallelism
Dec 25, 2025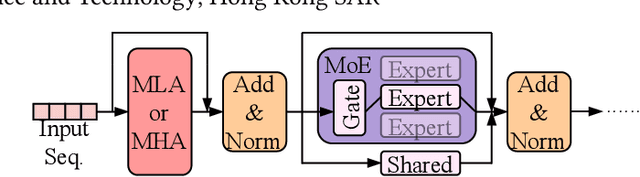

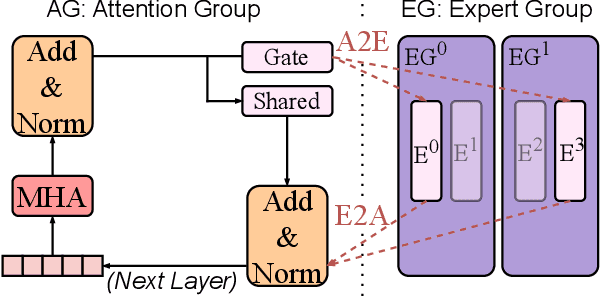
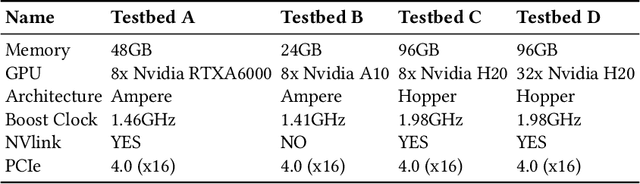
The mixture-of-experts (MoE) architecture scales model size with sublinear computational increase but suffers from memory-intensive inference due to KV caches and sparse expert activation. Recent disaggregated expert parallelism (DEP) distributes attention and experts to dedicated GPU groups but lacks support for shared experts and efficient task scheduling, limiting performance. We propose FinDEP, a fine-grained task scheduling algorithm for DEP that maximizes task overlap to improve MoE inference throughput. FinDEP introduces three innovations: 1) partitioning computation/communication into smaller tasks for fine-grained pipelining, 2) formulating a scheduling optimization supporting variable granularity and ordering, and 3) developing an efficient solver for this large search space. Experiments on four GPU systems with DeepSeek-V2 and Qwen3-MoE show FinDEP improves throughput by up to 1.61x over prior methods, achieving up to 1.24x speedup on a 32-GPU system.
TongSIM: A General Platform for Simulating Intelligent Machines
Dec 23, 2025As artificial intelligence (AI) rapidly advances, especially in multimodal large language models (MLLMs), research focus is shifting from single-modality text processing to the more complex domains of multimodal and embodied AI. Embodied intelligence focuses on training agents within realistic simulated environments, leveraging physical interaction and action feedback rather than conventionally labeled datasets. Yet, most existing simulation platforms remain narrowly designed, each tailored to specific tasks. A versatile, general-purpose training environment that can support everything from low-level embodied navigation to high-level composite activities, such as multi-agent social simulation and human-AI collaboration, remains largely unavailable. To bridge this gap, we introduce TongSIM, a high-fidelity, general-purpose platform for training and evaluating embodied agents. TongSIM offers practical advantages by providing over 100 diverse, multi-room indoor scenarios as well as an open-ended, interaction-rich outdoor town simulation, ensuring broad applicability across research needs. Its comprehensive evaluation framework and benchmarks enable precise assessment of agent capabilities, such as perception, cognition, decision-making, human-robot cooperation, and spatial and social reasoning. With features like customized scenes, task-adaptive fidelity, diverse agent types, and dynamic environmental simulation, TongSIM delivers flexibility and scalability for researchers, serving as a unified platform that accelerates training, evaluation, and advancement toward general embodied intelligence.
Open-Source Multimodal Moxin Models with Moxin-VLM and Moxin-VLA
Dec 22, 2025Recently, Large Language Models (LLMs) have undergone a significant transformation, marked by a rapid rise in both their popularity and capabilities. Leading this evolution are proprietary LLMs like GPT-4 and GPT-o1, which have captured widespread attention in the AI community due to their remarkable performance and versatility. Simultaneously, open-source LLMs, such as LLaMA and Mistral, have made great contributions to the ever-increasing popularity of LLMs due to the ease to customize and deploy the models across diverse applications. Moxin 7B is introduced as a fully open-source LLM developed in accordance with the Model Openness Framework, which moves beyond the simple sharing of model weights to embrace complete transparency in training, datasets, and implementation detail, thus fostering a more inclusive and collaborative research environment that can sustain a healthy open-source ecosystem. To further equip Moxin with various capabilities in different tasks, we develop three variants based on Moxin, including Moxin-VLM, Moxin-VLA, and Moxin-Chinese, which target the vision-language, vision-language-action, and Chinese capabilities, respectively. Experiments show that our models achieve superior performance in various evaluations. We adopt open-source framework and open data for the training. We release our models, along with the available data and code to derive these models.
PhysMaster: Building an Autonomous AI Physicist for Theoretical and Computational Physics Research
Dec 22, 2025Advances in LLMs have produced agents with knowledge and operational capabilities comparable to human scientists, suggesting potential to assist, accelerate, and automate research. However, existing studies mainly evaluate such systems on well-defined benchmarks or general tasks like literature retrieval, limiting their end-to-end problem-solving ability in open scientific scenarios. This is particularly true in physics, which is abstract, mathematically intensive, and requires integrating analytical reasoning with code-based computation. To address this, we propose PhysMaster, an LLM-based agent functioning as an autonomous theoretical and computational physicist. PhysMaster couples absract reasoning with numerical computation and leverages LANDAU, the Layered Academic Data Universe, which preserves retrieved literature, curated prior knowledge, and validated methodological traces, enhancing decision reliability and stability. It also employs an adaptive exploration strategy balancing efficiency and open-ended exploration, enabling robust performance in ultra-long-horizon tasks. We evaluate PhysMaster on problems from high-energy theory, condensed matter theory to astrophysics, including: (i) acceleration, compressing labor-intensive research from months to hours; (ii) automation, autonomously executing hypothesis-driven loops ; and (iii) autonomous discovery, independently exploring open problems.