 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll-in-One Slider for Attribute Manipulation in Diffusion Models
Aug 26, 2025Text-to-image (T2I) diffusion models have made significant strides in generating high-quality images. However, progressively manipulating certain attributes of generated images to meet the desired user expectations remains challenging, particularly for content with rich details, such as human faces. Some studies have attempted to address this by training slider modules. However, they follow a One-for-One manner, where an independent slider is trained for each attribute, requiring additional training whenever a new attribute is introduced. This not only results in parameter redundancy accumulated by sliders but also restricts the flexibility of practical applications and the scalability of attribute manipulation. To address this issue, we introduce the All-in-One Slider, a lightweight module that decomposes the text embedding space into sparse, semantically meaningful attribute directions. Once trained, it functions as a general-purpose slider, enabling interpretable and fine-grained continuous control over various attributes. Moreover, by recombining the learned directions, the All-in-One Slider supports zero-shot manipulation of unseen attributes (e.g., races and celebrities) and the composition of multiple attributes. Extensive experiments demonstrate that our method enables accurate and scalable attribute manipulation, achieving notable improvements compared to previous methods. Furthermore, our method can be extended to integrate with the inversion framework to perform attribute manipulation on real images, broadening its applicability to various real-world scenarios. The code and trained model will be released at: https://github.com/ywxsuperstar/KSAE-FaceSteer.
Enabling MoE on the Edge via Importance-Driven Expert Scheduling
Aug 26, 2025



The Mixture of Experts (MoE) architecture has emerged as a key technique for scaling Large Language Models by activating only a subset of experts per query. Deploying MoE on consumer-grade edge hardware, however, is constrained by limited device memory, making dynamic expert offloading essential. Unlike prior work that treats offloading purely as a scheduling problem, we leverage expert importance to guide decisions, substituting low-importance activated experts with functionally similar ones already cached in GPU memory, thereby preserving accuracy. As a result, this design reduces memory usage and data transfer, while largely eliminating PCIe overhead. In addition, we introduce a scheduling policy that maximizes the reuse ratio of GPU-cached experts, further boosting efficiency. Extensive evaluations show that our approach delivers 48% lower decoding latency with over 60% expert cache hit rate, while maintaining nearly lossless accuracy.
Instant Preference Alignment for Text-to-Image Diffusion Models
Aug 25, 2025Text-to-image (T2I) generation has greatly enhanced creative expression, yet achieving preference-aligned generation in a real-time and training-free manner remains challenging. Previous methods often rely on static, pre-collected preferences or fine-tuning, limiting adaptability to evolving and nuanced user intents. In this paper, we highlight the need for instant preference-aligned T2I generation and propose a training-free framework grounded in multimodal large language model (MLLM) priors. Our framework decouples the task into two components: preference understanding and preference-guided generation. For preference understanding, we leverage MLLMs to automatically extract global preference signals from a reference image and enrich a given prompt using structured instruction design. Our approach supports broader and more fine-grained coverage of user preferences than existing methods. For preference-guided generation, we integrate global keyword-based control and local region-aware cross-attention modulation to steer the diffusion model without additional training, enabling precise alignment across both global attributes and local elements. The entire framework supports multi-round interactive refinement, facilitating real-time and context-aware image generation. Extensive experiments on the Viper dataset and our collected benchmark demonstrate that our method outperforms prior approaches in both quantitative metrics and human evaluations, and opens up new possibilities for dialog-based generation and MLLM-diffusion integration.
Robustness Feature Adapter for Efficient Adversarial Training
Aug 25, 2025Adversarial training (AT) with projected gradient descent is the most popular method to improve model robustness under adversarial attacks. However, computational overheads become prohibitively large when AT is applied to large backbone models. AT is also known to have the issue of robust overfitting. This paper contributes to solving both problems simultaneously towards building more trustworthy foundation models. In particular, we propose a new adapter-based approach for efficient AT directly in the feature space. We show that the proposed adapter-based approach can improve the inner-loop convergence quality by eliminating robust overfitting. As a result, it significantly increases computational efficiency and improves model accuracy by generalizing adversarial robustness to unseen attacks. We demonstrate the effectiveness of the new adapter-based approach in different backbone architectures and in AT at scale.
Mind the Gap: The Divergence Between Human and LLM-Generated Tasks
Aug 01, 2025Humans constantly generate a diverse range of tasks guided by internal motivations. While generative agents powered by large language models (LLMs) aim to simulate this complex behavior, it remains uncertain whether they operate on similar cognitive principles. To address this, we conducted a task-generation experiment comparing human responses with those of an LLM agent (GPT-4o). We find that human task generation is consistently influenced by psychological drivers, including personal values (e.g., Openness to Change) and cognitive style. Even when these psychological drivers are explicitly provided to the LLM, it fails to reflect the corresponding behavioral patterns. They produce tasks that are markedly less social, less physical, and thematically biased toward abstraction. Interestingly, while the LLM's tasks were perceived as more fun and novel, this highlights a disconnect between its linguistic proficiency and its capacity to generate human-like, embodied goals.We conclude that there is a core gap between the value-driven, embodied nature of human cognition and the statistical patterns of LLMs, highlighting the necessity of incorporating intrinsic motivation and physical grounding into the design of more human-aligned agents.
On Uncertainty Prediction for Deep-Learning-based Particle Image Velocimetry
Jul 27, 2025Particle Image Velocimetry (PIV) is a widely used technique for flow measurement that traditionally relies on cross-correlation to track the displacement. Recent advances in deep learning-based methods have significantly improved the accuracy and efficiency of PIV measurements. However, despite its importance, reliable uncertainty quantification for deep learning-based PIV remains a critical and largely overlooked challenge. This paper explores three methods for quantifying uncertainty in deep learning-based PIV: the Uncertainty neural network (UNN), Multiple models (MM), and Multiple transforms (MT). We evaluate the three methods across multiple datasets. The results show that all three methods perform well under mild perturbations. Among the three evaluation metrics, the UNN method consistently achieves the best performance, providing accurate uncertainty estimates and demonstrating strong potential for uncertainty quantification in deep learning-based PIV. This study provides a comprehensive framework for uncertainty quantification in PIV, offering insights for future research and practical implementation.
Agentar-Fin-R1: Enhancing Financial Intelligence through Domain Expertise, Training Efficiency, and Advanced Reasoning
Jul 24, 2025Large Language Models (LLMs) exhibit considerable promise in financial applications; however, prevailing models frequently demonstrate limitations when confronted with scenarios that necessitate sophisticated reasoning capabilities, stringent trustworthiness criteria, and efficient adaptation to domain-specific requirements. We introduce the Agentar-Fin-R1 series of financial large language models (8B and 32B parameters), specifically engineered based on the Qwen3 foundation model to enhance reasoning capabilities, reliability, and domain specialization for financial applications. Our optimization approach integrates a high-quality, systematic financial task label system with a comprehensive multi-layered trustworthiness assurance framework. This framework encompasses high-quality trustworthy knowledge engineering, multi-agent trustworthy data synthesis, and rigorous data validation governance. Through label-guided automated difficulty-aware optimization, tow-stage training pipeline, and dynamic attribution systems, we achieve substantial improvements in training efficiency. Our models undergo comprehensive evaluation on mainstream financial benchmarks including Fineva, FinEval, and FinanceIQ, as well as general reasoning datasets such as MATH-500 and GPQA-diamond. To thoroughly assess real-world deployment capabilities, we innovatively propose the Finova evaluation benchmark, which focuses on agent-level financial reasoning and compliance verification. Experimental results demonstrate that Agentar-Fin-R1 not only achieves state-of-the-art performance on financial tasks but also exhibits exceptional general reasoning capabilities, validating its effectiveness as a trustworthy solution for high-stakes financial applications. The Finova bench is available at https://github.com/antgroup/Finova.
SplitMeanFlow: Interval Splitting Consistency in Few-Step Generative Modeling
Jul 22, 2025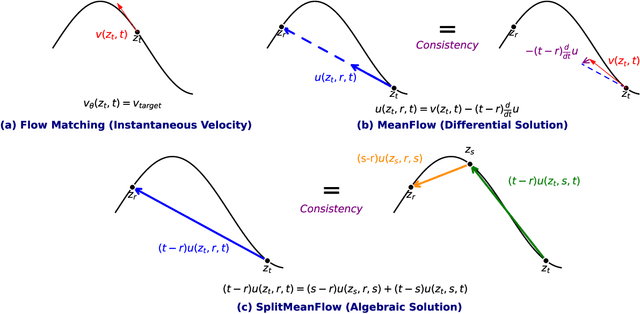


Generative models like Flow Matching have achieved state-of-the-art performance but are often hindered by a computationally expensive iterative sampling process. To address this, recent work has focused on few-step or one-step generation by learning the average velocity field, which directly maps noise to data. MeanFlow, a leading method in this area, learns this field by enforcing a differential identity that connects the average and instantaneous velocities. In this work, we argue that this differential formulation is a limiting special case of a more fundamental principle. We return to the first principles of average velocity and leverage the additivity property of definite integrals. This leads us to derive a novel, purely algebraic identity we term Interval Splitting Consistency. This identity establishes a self-referential relationship for the average velocity field across different time intervals without resorting to any differential operators. Based on this principle, we introduce SplitMeanFlow, a new training framework that enforces this algebraic consistency directly as a learning objective. We formally prove that the differential identity at the core of MeanFlow is recovered by taking the limit of our algebraic consistency as the interval split becomes infinitesimal. This establishes SplitMeanFlow as a direct and more general foundation for learning average velocity fields. From a practical standpoint, our algebraic approach is significantly more efficient, as it eliminates the need for JVP computations, resulting in simpler implementation, more stable training, and broader hardware compatibility. One-step and two-step SplitMeanFlow models have been successfully deployed in large-scale speech synthesis products (such as Doubao), achieving speedups of 20x.
UniLGL: Learning Uniform Place Recognition for FOV-limited/Panoramic LiDAR Global Localization
Jul 16, 2025Existing LGL methods typically consider only partial information (e.g., geometric features) from LiDAR observations or are designed for homogeneous LiDAR sensors, overlooking the uniformity in LGL. In this work, a uniform LGL method is proposed, termed UniLGL, which simultaneously achieves spatial and material uniformity, as well as sensor-type uniformity. The key idea of the proposed method is to encode the complete point cloud, which contains both geometric and material information, into a pair of BEV images (i.e., a spatial BEV image and an intensity BEV image). An end-to-end multi-BEV fusion network is designed to extract uniform features, equipping UniLGL with spatial and material uniformity. To ensure robust LGL across heterogeneous LiDAR sensors, a viewpoint invariance hypothesis is introduced, which replaces the conventional translation equivariance assumption commonly used in existing LPR networks and supervises UniLGL to achieve sensor-type uniformity in both global descriptors and local feature representations. Finally, based on the mapping between local features on the 2D BEV image and the point cloud, a robust global pose estimator is derived that determines the global minimum of the global pose on SE(3) without requiring additional registration. To validate the effectiveness of the proposed uniform LGL, extensive benchmarks are conducted in real-world environments, and the results show that the proposed UniLGL is demonstratively competitive compared to other State-of-the-Art LGL methods. Furthermore, UniLGL has been deployed on diverse platforms, including full-size trucks and agile Micro Aerial Vehicles (MAVs), to enable high-precision localization and mapping as well as multi-MAV collaborative exploration in port and forest environments, demonstrating the applicability of UniLGL in industrial and field scenarios.
Stable-Hair v2: Real-World Hair Transfer via Multiple-View Diffusion Model
Jul 10, 2025



While diffusion-based methods have shown impressive capabilities in capturing diverse and complex hairstyles, their ability to generate consistent and high-quality multi-view outputs -- crucial for real-world applications such as digital humans and virtual avatars -- remains underexplored. In this paper, we propose Stable-Hair v2, a novel diffusion-based multi-view hair transfer framework. To the best of our knowledge, this is the first work to leverage multi-view diffusion models for robust, high-fidelity, and view-consistent hair transfer across multiple perspectives. We introduce a comprehensive multi-view training data generation pipeline comprising a diffusion-based Bald Converter, a data-augment inpainting model, and a face-finetuned multi-view diffusion model to generate high-quality triplet data, including bald images, reference hairstyles, and view-aligned source-bald pairs. Our multi-view hair transfer model integrates polar-azimuth embeddings for pose conditioning and temporal attention layers to ensure smooth transitions between views. To optimize this model, we design a novel multi-stage training strategy consisting of pose-controllable latent IdentityNet training, hair extractor training, and temporal attention training. Extensive experiments demonstrate that our method accurately transfers detailed and realistic hairstyles to source subjects while achieving seamless and consistent results across views, significantly outperforming existing methods and establishing a new benchmark in multi-view hair transfer. Code is publicly available at https://github.com/sunkymepro/StableHairV2.