 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-STaR: Benchmarking Video-LLMs on Video Spatio-Temporal Reasoning
Mar 14, 2025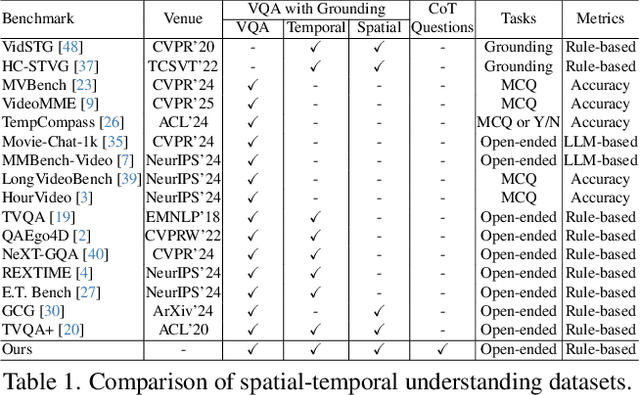
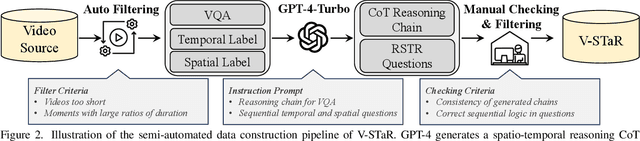

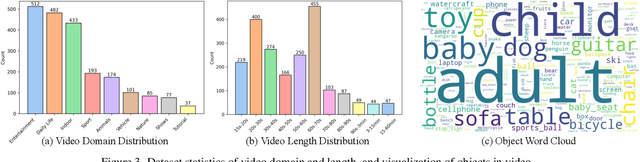
Human processes video reasoning in a sequential spatio-temporal reasoning logic, we first identify the relevant frames ("when") and then analyse the spatial relationships ("where") between key objects, and finally leverage these relationships to draw inferences ("what"). However, can Video Large Language Models (Video-LLMs) also "reason through a sequential spatio-temporal logic" in videos? Existing Video-LLM benchmarks primarily focus on assessing object presence, neglecting relational reasoning. Consequently, it is difficult to measure whether a model truly comprehends object interactions (actions/events) in videos or merely relies on pre-trained "memory" of co-occurrences as biases in generating answers. In this work, we introduce a Video Spatio-Temporal Reasoning (V-STaR) benchmark to address these shortcomings. The key idea is to decompose video understanding into a Reverse Spatio-Temporal Reasoning (RSTR) task that simultaneously evaluates what objects are present, when events occur, and where they are located while capturing the underlying Chain-of-thought (CoT) logic. To support this evaluation, we construct a dataset to elicit the spatial-temporal reasoning process of Video-LLMs. It contains coarse-to-fine CoT questions generated by a semi-automated GPT-4-powered pipeline, embedding explicit reasoning chains to mimic human cognition. Experiments from 14 Video-LLMs on our V-STaR reveal significant gaps between current Video-LLMs and the needs for robust and consistent spatio-temporal reasoning.
Odysseus Navigates the Sirens' Song: Dynamic Focus Decoding for Factual and Diverse Open-Ended Text Generation
Mar 11, 2025Large Language Models (LLMs) are increasingly required to generate text that is both factually accurate and diverse across various open-ended applications. However, current stochastic decoding methods struggle to balance such objectives. We introduce Dynamic Focus Decoding (DFD), a novel plug-and-play stochastic approach that resolves this trade-off without requiring additional data, knowledge, or models. DFD adaptively adjusts the decoding focus based on distributional differences across layers, leveraging the modular and hierarchical nature of factual knowledge within LLMs. This dynamic adjustment improves factuality in knowledge-intensive decoding steps and promotes diversity in less knowledge-reliant steps. DFD can be easily integrated with existing decoding methods, enhancing both factuality and diversity with minimal computational overhead. Extensive experiments across seven datasets demonstrate that DFD significantly improves performance, providing a scalable and efficient solution for open-ended text generation.
FEA-Bench: A Benchmark for Evaluating Repository-Level Code Generation for Feature Implementation
Mar 09, 2025Implementing new features in repository-level codebases is a crucial application of code generation models. However, current benchmarks lack a dedicated evaluation framework for this capability. To fill this gap, we introduce FEA-Bench, a benchmark designed to assess the ability of large language models (LLMs) to perform incremental development within code repositories. We collect pull requests from 83 GitHub repositories and use rule-based and intent-based filtering to construct task instances focused on new feature development. Each task instance containing code changes is paired with relevant unit test files to ensure that the solution can be verified. The feature implementation requires LLMs to simultaneously possess code completion capabilities for new components and code editing abilities for other relevant parts in the code repository, providing a more comprehensive evaluation method of LLMs' automated software engineering capabilities. Experimental results show that LLMs perform significantly worse in the FEA-Bench, highlighting considerable challenges in such repository-level incremental code development.
MagicInfinite: Generating Infinite Talking Videos with Your Words and Voice
Mar 07, 2025We present MagicInfinite, a novel diffusion Transformer (DiT) framework that overcomes traditional portrait animation limitations, delivering high-fidelity results across diverse character types-realistic humans, full-body figures, and stylized anime characters. It supports varied facial poses, including back-facing views, and animates single or multiple characters with input masks for precise speaker designation in multi-character scenes. Our approach tackles key challenges with three innovations: (1) 3D full-attention mechanisms with a sliding window denoising strategy, enabling infinite video generation with temporal coherence and visual quality across diverse character styles; (2) a two-stage curriculum learning scheme, integrating audio for lip sync, text for expressive dynamics, and reference images for identity preservation, enabling flexible multi-modal control over long sequences; and (3) region-specific masks with adaptive loss functions to balance global textual control and local audio guidance, supporting speaker-specific animations. Efficiency is enhanced via our innovative unified step and cfg distillation techniques, achieving a 20x inference speed boost over the basemodel: generating a 10 second 540x540p video in 10 seconds or 720x720p in 30 seconds on 8 H100 GPUs, without quality loss. Evaluations on our new benchmark demonstrate MagicInfinite's superiority in audio-lip synchronization, identity preservation, and motion naturalness across diverse scenarios. It is publicly available at https://www.hedra.com/, with examples at https://magicinfinite.github.io/.
Spatial Distillation based Distribution Alignment (SDDA) for Cross-Headset EEG Classification
Mar 07, 2025A non-invasive brain-computer interface (BCI) enables direct interaction between the user and external devices, typically via electroencephalogram (EEG) signals. However, decoding EEG signals across different headsets remains a significant challenge due to differences in the number and locations of the electrodes. To address this challenge, we propose a spatial distillation based distribution alignment (SDDA) approach for heterogeneous cross-headset transfer in non-invasive BCIs. SDDA uses first spatial distillation to make use of the full set of electrodes, and then input/feature/output space distribution alignments to cope with the significant differences between the source and target domains. To our knowledge, this is the first work to use knowledge distillation in cross-headset transfers. Extensive experiments on six EEG datasets from two BCI paradigms demonstrated that SDDA achieved superior performance in both offline unsupervised domain adaptation and online supervised domain adaptation scenarios, consistently outperforming 10 classical and state-of-the-art transfer learning algorithms.
Feature Point Extraction for Extra-Affine Image
Mar 05, 2025The issue concerning the significant decline in the stability of feature extraction for images subjected to large-angle affine transformations, where the angle exceeds 50 degrees, still awaits a satisfactory solution. Even ASIFT, which is built upon SIFT and entails a considerable number of image comparisons simulated by affine transformations, inevitably exhibits the drawbacks of being time-consuming and imposing high demands on memory usage. And the stability of feature extraction drops rapidly under large-view affine transformations. Consequently, we propose a method that represents an improvement over ASIFT. On the premise of improving the precision and maintaining the affine invariance, it currently ranks as the fastest feature extraction method for extra-affine images that we know of at present. Simultaneously, the stability of feature extraction regarding affine transformation images has been approximated to the maximum limits. Both the angle between the shooting direction and the normal direction of the photographed object (absolute tilt angle), and the shooting transformation angle between two images (transition tilt angle) are close to 90 degrees. The central idea of the method lies in obtaining the optimal parameter set by simulating affine transformation with the reference image. And the simulated affine transformation is reproduced by combining it with the Lanczos interpolation based on the optimal parameter set. Subsequently, it is combined with ORB, which exhibits excellent real-time performance for rapid orientation binary description. Moreover, a scale parameter simulation is introduced to further augment the operational efficiency.
LION-FS: Fast & Slow Video-Language Thinker as Online Video Assistant
Mar 05, 2025



First-person video assistants are highly anticipated to enhance our daily lives through online video dialogue. However, existing online video assistants often sacrifice assistant efficacy for real-time efficiency by processing low-frame-rate videos with coarse-grained visual features.To overcome the trade-off between efficacy and efficiency, we propose "Fast & Slow Video-Language Thinker" as an onLIne videO assistaNt, LION-FS, achieving real-time, proactive, temporally accurate, and contextually precise responses. LION-FS adopts a two-stage optimization strategy: 1)Fast Path: Routing-Based Response Determination evaluates frame-by-frame whether an immediate response is necessary. To enhance response determination accuracy and handle higher frame-rate inputs efficiently, we employ Token Aggregation Routing to dynamically fuse spatiotemporal features without increasing token numbers, while utilizing Token Dropping Routing to eliminate redundant features. 2)Slow Path: Multi-granularity Keyframe Augmentation optimizes keyframes during response generation. To provide comprehensive and detailed responses beyond atomic actions constrained by training data, fine-grained spatial features and human-environment interaction features are extracted through multi-granular pooling. These features are further integrated into a meticulously designed multimodal Thinking Template to guide more precise response generation. Comprehensive evaluations on online video tasks demonstrate that LION-FS achieves state-of-the-art efficacy and efficiency.
EliteKV: Scalable KV Cache Compression via RoPE Frequency Selection and Joint Low-Rank Projection
Mar 03, 2025



Rotary Position Embedding (RoPE) enables each attention head to capture multi-frequency information along the sequence dimension and is widely applied in foundation models. However, the nonlinearity introduced by RoPE complicates optimization of the key state in the Key-Value (KV) cache for RoPE-based attention. Existing KV cache compression methods typically store key state before rotation and apply the transformation during decoding, introducing additional computational overhead. This paper introduces EliteKV, a flexible modification framework for RoPE-based models supporting variable KV cache compression ratios. EliteKV first identifies the intrinsic frequency preference of each head using RoPElite, selectively restoring linearity to certain dimensions of key within attention computation. Building on this, joint low-rank compression of key and value enables partial cache sharing. Experimental results show that with minimal uptraining on only $0.6\%$ of the original training data, RoPE-based models achieve a $75\%$ reduction in KV cache size while preserving performance within a negligible margin. Furthermore, EliteKV consistently performs well across models of different scales within the same family.
Fine-Grained Controllable Apparel Showcase Image Generation via Garment-Centric Outpainting
Mar 03, 2025In this paper, we propose a novel garment-centric outpainting (GCO) framework based on the latent diffusion model (LDM) for fine-grained controllable apparel showcase image generation. The proposed framework aims at customizing a fashion model wearing a given garment via text prompts and facial images. Different from existing methods, our framework takes a garment image segmented from a dressed mannequin or a person as the input, eliminating the need for learning cloth deformation and ensuring faithful preservation of garment details. The proposed framework consists of two stages. In the first stage, we introduce a garment-adaptive pose prediction model that generates diverse poses given the garment. Then, in the next stage, we generate apparel showcase images, conditioned on the garment and the predicted poses, along with specified text prompts and facial images. Notably, a multi-scale appearance customization module (MS-ACM) is designed to allow both overall and fine-grained text-based control over the generated model's appearance. Moreover, we leverage a lightweight feature fusion operation without introducing any extra encoders or modules to integrate multiple conditions, which is more efficient. Extensive experiments validate the superior performance of our framework compared to state-of-the-art methods.
MIGE: A Unified Framework for Multimodal Instruction-Based Image Generation and Editing
Feb 28, 2025Despite significant progress in diffusion-based image generation, subject-driven generation and instruction-based editing remain challenging. Existing methods typically treat them separately, struggling with limited high-quality data and poor generalization. However, both tasks require capturing complex visual variations while maintaining consistency between inputs and outputs. Therefore, we propose MIGE, a unified framework that standardizes task representations using multimodal instructions. It treats subject-driven generation as creation on a blank canvas and instruction-based editing as modification of an existing image, establishing a shared input-output formulation. MIGE introduces a novel multimodal encoder that maps free-form multimodal instructions into a unified vision-language space, integrating visual and semantic features through a feature fusion mechanism.This unification enables joint training of both tasks, providing two key advantages: (1) Cross-Task Enhancement: By leveraging shared visual and semantic representations, joint training improves instruction adherence and visual consistency in both subject-driven generation and instruction-based editing. (2) Generalization: Learning in a unified format facilitates cross-task knowledge transfer, enabling MIGE to generalize to novel compositional tasks, including instruction-based subject-driven editing. Experiments show that MIGE excels in both subject-driven generation and instruction-based editing while setting a state-of-the-art in the new task of instruction-based subject-driven editing. Code and model have been publicly available at https://github.com/Eureka-Maggie/MIGE.