 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressive sensing inspired self-supervised single-pixel imaging
Mar 31, 2026Single-pixel imaging (SPI) is a promising imaging modality with distinctive advantages in strongly perturbed environments. Existing SPI methods lack physical sparsity constraints and overlook the integration of local and global features, leading to severe noise vulnerability, structural distortions and blurred details. To address these limitations, we propose SISTA-Net, a compressive sensing-inspired self-supervised method for single-pixel imaging. SISTA-Net unfolds the Iterative Shrinkage-Thresholding Algorithm (ISTA) into an interpretable network consisting of a data fidelity module and a proximal mapping module. The fidelity module adopts a hybrid CNN-Visual State Space Model (VSSM) architecture to integrate local and global feature modeling, enhancing reconstruction integrity and fidelity. We leverage deep nonlinear networks as adaptive sparse transforms combined with a learnable soft-thresholding operator to impose explicit physical sparsity in the latent domain, enabling noise suppression and robustness to interference even at extremely low sampling rates. Extensive experiments on multiple simulation scenarios demonstrate that SISTA-Net outperforms state-of-the-art methods by 2.6 dB in PSNR. Real-world far-field underwater tests yield a 3.4 dB average PSNR improvement, validating its robust anti-interference capability.
Advancing Visual Reliability: Color-Accurate Underwater Image Enhancement for Real-Time Underwater Missions
Mar 17, 2026Underwater image enhancement plays a crucial role in providing reliable visual information for underwater platforms, since strong absorption and scattering in water-related environments generally lead to image quality degradation. Existing high-performance methods often rely on complex architectures, which hinder deployment on underwater devices. Lightweight methods often sacrifice quality for speed and struggle to handle severely degraded underwater images. To address this limitation, we present a real-time underwater image enhancement framework with accurate color restoration. First, an Adaptive Weighted Channel Compensation module is introduced to achieve dynamic color recovery of the red and blue channels using the green channel as a reference anchor. Second, we design a Multi-branch Re-parameterized Dilated Convolution that employs multi-branch fusion during training and structural re-parameterization during inference, enabling large receptive field representation with low computational overhead. Finally, a Statistical Global Color Adjustment module is employed to optimize overall color performance based on statistical priors. Extensive experiments on eight datasets demonstrate that the proposed method achieves state-of-the-art performance across seven evaluation metrics. The model contains only 3,880 inference parameters and achieves an inference speed of 409 FPS. Our method improves the UCIQE score by 29.7% under diverse environmental conditions, and the deployment on ROV platforms and performance gains in downstream tasks further validate its superiority for real-time underwater missions.
A Generative Data Framework with Authentic Supervision for Underwater Image Restoration and Enhancement
Nov 18, 2025Underwater image restoration and enhancement are crucial for correcting color distortion and restoring image details, thereby establishing a fundamental basis for subsequent underwater visual tasks. However, current deep learning methodologies in this area are frequently constrained by the scarcity of high-quality paired datasets. Since it is difficult to obtain pristine reference labels in underwater scenes, existing benchmarks often rely on manually selected results from enhancement algorithms, providing debatable reference images that lack globally consistent color and authentic supervision. This limits the model's capabilities in color restoration, image enhancement, and generalization. To overcome this limitation, we propose using in-air natural images as unambiguous reference targets and translating them into underwater-degraded versions, thereby constructing synthetic datasets that provide authentic supervision signals for model learning. Specifically, we establish a generative data framework based on unpaired image-to-image translation, producing a large-scale dataset that covers 6 representative underwater degradation types. The framework constructs synthetic datasets with precise ground-truth labels, which facilitate the learning of an accurate mapping from degraded underwater images to their pristine scene appearances. Extensive quantitative and qualitative experiments across 6 representative network architectures and 3 independent test sets show that models trained on our synthetic data achieve comparable or superior color restoration and generalization performance to those trained on existing benchmarks. This research provides a reliable and scalable data-driven solution for underwater image restoration and enhancement. The generated dataset is publicly available at: https://github.com/yftian2025/SynUIEDatasets.git.
ZeroBP: Learning Position-Aware Correspondence for Zero-shot 6D Pose Estimation in Bin-Picking
Feb 03, 2025



Bin-picking is a practical and challenging robotic manipulation task, where accurate 6D pose estimation plays a pivotal role. The workpieces in bin-picking are typically textureless and randomly stacked in a bin, which poses a significant challenge to 6D pose estimation. Existing solutions are typically learning-based methods, which require object-specific training. Their efficiency of practical deployment for novel workpieces is highly limited by data collection and model retraining. Zero-shot 6D pose estimation is a potential approach to address the issue of deployment efficiency. Nevertheless, existing zero-shot 6D pose estimation methods are designed to leverage feature matching to establish point-to-point correspondences for pose estimation, which is less effective for workpieces with textureless appearances and ambiguous local regions. In this paper, we propose ZeroBP, a zero-shot pose estimation framework designed specifically for the bin-picking task. ZeroBP learns Position-Aware Correspondence (PAC) between the scene instance and its CAD model, leveraging both local features and global positions to resolve the mismatch issue caused by ambiguous regions with similar shapes and appearances. Extensive experiments on the ROBI dataset demonstrate that ZeroBP outperforms state-of-the-art zero-shot pose estimation methods, achieving an improvement of 9.1% in average recall of correct poses.
Global-Local MAV Detection under Challenging Conditions based on Appearance and Motion
Dec 18, 2023



Visual detection of micro aerial vehicles (MAVs) has received increasing research attention in recent years due to its importance in many applications. However, the existing approaches based on either appearance or motion features of MAVs still face challenges when the background is complex, the MAV target is small, or the computation resource is limited. In this paper, we propose a global-local MAV detector that can fuse both motion and appearance features for MAV detection under challenging conditions. This detector first searches MAV target using a global detector and then switches to a local detector which works in an adaptive search region to enhance accuracy and efficiency. Additionally, a detector switcher is applied to coordinate the global and local detectors. A new dataset is created to train and verify the effectiveness of the proposed detector. This dataset contains more challenging scenarios that can occur in practice. Extensive experiments on three challenging datasets show that the proposed detector outperforms the state-of-the-art ones in terms of detection accuracy and computational efficiency. In particular, this detector can run with near real-time frame rate on NVIDIA Jetson NX Xavier, which demonstrates the usefulness of our approach for real-world applications. The dataset is available at https://github.com/WestlakeIntelligentRobotics/GLAD. In addition, A video summarizing this work is available at https://youtu.be/Tv473mAzHbU.
MIAD: A Maintenance Inspection Dataset for Unsupervised Anomaly Detection
Nov 28, 2022



Visual anomaly detection plays a crucial role in not only manufacturing inspection to find defects of products during manufacturing processes, but also maintenance inspection to keep equipment in optimum working condition particularly outdoors. Due to the scarcity of the defective samples, unsupervised anomaly detection has attracted great attention in recent years. However, existing datasets for unsupervised anomaly detection are biased towards manufacturing inspection, not considering maintenance inspection which is usually conducted under outdoor uncontrolled environment such as varying camera viewpoints, messy background and degradation of object surface after long-term working. We focus on outdoor maintenance inspection and contribute a comprehensive Maintenance Inspection Anomaly Detection (MIAD) dataset which contains more than 100K high-resolution color images in various outdoor industrial scenarios. This dataset is generated by a 3D graphics software and covers both surface and logical anomalies with pixel-precise ground truth. Extensive evaluations of representative algorithms for unsupervised anomaly detection are conducted, and we expect MIAD and corresponding experimental results can inspire research community in outdoor unsupervised anomaly detection tasks. Worthwhile and related future work can be spawned from our new dataset.
Uni6Dv2: Noise Elimination for 6D Pose Estimation
Aug 15, 2022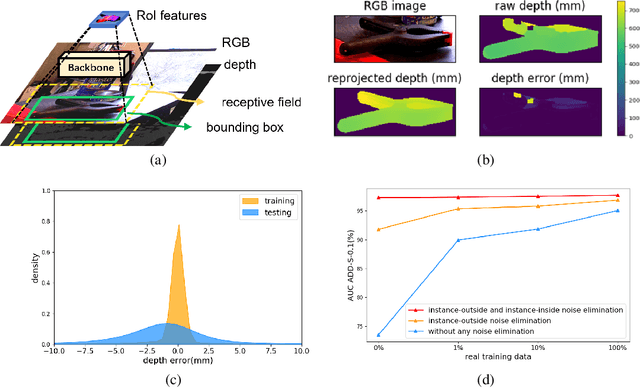
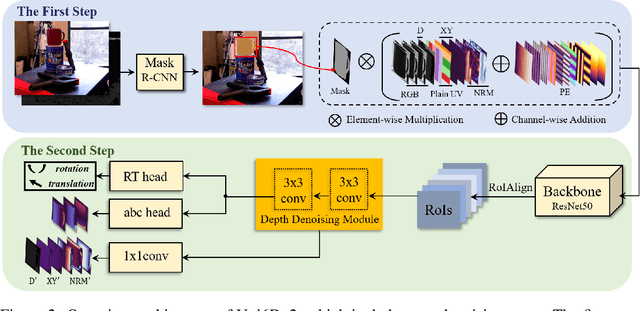
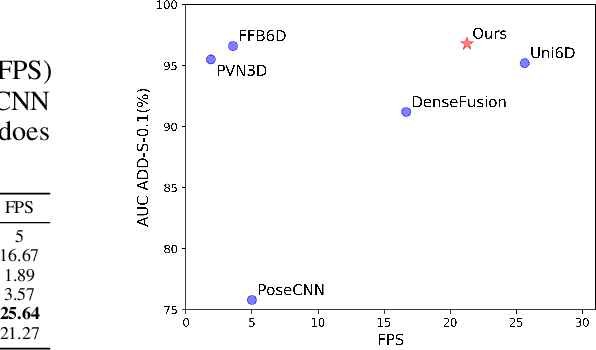
Few prior 6D pose estimation methods use a backbone network to extract features from RGB and depth images, and Uni6D is the pioneer to do so. We find that primary causes of the performance limitation in Uni6D are Instance-Outside and Instance-Inside noise. Uni6D inevitably introduces Instance-Outside noise from background pixels in the receptive field due to its inherently straightforward pipeline design and ignores the Instance-Inside noise in the input depth data. In this work, we propose a two-step denoising method to handle aforementioned noise in Uni6D. In the first step, an instance segmentation network is used to crop and mask the instance to remove noise from non-instance regions. In the second step, a lightweight depth denoising module is proposed to calibrate the depth feature before feeding it into the pose regression network. Extensive experiments show that our method called Uni6Dv2 is able to eliminate the noise effectively and robustly, outperforming Uni6D without sacrificing too much inference efficiency. It also reduces the need for annotated real data that requires costly labeling.
Benchmarking Unsupervised Anomaly Detection and Localization
May 30, 2022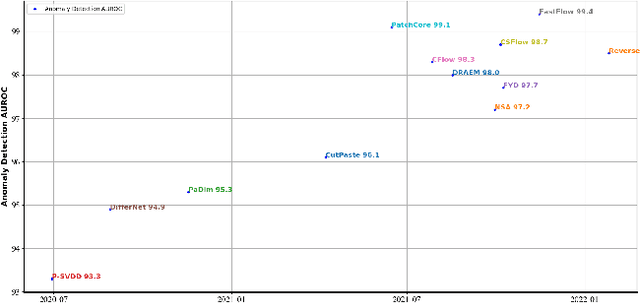
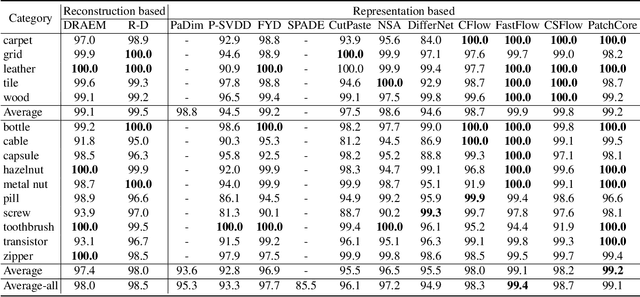
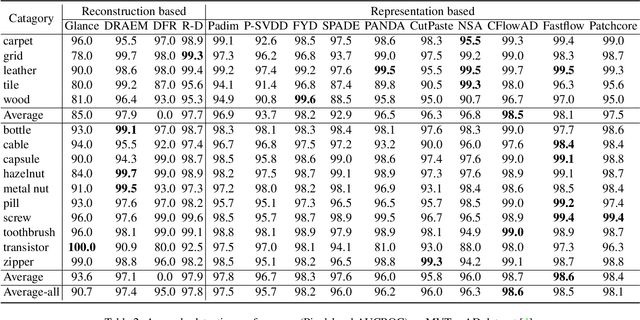
Unsupervised anomaly detection and localization, as of one the most practical and challenging problems in computer vision, has received great attention in recent years. From the time the MVTec AD dataset was proposed to the present, new research methods that are constantly being proposed push its precision to saturation. It is the time to conduct a comprehensive comparison of existing methods to inspire further research. This paper extensively compares 13 papers in terms of the performance in unsupervised anomaly detection and localization tasks, and adds a comparison of inference efficiency previously ignored by the community. Meanwhile, analysis of the MVTec AD dataset are also given, especially the label ambiguity that affects the model fails to achieve full marks. Moreover, considering the proposal of the new MVTec 3D-AD dataset, this paper also conducts experiments using the existing state-of-the-art 2D methods on this new dataset, and reports the corresponding results with analysis.
Uni6D: A Unified CNN Framework without Projection Breakdown for 6D Pose Estimation
Apr 05, 2022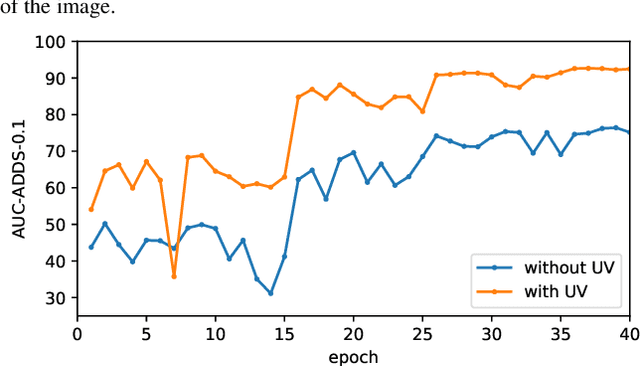
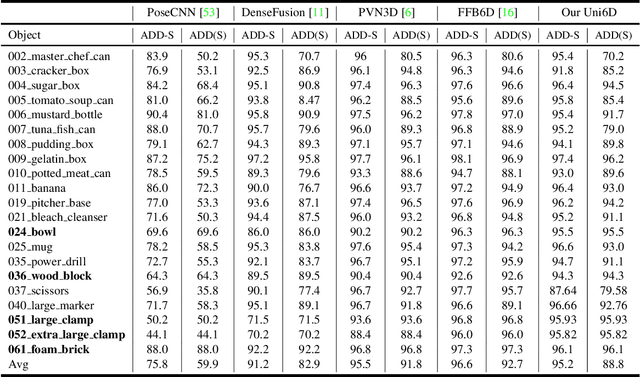
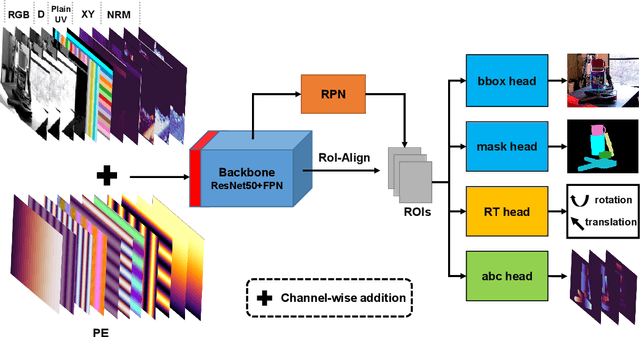
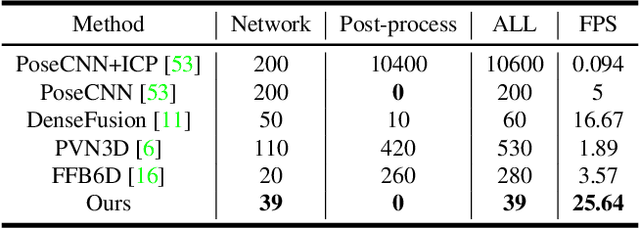
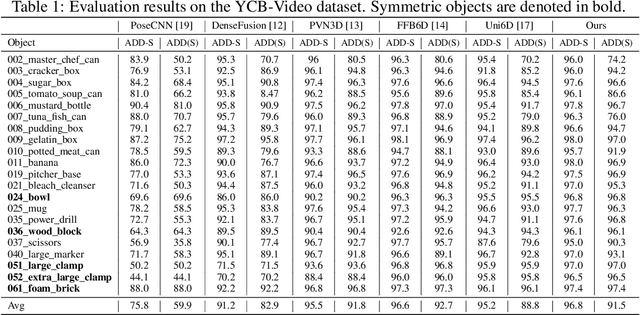
As RGB-D sensors become more affordable, using RGB-D images to obtain high-accuracy 6D pose estimation results becomes a better option. State-of-the-art approaches typically use different backbones to extract features for RGB and depth images. They use a 2D CNN for RGB images and a per-pixel point cloud network for depth data, as well as a fusion network for feature fusion. We find that the essential reason for using two independent backbones is the "projection breakdown" problem. In the depth image plane, the projected 3D structure of the physical world is preserved by the 1D depth value and its built-in 2D pixel coordinate (UV). Any spatial transformation that modifies UV, such as resize, flip, crop, or pooling operations in the CNN pipeline, breaks the binding between the pixel value and UV coordinate. As a consequence, the 3D structure is no longer preserved by a modified depth image or feature. To address this issue, we propose a simple yet effective method denoted as Uni6D that explicitly takes the extra UV data along with RGB-D images as input. Our method has a Unified CNN framework for 6D pose estimation with a single CNN backbone. In particular, the architecture of our method is based on Mask R-CNN with two extra heads, one named RT head for directly predicting 6D pose and the other named abc head for guiding the network to map the visible points to their coordinates in the 3D model as an auxiliary module. This end-to-end approach balances simplicity and accuracy, achieving comparable accuracy with state of the arts and 7.2x faster inference speed on the YCB-Video dataset.
FastFlow: Unsupervised Anomaly Detection and Localization via 2D Normalizing Flows
Nov 16, 2021
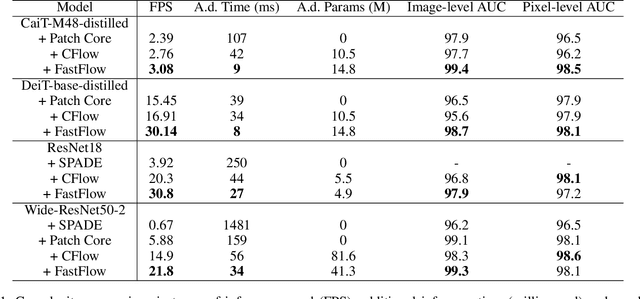
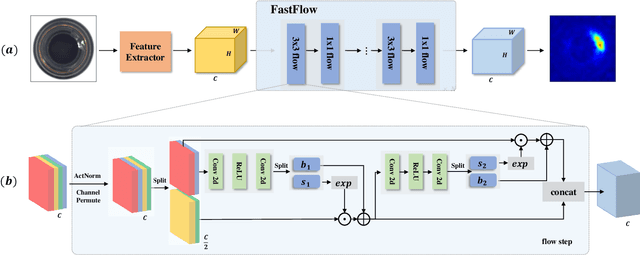

Unsupervised anomaly detection and localization is crucial to the practical application when collecting and labeling sufficient anomaly data is infeasible. Most existing representation-based approaches extract normal image features with a deep convolutional neural network and characterize the corresponding distribution through non-parametric distribution estimation methods. The anomaly score is calculated by measuring the distance between the feature of the test image and the estimated distribution. However, current methods can not effectively map image features to a tractable base distribution and ignore the relationship between local and global features which are important to identify anomalies. To this end, we propose FastFlow implemented with 2D normalizing flows and use it as the probability distribution estimator. Our FastFlow can be used as a plug-in module with arbitrary deep feature extractors such as ResNet and vision transformer for unsupervised anomaly detection and localization. In training phase, FastFlow learns to transform the input visual feature into a tractable distribution and obtains the likelihood to recognize anomalies in inference phase. Extensive experimental results on the MVTec AD dataset show that FastFlow surpasses previous state-of-the-art methods in terms of accuracy and inference efficiency with various backbone networks. Our approach achieves 99.4% AUC in anomaly detection with high inference efficiency.