 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Model Predictive Controllers with Real-Time Attention for Real-World Navigation
Sep 24, 2022


Despite decades of research, existing navigation systems still face real-world challenges when deployed in the wild, e.g., in cluttered home environments or in human-occupied public spaces. To address this, we present a new class of implicit control policies combining the benefits of imitation learning with the robust handling of system constraints from Model Predictive Control (MPC). Our approach, called Performer-MPC, uses a learned cost function parameterized by vision context embeddings provided by Performers -- a low-rank implicit-attention Transformer. We jointly train the cost function and construct the controller relying on it, effectively solving end-to-end the corresponding bi-level optimization problem. We show that the resulting policy improves standard MPC performance by leveraging a few expert demonstrations of the desired navigation behavior in different challenging real-world scenarios. Compared with a standard MPC policy, Performer-MPC achieves >40% better goal reached in cluttered environments and >65% better on social metrics when navigating around humans.
Implicit Two-Tower Policies
Aug 02, 2022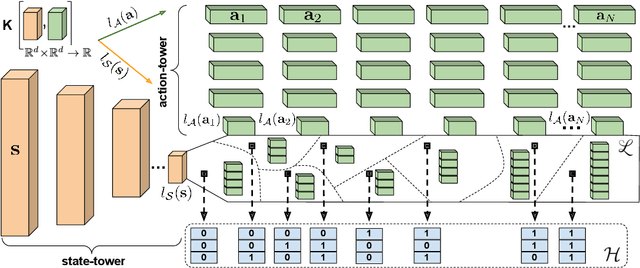
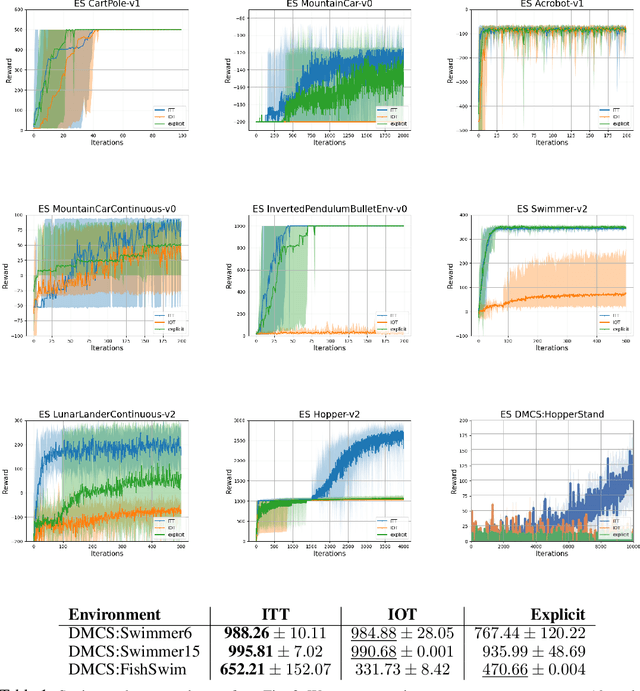
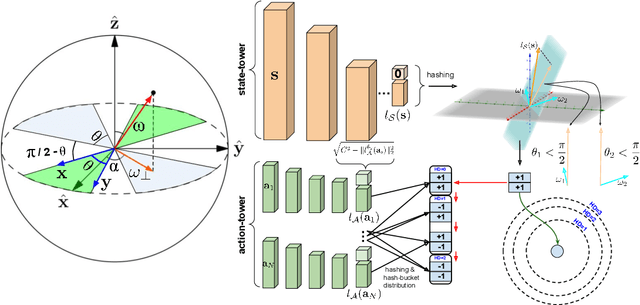
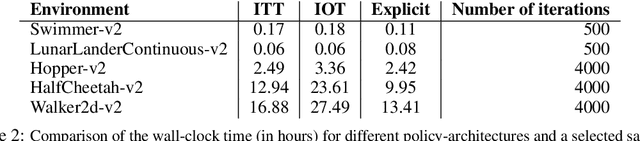
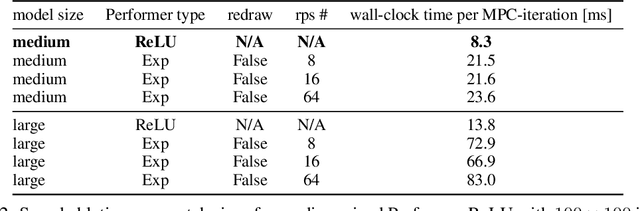
We present a new class of structured reinforcement learning policy-architectures, Implicit Two-Tower (ITT) policies, where the actions are chosen based on the attention scores of their learnable latent representations with those of the input states. By explicitly disentangling action from state processing in the policy stack, we achieve two main goals: substantial computational gains and better performance. Our architectures are compatible with both: discrete and continuous action spaces. By conducting tests on 15 environments from OpenAI Gym and DeepMind Control Suite, we show that ITT-architectures are particularly suited for blackbox/evolutionary optimization and the corresponding policy training algorithms outperform their vanilla unstructured implicit counterparts as well as commonly used explicit policies. We complement our analysis by showing how techniques such as hashing and lazy tower updates, critically relying on the two-tower structure of ITTs, can be applied to obtain additional computational improvements.
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
Apr 01, 2022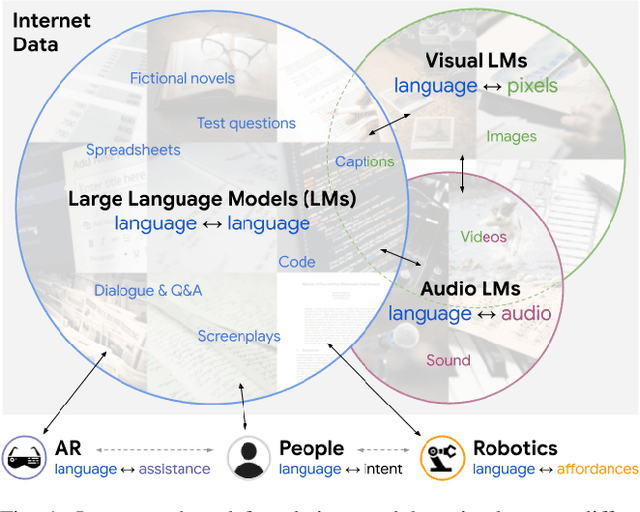
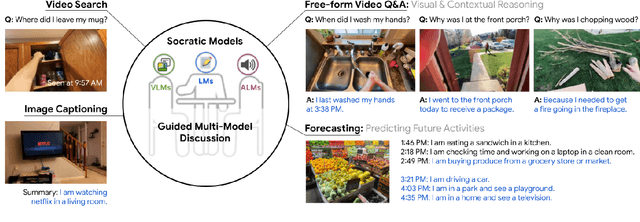
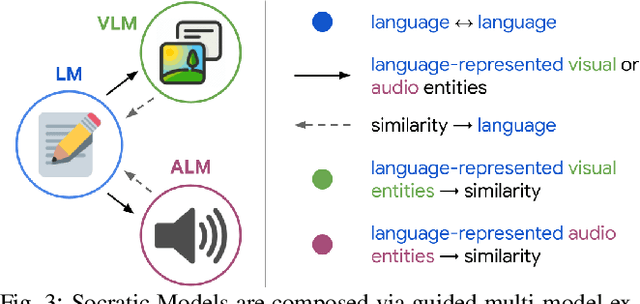
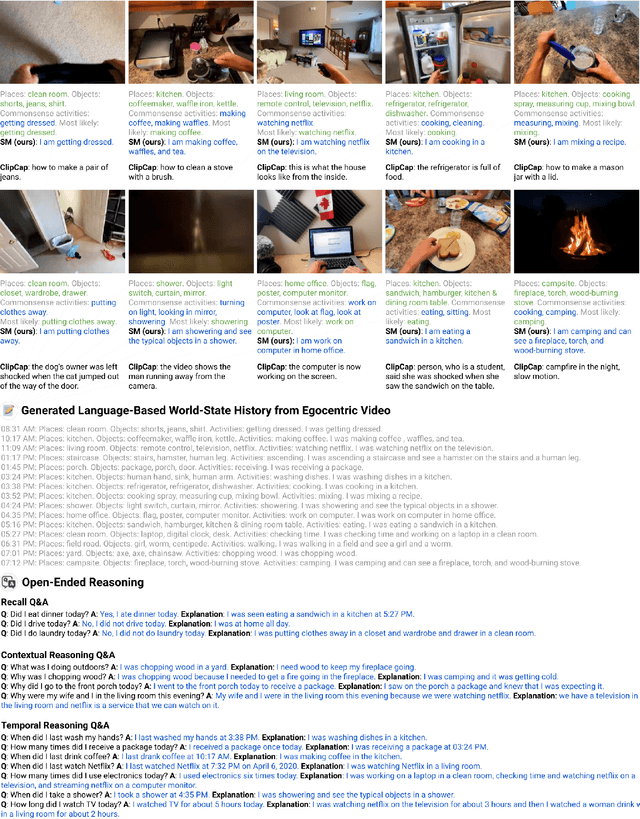
Large foundation models can exhibit unique capabilities depending on the domain of data they are trained on. While these domains are generic, they may only barely overlap. For example, visual-language models (VLMs) are trained on Internet-scale image captions, but large language models (LMs) are further trained on Internet-scale text with no images (e.g. from spreadsheets, to SAT questions). As a result, these models store different forms of commonsense knowledge across different domains. In this work, we show that this model diversity is symbiotic, and can be leveraged to build AI systems with structured Socratic dialogue -- in which new multimodal tasks are formulated as a guided language-based exchange between different pre-existing foundation models, without additional finetuning. In the context of egocentric perception, we present a case study of Socratic Models (SMs) that can provide meaningful results for complex tasks such as generating free-form answers to contextual questions about egocentric video, by formulating video Q&A as short story Q&A, i.e. summarizing the video into a short story, then answering questions about it. Additionally, SMs can generate captions for Internet images, and are competitive with state-of-the-art on zero-shot video-to-text retrieval with 42.8 R@1 on MSR-VTT 1k-A. SMs demonstrate how to compose foundation models zero-shot to capture new multimodal functionalities, without domain-specific data collection. Prototypes are available at socraticmodels.github.io.
Multiscale Sensor Fusion and Continuous Control with Neural CDEs
Mar 16, 2022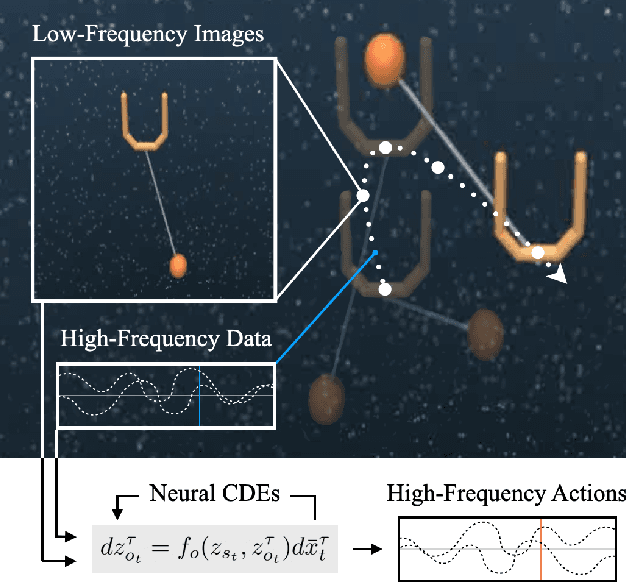
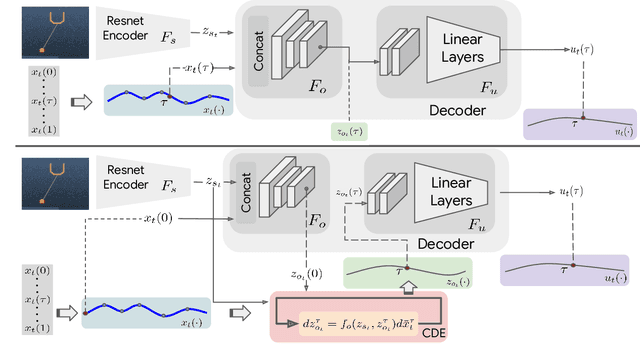
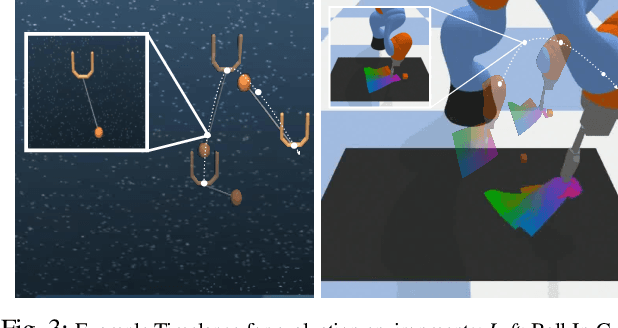
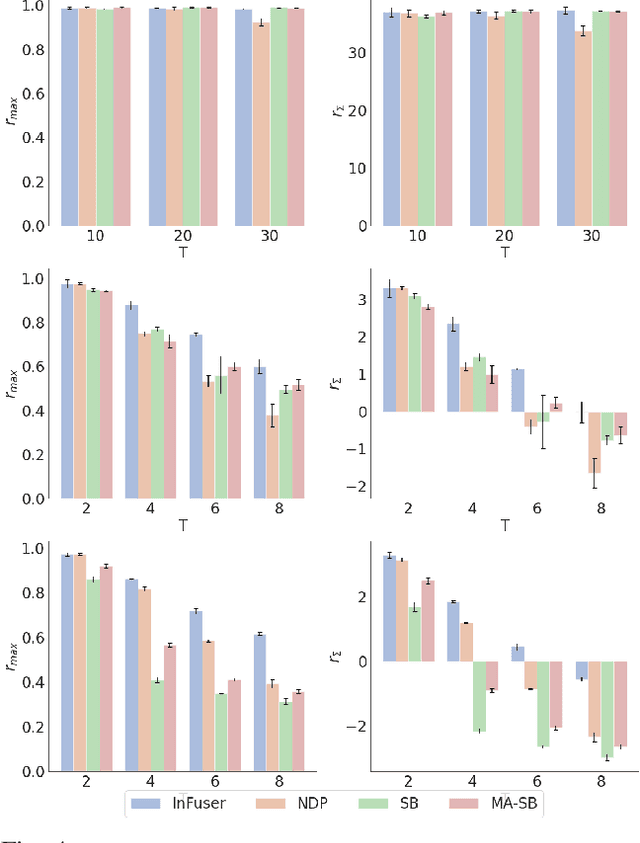
Though robot learning is often formulated in terms of discrete-time Markov decision processes (MDPs), physical robots require near-continuous multiscale feedback control. Machines operate on multiple asynchronous sensing modalities, each with different frequencies, e.g., video frames at 30Hz, proprioceptive state at 100Hz, force-torque data at 500Hz, etc. While the classic approach is to batch observations into fixed-time windows then pass them through feed-forward encoders (e.g., with deep networks), we show that there exists a more elegant approach -- one that treats policy learning as modeling latent state dynamics in continuous-time. Specifically, we present 'InFuser', a unified architecture that trains continuous time-policies with Neural Controlled Differential Equations (CDEs). InFuser evolves a single latent state representation over time by (In)tegrating and (Fus)ing multi-sensory observations (arriving at different frequencies), and inferring actions in continuous-time. This enables policies that can react to multi-frequency multi sensory feedback for truly end-to-end visuomotor control, without discrete-time assumptions. Behavior cloning experiments demonstrate that InFuser learns robust policies for dynamic tasks (e.g., swinging a ball into a cup) notably outperforming several baselines in settings where observations from one sensing modality can arrive at much sparser intervals than others.
Hybrid Random Features
Oct 13, 2021
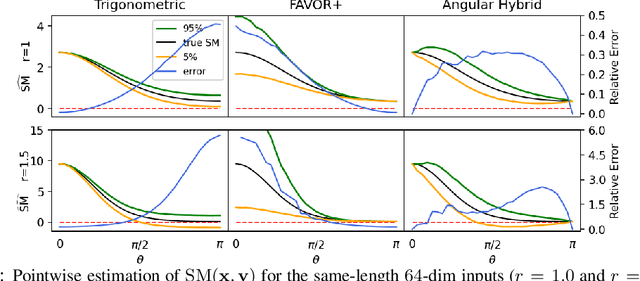
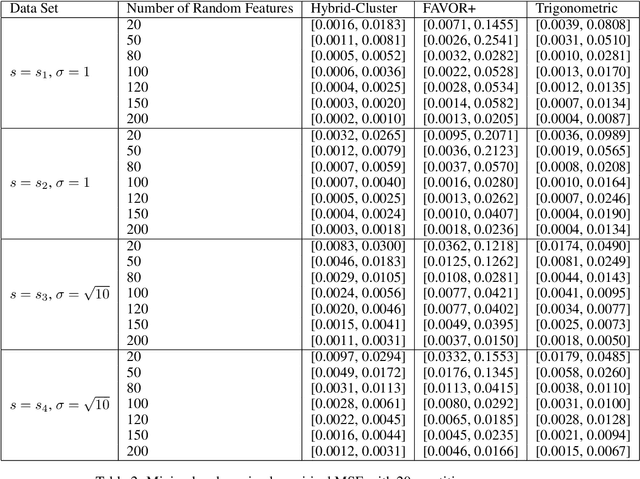
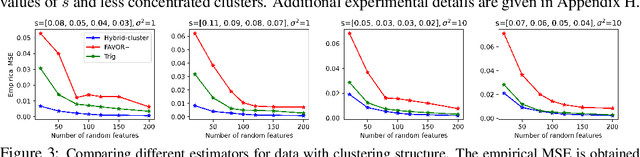
We propose a new class of random feature methods for linearizing softmax and Gaussian kernels called hybrid random features (HRFs) that automatically adapt the quality of kernel estimation to provide most accurate approximation in the defined regions of interest. Special instantiations of HRFs lead to well-known methods such as trigonometric (Rahimi and Recht, 2007) or (recently introduced in the context of linear-attention Transformers) positive random features (Choromanski et al., 2021). By generalizing Bochner's Theorem for softmax/Gaussian kernels and leveraging random features for compositional kernels, the HRF-mechanism provides strong theoretical guarantees - unbiased approximation and strictly smaller worst-case relative errors than its counterparts. We conduct exhaustive empirical evaluation of HRF ranging from pointwise kernel estimation experiments, through tests on data admitting clustering structure to benchmarking implicit-attention Transformers (also for downstream Robotics applications), demonstrating its quality in a wide spectrum of machine learning problems.
Trajectory Optimization with Optimization-Based Dynamics
Sep 10, 2021



We present a framework for bi-level trajectory optimization in which a system's dynamics are encoded as the solution to a constrained optimization problem and smooth gradients of this lower-level problem are passed to an upper-level trajectory optimizer. This optimization-based dynamics representation enables constraint handling, additional variables, and non-smooth forces to be abstracted away from the upper-level optimizer, and allows classical unconstrained optimizers to synthesize trajectories for more complex systems. We provide a path-following method for efficient evaluation of constrained dynamics and utilize the implicit-function theorem to compute smooth gradients of this representation. We demonstrate the framework by modeling systems from locomotion, aerospace, and manipulation domains including: acrobot with joint limits, cart-pole subject to Coulomb friction, Raibert hopper, rocket landing with thrust limits, and planar-push task with optimization-based dynamics and then optimize trajectories using iterative LQR.
Learning to Rearrange Deformable Cables, Fabrics, and Bags with Goal-Conditioned Transporter Networks
Dec 18, 2020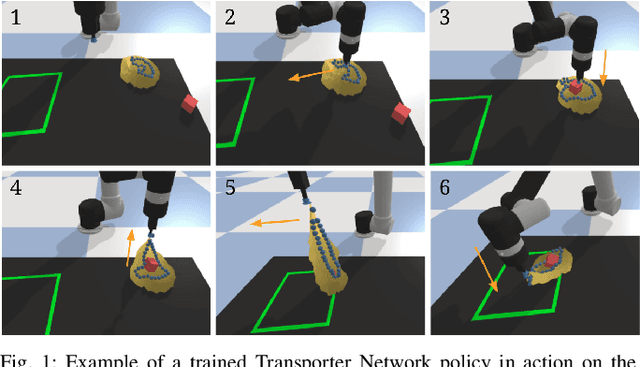
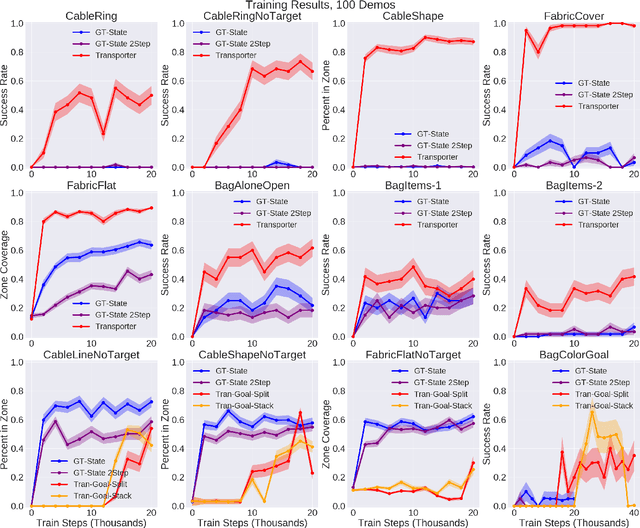
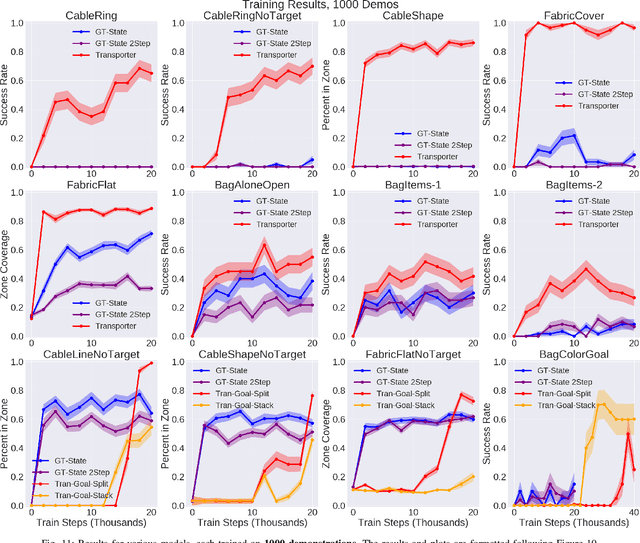
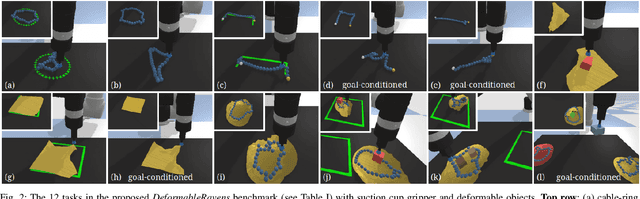
Rearranging and manipulating deformable objects such as cables, fabrics, and bags is a long-standing challenge in robotic manipulation. The complex dynamics and high-dimensional configuration spaces of deformables, compared to rigid objects, make manipulation difficult not only for multi-step planning, but even for goal specification. Goals cannot be as easily specified as rigid object poses, and may involve complex relative spatial relations such as "place the item inside the bag". In this work, we develop a suite of simulated benchmarks with 1D, 2D, and 3D deformable structures, including tasks that involve image-based goal-conditioning and multi-step deformable manipulation. We propose embedding goal-conditioning into Transporter Networks, a recently proposed model architecture for learning robotic manipulation that rearranges deep features to infer displacements that can represent pick and place actions. We demonstrate that goal-conditioned Transporter Networks enable agents to manipulate deformable structures into flexibly specified configurations without test-time visual anchors for target locations. We also significantly extend prior results using Transporter Networks for manipulating deformable objects by testing on tasks with 2D and 3D deformables. Supplementary material is available at https://berkeleyautomation.github.io/bags/.
Safely Learning Dynamical Systems from Short Trajectories
Nov 24, 2020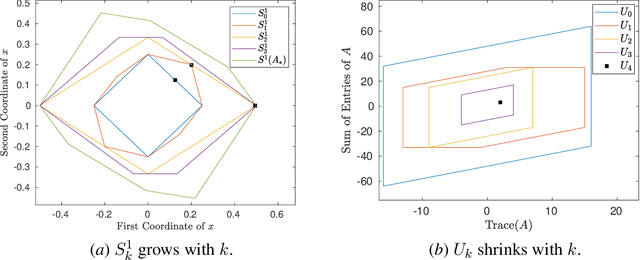
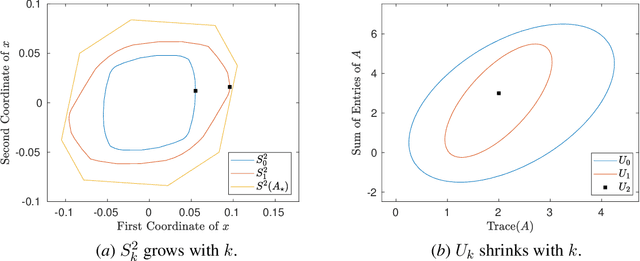
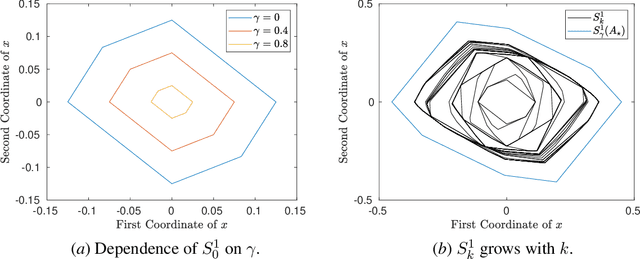
A fundamental challenge in learning to control an unknown dynamical system is to reduce model uncertainty by making measurements while maintaining safety. In this work, we formulate a mathematical definition of what it means to safely learn a dynamical system by sequentially deciding where to initialize the next trajectory. In our framework, the state of the system is required to stay within a given safety region under the (possibly repeated) action of all dynamical systems that are consistent with the information gathered so far. For our first two results, we consider the setting of safely learning linear dynamics. We present a linear programming-based algorithm that either safely recovers the true dynamics from trajectories of length one, or certifies that safe learning is impossible. We also give an efficient semidefinite representation of the set of initial conditions whose resulting trajectories of length two are guaranteed to stay in the safety region. For our final result, we study the problem of safely learning a nonlinear dynamical system. We give a second-order cone programming based representation of the set of initial conditions that are guaranteed to remain in the safety region after one application of the system dynamics.
Transporter Networks: Rearranging the Visual World for Robotic Manipulation
Oct 27, 2020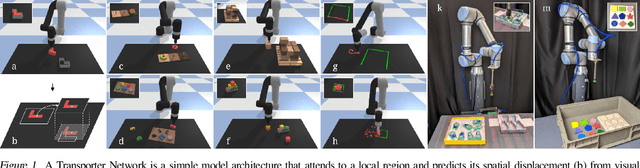
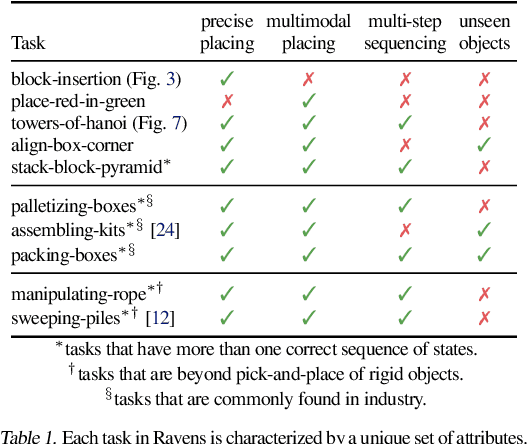
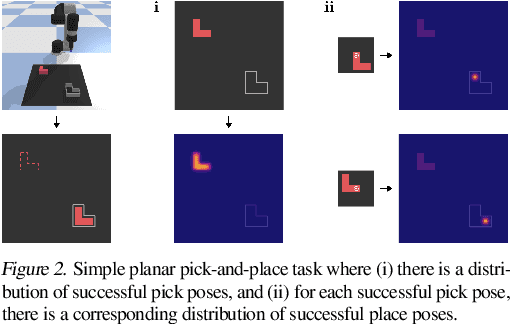
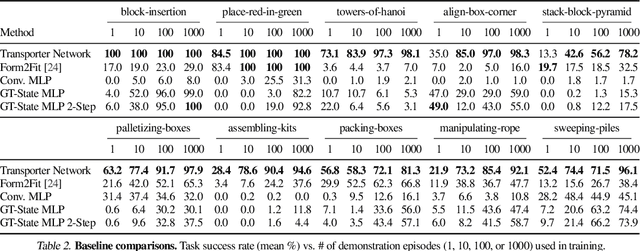
Robotic manipulation can be formulated as inducing a sequence of spatial displacements: where the space being moved can encompass an object, part of an object, or end effector. In this work, we propose the Transporter Network, a simple model architecture that rearranges deep features to infer spatial displacements from visual input - which can parameterize robot actions. It makes no assumptions of objectness (e.g. canonical poses, models, or keypoints), it exploits spatial symmetries, and is orders of magnitude more sample efficient than our benchmarked alternatives in learning vision-based manipulation tasks: from stacking a pyramid of blocks, to assembling kits with unseen objects; from manipulating deformable ropes, to pushing piles of small objects with closed-loop feedback. Our method can represent complex multi-modal policy distributions and generalizes to multi-step sequential tasks, as well as 6DoF pick-and-place. Experiments on 10 simulated tasks show that it learns faster and generalizes better than a variety of end-to-end baselines, including policies that use ground-truth object poses. We validate our methods with hardware in the real world. Experiment videos and code will be made available at https://transporternets.github.io
Piecewise-Linear Motion Planning amidst Static, Moving, or Morphing Obstacles
Oct 16, 2020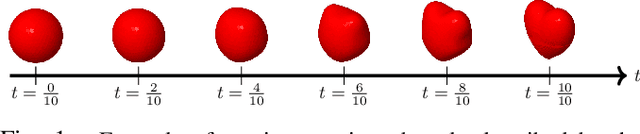
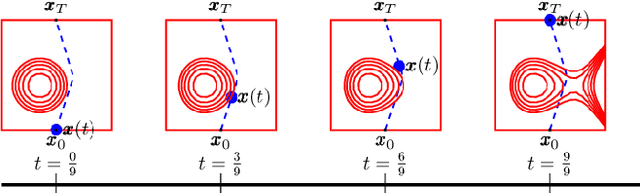
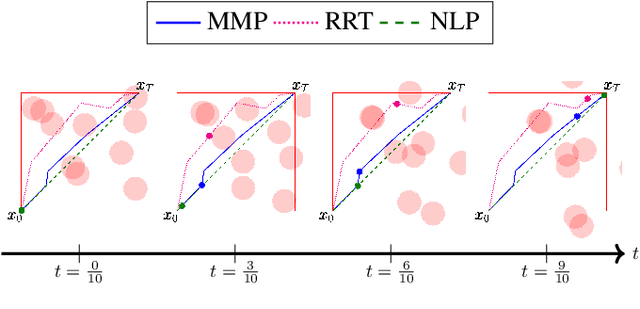
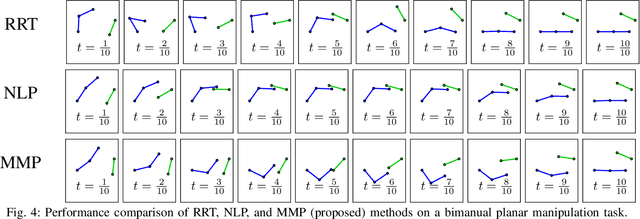
We propose a novel method for planning shortest length piecewise-linear motions through complex environments punctured with static, moving, or even morphing obstacles. Using a moment optimization approach, we formulate a hierarchy of semidefinite programs that yield increasingly refined lower bounds converging monotonically to the optimal path length. For computational tractability, our global moment optimization approach motivates an iterative motion planner that outperforms competing sampling-based and nonlinear optimization baselines. Our method natively handles continuous time constraints without any need for time discretization, and has the potential to scale better with dimensions compared to popular sampling-based methods.