 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDaunce: Data Attribution through Uncertainty Estimation
May 29, 2025Training data attribution (TDA) methods aim to identify which training examples influence a model's predictions on specific test data most. By quantifying these influences, TDA supports critical applications such as data debugging, curation, and valuation. Gradient-based TDA methods rely on gradients and second-order information, limiting their applicability at scale. While recent random projection-based methods improve scalability, they often suffer from degraded attribution accuracy. Motivated by connections between uncertainty and influence functions, we introduce Daunce - a simple yet effective data attribution approach through uncertainty estimation. Our method operates by fine-tuning a collection of perturbed models and computing the covariance of per-example losses across these models as the attribution score. Daunce is scalable to large language models (LLMs) and achieves more accurate attribution compared to existing TDA methods. We validate Daunce on tasks ranging from vision tasks to LLM fine-tuning, and further demonstrate its compatibility with black-box model access. Applied to OpenAI's GPT models, our method achieves, to our knowledge, the first instance of data attribution on proprietary LLMs.
Almost Linear Convergence under Minimal Score Assumptions: Quantized Transition Diffusion
May 28, 2025Continuous diffusion models have demonstrated remarkable performance in data generation across various domains, yet their efficiency remains constrained by two critical limitations: (1) the local adjacency structure of the forward Markov process, which restricts long-range transitions in the data space, and (2) inherent biases introduced during the simulation of time-inhomogeneous reverse denoising processes. To address these challenges, we propose Quantized Transition Diffusion (QTD), a novel approach that integrates data quantization with discrete diffusion dynamics. Our method first transforms the continuous data distribution $p_*$ into a discrete one $q_*$ via histogram approximation and binary encoding, enabling efficient representation in a structured discrete latent space. We then design a continuous-time Markov chain (CTMC) with Hamming distance-based transitions as the forward process, which inherently supports long-range movements in the original data space. For reverse-time sampling, we introduce a \textit{truncated uniformization} technique to simulate the reverse CTMC, which can provably provide unbiased generation from $q_*$ under minimal score assumptions. Through a novel KL dynamic analysis of the reverse CTMC, we prove that QTD can generate samples with $O(d\ln^2(d/\epsilon))$ score evaluations in expectation to approximate the $d$--dimensional target distribution $p_*$ within an $\epsilon$ error tolerance. Our method not only establishes state-of-the-art inference efficiency but also advances the theoretical foundations of diffusion-based generative modeling by unifying discrete and continuous diffusion paradigms.
RoHyDR: Robust Hybrid Diffusion Recovery for Incomplete Multimodal Emotion Recognition
May 23, 2025Multimodal emotion recognition analyzes emotions by combining data from multiple sources. However, real-world noise or sensor failures often cause missing or corrupted data, creating the Incomplete Multimodal Emotion Recognition (IMER) challenge. In this paper, we propose Robust Hybrid Diffusion Recovery (RoHyDR), a novel framework that performs missing-modality recovery at unimodal, multimodal, feature, and semantic levels. For unimodal representation recovery of missing modalities, RoHyDR exploits a diffusion-based generator to generate distribution-consistent and semantically aligned representations from Gaussian noise, using available modalities as conditioning. For multimodal fusion recovery, we introduce adversarial learning to produce a realistic fused multimodal representation and recover missing semantic content. We further propose a multi-stage optimization strategy that enhances training stability and efficiency. In contrast to previous work, the hybrid diffusion and adversarial learning-based recovery mechanism in RoHyDR allows recovery of missing information in both unimodal representation and multimodal fusion, at both feature and semantic levels, effectively mitigating performance degradation caused by suboptimal optimization. Comprehensive experiments conducted on two widely used multimodal emotion recognition benchmarks demonstrate that our proposed method outperforms state-of-the-art IMER methods, achieving robust recognition performance under various missing-modality scenarios. Our code will be made publicly available upon acceptance.
ELABORATION: A Comprehensive Benchmark on Human-LLM Competitive Programming
May 22, 2025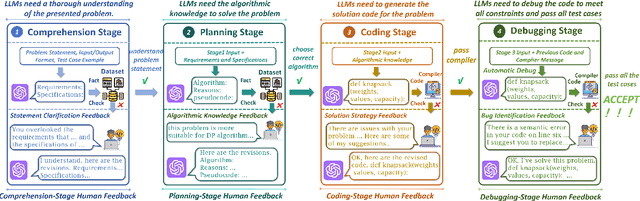
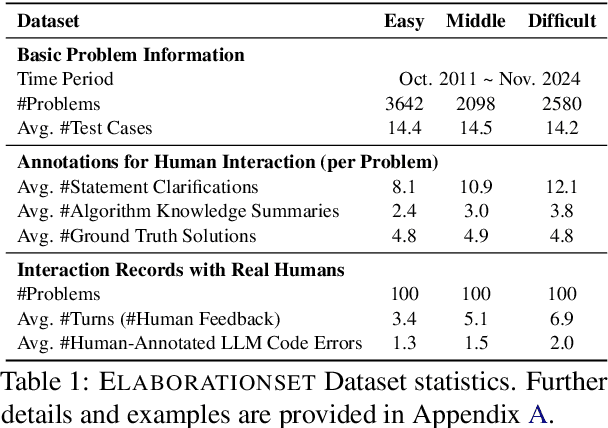

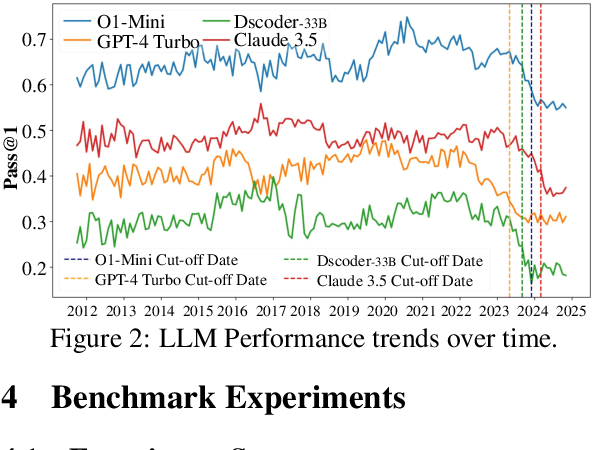
While recent research increasingly emphasizes the value of human-LLM collaboration in competitive programming and proposes numerous empirical methods, a comprehensive understanding remains elusive due to the fragmented nature of existing studies and their use of diverse, application-specific human feedback. Thus, our work serves a three-fold purpose: First, we present the first taxonomy of human feedback consolidating the entire programming process, which promotes fine-grained evaluation. Second, we introduce ELABORATIONSET, a novel programming dataset specifically designed for human-LLM collaboration, meticulously annotated to enable large-scale simulated human feedback and facilitate costeffective real human interaction studies. Third, we introduce ELABORATION, a novel benchmark to facilitate a thorough assessment of human-LLM competitive programming. With ELABORATION, we pinpoint strengthes and weaknesses of existing methods, thereby setting the foundation for future improvement. Our code and dataset are available at https://github.com/SCUNLP/ELABORATION
MentalMAC: Enhancing Large Language Models for Detecting Mental Manipulation via Multi-Task Anti-Curriculum Distillation
May 21, 2025Mental manipulation is a subtle yet pervasive form of psychological abuse that poses serious threats to mental health. Its covert nature and the complexity of manipulation strategies make it challenging to detect, even for state-of-the-art large language models (LLMs). This concealment also hinders the manual collection of large-scale, high-quality annotations essential for training effective models. Although recent efforts have sought to improve LLM's performance on this task, progress remains limited due to the scarcity of real-world annotated datasets. To address these challenges, we propose MentalMAC, a multi-task anti-curriculum distillation method that enhances LLMs' ability to detect mental manipulation in multi-turn dialogue. Our approach includes: (i) EvoSA, an unsupervised data expansion method based on evolutionary operations and speech act theory; (ii) teacher-model-generated multi-task supervision; and (iii) progressive knowledge distillation from complex to simpler tasks. We then constructed the ReaMent dataset with 5,000 real-world dialogue samples, using a MentalMAC-distilled model to assist human annotation. Vast experiments demonstrate that our method significantly narrows the gap between student and teacher models and outperforms competitive LLMs across key evaluation metrics. All code, datasets, and checkpoints will be released upon paper acceptance. Warning: This paper contains content that may be offensive to readers.
MergeBench: A Benchmark for Merging Domain-Specialized LLMs
May 16, 2025Model merging provides a scalable alternative to multi-task training by combining specialized finetuned models through parameter arithmetic, enabling efficient deployment without the need for joint training or access to all task data. While recent methods have shown promise, existing evaluations are limited in both model scale and task diversity, leaving open questions about their applicability to large, domain-specialized LLMs. To tackle the challenges, we introduce MergeBench, a comprehensive evaluation suite designed to assess model merging at scale. MergeBench builds on state-of-the-art open-source language models, including Llama and Gemma families at 2B to 9B scales, and covers five key domains: instruction following, mathematics, multilingual understanding, coding and safety. We standardize finetuning and evaluation protocols, and assess eight representative merging methods across multi-task performance, forgetting and runtime efficiency. Based on extensive experiments, we provide practical guidelines for algorithm selection and share insights showing that model merging tends to perform better on stronger base models, with techniques such as merging coefficient tuning and sparsification improving knowledge retention. However, several challenges remain, including the computational cost on large models, the gap for in-domain performance compared to multi-task models, and the underexplored role of model merging in standard LLM training pipelines. We hope MergeBench provides a foundation for future research to advance the understanding and practical application of model merging. We open source our code at \href{https://github.com/uiuctml/MergeBench}{https://github.com/uiuctml/MergeBench}.
Prioritizing Image-Related Tokens Enhances Vision-Language Pre-Training
May 13, 2025



In standard large vision-language models (LVLMs) pre-training, the model typically maximizes the joint probability of the caption conditioned on the image via next-token prediction (NTP); however, since only a small subset of caption tokens directly relates to the visual content, this naive NTP unintentionally fits the model to noise and increases the risk of hallucination. We present PRIOR, a simple vision-language pre-training approach that addresses this issue by prioritizing image-related tokens through differential weighting in the NTP loss, drawing from the importance sampling framework. PRIOR introduces a reference model-a text-only large language model (LLM) trained on the captions without image inputs, to weight each token based on its probability for LVLMs training. Intuitively, tokens that are directly related to the visual inputs are harder to predict without the image and thus receive lower probabilities from the text-only reference LLM. During training, we implement a token-specific re-weighting term based on the importance scores to adjust each token's loss. We implement PRIOR in two distinct settings: LVLMs with visual encoders and LVLMs without visual encoders. We observe 19% and 8% average relative improvement, respectively, on several vision-language benchmarks compared to NTP. In addition, PRIOR exhibits superior scaling properties, as demonstrated by significantly higher scaling coefficients, indicating greater potential for performance gains compared to NTP given increasing compute and data.
HuB: Learning Extreme Humanoid Balance
May 12, 2025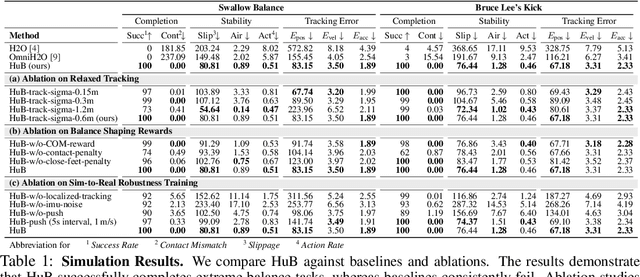
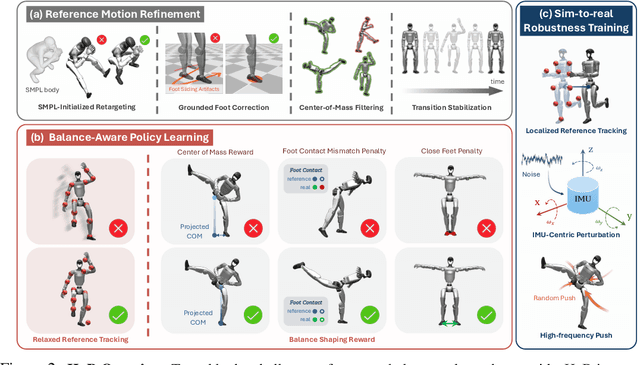
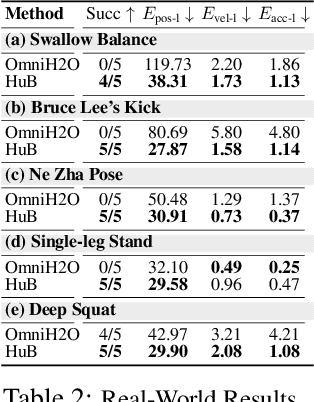
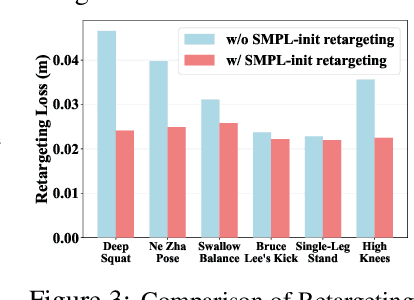
The human body demonstrates exceptional motor capabilities-such as standing steadily on one foot or performing a high kick with the leg raised over 1.5 meters-both requiring precise balance control. While recent research on humanoid control has leveraged reinforcement learning to track human motions for skill acquisition, applying this paradigm to balance-intensive tasks remains challenging. In this work, we identify three key obstacles: instability from reference motion errors, learning difficulties due to morphological mismatch, and the sim-to-real gap caused by sensor noise and unmodeled dynamics. To address these challenges, we propose HuB (Humanoid Balance), a unified framework that integrates reference motion refinement, balance-aware policy learning, and sim-to-real robustness training, with each component targeting a specific challenge. We validate our approach on the Unitree G1 humanoid robot across challenging quasi-static balance tasks, including extreme single-legged poses such as Swallow Balance and Bruce Lee's Kick. Our policy remains stable even under strong physical disturbances-such as a forceful soccer strike-while baseline methods consistently fail to complete these tasks. Project website: https://hub-robot.github.io
DeepSORT-Driven Visual Tracking Approach for Gesture Recognition in Interactive Systems
May 11, 2025Based on the DeepSORT algorithm, this study explores the application of visual tracking technology in intelligent human-computer interaction, especially in the field of gesture recognition and tracking. With the rapid development of artificial intelligence and deep learning technology, visual-based interaction has gradually replaced traditional input devices and become an important way for intelligent systems to interact with users. The DeepSORT algorithm can achieve accurate target tracking in dynamic environments by combining Kalman filters and deep learning feature extraction methods. It is especially suitable for complex scenes with multi-target tracking and fast movements. This study experimentally verifies the superior performance of DeepSORT in gesture recognition and tracking. It can accurately capture and track the user's gesture trajectory and is superior to traditional tracking methods in terms of real-time and accuracy. In addition, this study also combines gesture recognition experiments to evaluate the recognition ability and feedback response of the DeepSORT algorithm under different gestures (such as sliding, clicking, and zooming). The experimental results show that DeepSORT can not only effectively deal with target occlusion and motion blur but also can stably track in a multi-target environment, achieving a smooth user interaction experience. Finally, this paper looks forward to the future development direction of intelligent human-computer interaction systems based on visual tracking and proposes future research focuses such as algorithm optimization, data fusion, and multimodal interaction in order to promote a more intelligent and personalized interactive experience. Keywords-DeepSORT, visual tracking, gesture recognition, human-computer interaction
Optimizing Chain-of-Thought Reasoners via Gradient Variance Minimization in Rejection Sampling and RL
May 05, 2025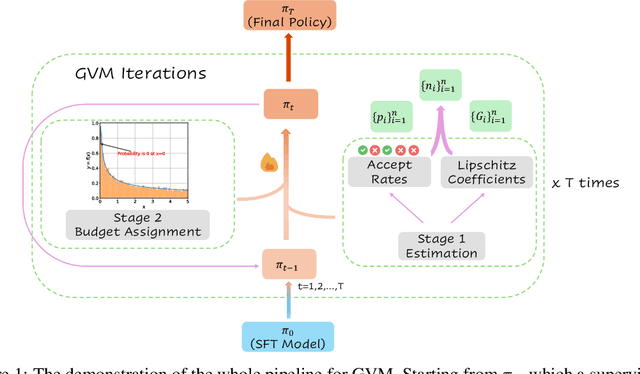
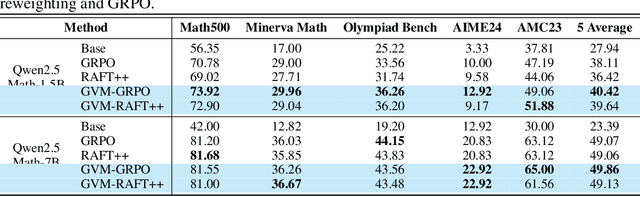
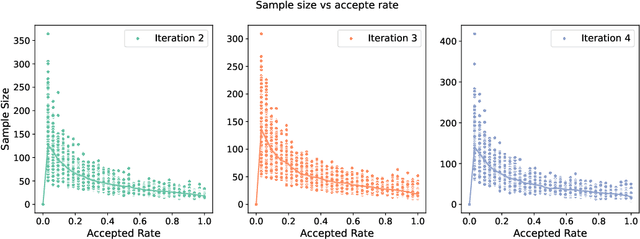
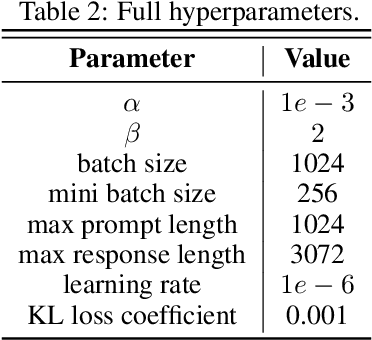
Chain-of-thought (CoT) reasoning in large language models (LLMs) can be formalized as a latent variable problem, where the model needs to generate intermediate reasoning steps. While prior approaches such as iterative reward-ranked fine-tuning (RAFT) have relied on such formulations, they typically apply uniform inference budgets across prompts, which fails to account for variability in difficulty and convergence behavior. This work identifies the main bottleneck in CoT training as inefficient stochastic gradient estimation due to static sampling strategies. We propose GVM-RAFT, a prompt-specific Dynamic Sample Allocation Strategy designed to minimize stochastic gradient variance under a computational budget constraint. The method dynamically allocates computational resources by monitoring prompt acceptance rates and stochastic gradient norms, ensuring that the resulting gradient variance is minimized. Our theoretical analysis shows that the proposed dynamic sampling strategy leads to accelerated convergence guarantees under suitable conditions. Experiments on mathematical reasoning show that GVM-RAFT achieves a 2-4x speedup and considerable accuracy improvements over vanilla RAFT. The proposed dynamic sampling strategy is general and can be incorporated into other reinforcement learning algorithms, such as GRPO, leading to similar improvements in convergence and test accuracy. Our code is available at https://github.com/RLHFlow/GVM.