 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOME: Learning Human-Object Manipulation with Action-Conditioned Egocentric World Model
Mar 28, 2026Learning human-object manipulation presents significant challenges due to its fine-grained and contact-rich nature of the motions involved. Traditional physics-based animation requires extensive modeling and manual setup, and more importantly, it neither generalizes well across diverse object morphologies nor scales effectively to real-world environment. To address these limitations, we introduce LOME, an egocentric world model that can generate realistic human-object interactions as videos conditioned on an input image, a text prompt, and per-frame human actions, including both body poses and hand gestures. LOME injects strong and precise action guidance into object manipulation by jointly estimating spatial human actions and the environment contexts during training. After finetuning a pretrained video generative model on videos of diverse egocentric human-object interactions, LOME demonstrates not only high action-following accuracy and strong generalization to unseen scenarios, but also realistic physical consequences of hand-object interactions, e.g., liquid flowing from a bottle into a mug after executing a ``pouring'' action. Extensive experiments demonstrate that our video-based framework significantly outperforms state-of-the-art image based and video-based action-conditioned methods and Image/Text-to-Video (I/T2V) generative model in terms of both temporal consistency and motion control. LOME paves the way for photorealistic AR/VR experiences and scalable robotic training, without being limited to simulated environments or relying on explicit 3D/4D modeling.
Learning-based Multi-View Stereo: A Survey
Aug 27, 2024



3D reconstruction aims to recover the dense 3D structure of a scene. It plays an essential role in various applications such as Augmented/Virtual Reality (AR/VR), autonomous driving and robotics. Leveraging multiple views of a scene captured from different viewpoints, Multi-View Stereo (MVS) algorithms synthesize a comprehensive 3D representation, enabling precise reconstruction in complex environments. Due to its efficiency and effectiveness, MVS has become a pivotal method for image-based 3D reconstruction. Recently, with the success of deep learning, many learning-based MVS methods have been proposed, achieving impressive performance against traditional methods. We categorize these learning-based methods as: depth map-based, voxel-based, NeRF-based, 3D Gaussian Splatting-based, and large feed-forward methods. Among these, we focus significantly on depth map-based methods, which are the main family of MVS due to their conciseness, flexibility and scalability. In this survey, we provide a comprehensive review of the literature at the time of this writing. We investigate these learning-based methods, summarize their performances on popular benchmarks, and discuss promising future research directions in this area.
InSpaceType: Dataset and Benchmark for Reconsidering Cross-Space Type Performance in Indoor Monocular Depth
Aug 25, 2024Indoor monocular depth estimation helps home automation, including robot navigation or AR/VR for surrounding perception. Most previous methods primarily experiment with the NYUv2 Dataset and concentrate on the overall performance in their evaluation. However, their robustness and generalization to diversely unseen types or categories for indoor spaces (spaces types) have yet to be discovered. Researchers may empirically find degraded performance in a released pretrained model on custom data or less-frequent types. This paper studies the common but easily overlooked factor-space type and realizes a model's performance variances across spaces. We present InSpaceType Dataset, a high-quality RGBD dataset for general indoor scenes, and benchmark 13 recent state-of-the-art methods on InSpaceType. Our examination shows that most of them suffer from performance imbalance between head and tailed types, and some top methods are even more severe. The work reveals and analyzes underlying bias in detail for transparency and robustness. We extend the analysis to a total of 4 datasets and discuss the best practice in synthetic data curation for training indoor monocular depth. Further, dataset ablation is conducted to find out the key factor in generalization. This work marks the first in-depth investigation of performance variances across space types and, more importantly, releases useful tools, including datasets and codes, to closely examine your pretrained depth models. Data and code: https://depthcomputation.github.io/DepthPublic/
RP1M: A Large-Scale Motion Dataset for Piano Playing with Bi-Manual Dexterous Robot Hands
Aug 20, 2024



It has been a long-standing research goal to endow robot hands with human-level dexterity. Bi-manual robot piano playing constitutes a task that combines challenges from dynamic tasks, such as generating fast while precise motions, with slower but contact-rich manipulation problems. Although reinforcement learning based approaches have shown promising results in single-task performance, these methods struggle in a multi-song setting. Our work aims to close this gap and, thereby, enable imitation learning approaches for robot piano playing at scale. To this end, we introduce the Robot Piano 1 Million (RP1M) dataset, containing bi-manual robot piano playing motion data of more than one million trajectories. We formulate finger placements as an optimal transport problem, thus, enabling automatic annotation of vast amounts of unlabeled songs. Benchmarking existing imitation learning approaches shows that such approaches reach state-of-the-art robot piano playing performance by leveraging RP1M.
Stratified Avatar Generation from Sparse Observations
Jun 03, 2024



Estimating 3D full-body avatars from AR/VR devices is essential for creating immersive experiences in AR/VR applications. This task is challenging due to the limited input from Head Mounted Devices, which capture only sparse observations from the head and hands. Predicting the full-body avatars, particularly the lower body, from these sparse observations presents significant difficulties. In this paper, we are inspired by the inherent property of the kinematic tree defined in the Skinned Multi-Person Linear (SMPL) model, where the upper body and lower body share only one common ancestor node, bringing the potential of decoupled reconstruction. We propose a stratified approach to decouple the conventional full-body avatar reconstruction pipeline into two stages, with the reconstruction of the upper body first and a subsequent reconstruction of the lower body conditioned on the previous stage. To implement this straightforward idea, we leverage the latent diffusion model as a powerful probabilistic generator, and train it to follow the latent distribution of decoupled motions explored by a VQ-VAE encoder-decoder model. Extensive experiments on AMASS mocap dataset demonstrate our state-of-the-art performance in the reconstruction of full-body motions.
GaussianFlow: Splatting Gaussian Dynamics for 4D Content Creation
Mar 19, 2024



Creating 4D fields of Gaussian Splatting from images or videos is a challenging task due to its under-constrained nature. While the optimization can draw photometric reference from the input videos or be regulated by generative models, directly supervising Gaussian motions remains underexplored. In this paper, we introduce a novel concept, Gaussian flow, which connects the dynamics of 3D Gaussians and pixel velocities between consecutive frames. The Gaussian flow can be efficiently obtained by splatting Gaussian dynamics into the image space. This differentiable process enables direct dynamic supervision from optical flow. Our method significantly benefits 4D dynamic content generation and 4D novel view synthesis with Gaussian Splatting, especially for contents with rich motions that are hard to be handled by existing methods. The common color drifting issue that happens in 4D generation is also resolved with improved Guassian dynamics. Superior visual quality on extensive experiments demonstrates our method's effectiveness. Quantitative and qualitative evaluations show that our method achieves state-of-the-art results on both tasks of 4D generation and 4D novel view synthesis. Project page: https://zerg-overmind.github.io/GaussianFlow.github.io/
MagicDance: Realistic Human Dance Video Generation with Motions & Facial Expressions Transfer
Nov 18, 2023In this work, we propose MagicDance, a diffusion-based model for 2D human motion and facial expression transfer on challenging human dance videos. Specifically, we aim to generate human dance videos of any target identity driven by novel pose sequences while keeping the identity unchanged. To this end, we propose a two-stage training strategy to disentangle human motions and appearance (e.g., facial expressions, skin tone and dressing), consisting of the pretraining of an appearance-control block and fine-tuning of an appearance-pose-joint-control block over human dance poses of the same dataset. Our novel design enables robust appearance control with temporally consistent upper body, facial attributes, and even background. The model also generalizes well on unseen human identities and complex motion sequences without the need for any fine-tuning with additional data with diverse human attributes by leveraging the prior knowledge of image diffusion models. Moreover, the proposed model is easy to use and can be considered as a plug-in module/extension to Stable Diffusion. We also demonstrate the model's ability for zero-shot 2D animation generation, enabling not only the appearance transfer from one identity to another but also allowing for cartoon-like stylization given only pose inputs. Extensive experiments demonstrate our superior performance on the TikTok dataset.
InSpaceType: Reconsider Space Type in Indoor Monocular Depth Estimation
Sep 24, 2023Indoor monocular depth estimation has attracted increasing research interest. Most previous works have been focusing on methodology, primarily experimenting with NYU-Depth-V2 (NYUv2) Dataset, and only concentrated on the overall performance over the test set. However, little is known regarding robustness and generalization when it comes to applying monocular depth estimation methods to real-world scenarios where highly varying and diverse functional \textit{space types} are present such as library or kitchen. A study for performance breakdown into space types is essential to realize a pretrained model's performance variance. To facilitate our investigation for robustness and address limitations of previous works, we collect InSpaceType, a high-quality and high-resolution RGBD dataset for general indoor environments. We benchmark 11 recent methods on InSpaceType and find they severely suffer from performance imbalance concerning space types, which reveals their underlying bias. We extend our analysis to 4 other datasets, 3 mitigation approaches, and the ability to generalize to unseen space types. Our work marks the first in-depth investigation of performance imbalance across space types for indoor monocular depth estimation, drawing attention to potential safety concerns for model deployment without considering space types, and further shedding light on potential ways to improve robustness. See \url{https://depthcomputation.github.io/DepthPublic} for data.
Strivec: Sparse Tri-Vector Radiance Fields
Jul 25, 2023



We propose Strivec, a novel neural representation that models a 3D scene as a radiance field with sparsely distributed and compactly factorized local tensor feature grids. Our approach leverages tensor decomposition, following the recent work TensoRF, to model the tensor grids. In contrast to TensoRF which uses a global tensor and focuses on their vector-matrix decomposition, we propose to utilize a cloud of local tensors and apply the classic CANDECOMP/PARAFAC (CP) decomposition to factorize each tensor into triple vectors that express local feature distributions along spatial axes and compactly encode a local neural field. We also apply multi-scale tensor grids to discover the geometry and appearance commonalities and exploit spatial coherence with the tri-vector factorization at multiple local scales. The final radiance field properties are regressed by aggregating neural features from multiple local tensors across all scales. Our tri-vector tensors are sparsely distributed around the actual scene surface, discovered by a fast coarse reconstruction, leveraging the sparsity of a 3D scene. We demonstrate that our model can achieve better rendering quality while using significantly fewer parameters than previous methods, including TensoRF and Instant-NGP.
Controllable 3D Generative Adversarial Face Model via Disentangling Shape and Appearance
Aug 30, 2022
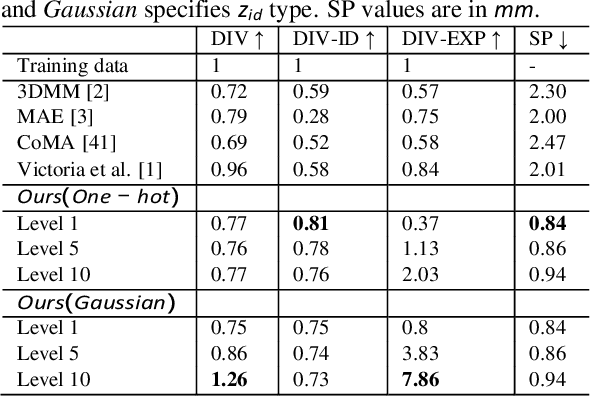
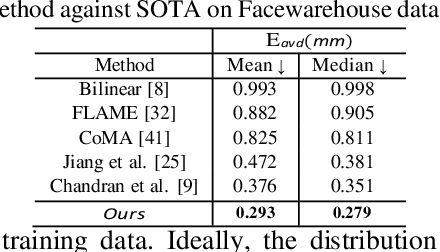
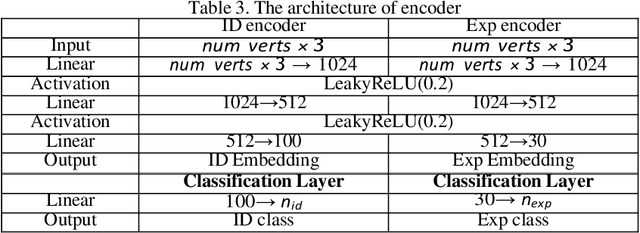
3D face modeling has been an active area of research in computer vision and computer graphics, fueling applications ranging from facial expression transfer in virtual avatars to synthetic data generation. Existing 3D deep learning generative models (e.g., VAE, GANs) allow generating compact face representations (both shape and texture) that can model non-linearities in the shape and appearance space (e.g., scatter effects, specularities, etc.). However, they lack the capability to control the generation of subtle expressions. This paper proposes a new 3D face generative model that can decouple identity and expression and provides granular control over expressions. In particular, we propose using a pair of supervised auto-encoder and generative adversarial networks to produce high-quality 3D faces, both in terms of appearance and shape. Experimental results in the generation of 3D faces learned with holistic expression labels, or Action Unit labels, show how we can decouple identity and expression; gaining fine-control over expressions while preserving identity.