 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotated Runtime Smooth: Training-Free Activation Smoother for accurate INT4 inference
Sep 30, 2024



Large language models have demonstrated promising capabilities upon scaling up parameters. However, serving large language models incurs substantial computation and memory movement costs due to their large scale. Quantization methods have been employed to reduce service costs and latency. Nevertheless, outliers in activations hinder the development of INT4 weight-activation quantization. Existing approaches separate outliers and normal values into two matrices or migrate outliers from activations to weights, suffering from high latency or accuracy degradation. Based on observing activations from large language models, outliers can be classified into channel-wise and spike outliers. In this work, we propose Rotated Runtime Smooth (RRS), a plug-and-play activation smoother for quantization, consisting of Runtime Smooth and the Rotation operation. Runtime Smooth (RS) is introduced to eliminate channel-wise outliers by smoothing activations with channel-wise maximums during runtime. The rotation operation can narrow the gap between spike outliers and normal values, alleviating the effect of victims caused by channel-wise smoothing. The proposed method outperforms the state-of-the-art method in the LLaMA and Qwen families and improves WikiText-2 perplexity from 57.33 to 6.66 for INT4 inference.
One QuantLLM for ALL: Fine-tuning Quantized LLMs Once for Efficient Deployments
May 30, 2024



Large Language Models (LLMs) have advanced rapidly but face significant memory demands. While quantization has shown promise for LLMs, current methods typically require lengthy training to alleviate the performance degradation from quantization loss. However, deploying LLMs across diverse scenarios with different resource constraints, e.g., servers and personal computers, requires repeated training per application, which amplifies the lengthy training problem. Given that, it is advantageous to train a once-for-all (OFA) supernet capable of yielding diverse optimal subnets for downstream applications through one-shot training. Nonetheless, the scale of current language models impedes efficiency and amplifies interference from weight sharing between subnets. We make an initial attempt to extend the once-for-all framework to large language models. Specifically, we decouple shared weights to eliminate the interference and incorporate Low-Rank adapters for training efficiency. Furthermore, we observe the imbalance allocation of training resources from the traditional uniform sampling. A non-parametric scheduler is introduced to adjust the sampling rate for each quantization configuration, achieving a more balanced allocation among subnets with varying demands. We validate the approach on LLaMA2 families, and downstream evaluation confirms our ability to maintain high performance while significantly reducing deployment time faced with multiple scenarios.
A Survey of Time Series Foundation Models: Generalizing Time Series Representation with Large Language Model
May 07, 2024



Time series data are ubiquitous across various domains, making time series analysis critically important. Traditional time series models are task-specific, featuring singular functionality and limited generalization capacity. Recently, large language foundation models have unveiled their remarkable capabilities for cross-task transferability, zero-shot/few-shot learning, and decision-making explainability. This success has sparked interest in the exploration of foundation models to solve multiple time series challenges simultaneously. There are two main research lines, namely pre-training foundation models from scratch for time series and adapting large language foundation models for time series. They both contribute to the development of a unified model that is highly generalizable, versatile, and comprehensible for time series analysis. This survey offers a 3E analytical framework for comprehensive examination of related research. Specifically, we examine existing works from three dimensions, namely Effectiveness, Efficiency and Explainability. In each dimension, we focus on discussing how related works devise tailored solution by considering unique challenges in the realm of time series. Furthermore, we provide a domain taxonomy to help followers keep up with the domain-specific advancements. In addition, we introduce extensive resources to facilitate the field's development, including datasets, open-source, time series libraries. A GitHub repository is also maintained for resource updates (https://github.com/start2020/Awesome-TimeSeries-LLM-FM).
Differentially Private Covariance Revisited
May 31, 2022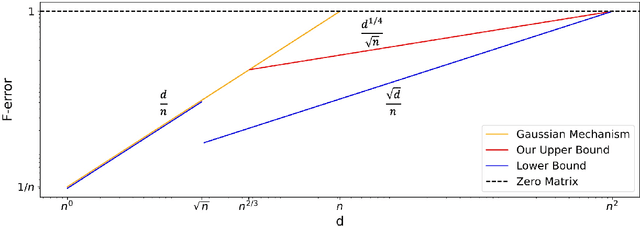
In this paper, we present three new error bounds, in terms of the Frobenius norm, for covariance estimation under differential privacy: (1) a worst-case bound of $\tilde{O}(d^{1/4}/\sqrt{n})$, which improves the standard Gaussian mechanism $\tilde{O}(d/n)$ for the regime $d>\widetilde{\Omega}(n^{2/3})$; (2) a trace-sensitive bound that improves the state of the art by a $\sqrt{d}$-factor, and (3) a tail-sensitive bound that gives a more instance-specific result. The corresponding algorithms are also simple and efficient. Experimental results show that they offer significant improvements over prior work.
OneDConv: Generalized Convolution For Transform-Invariant Representation
Jan 15, 2022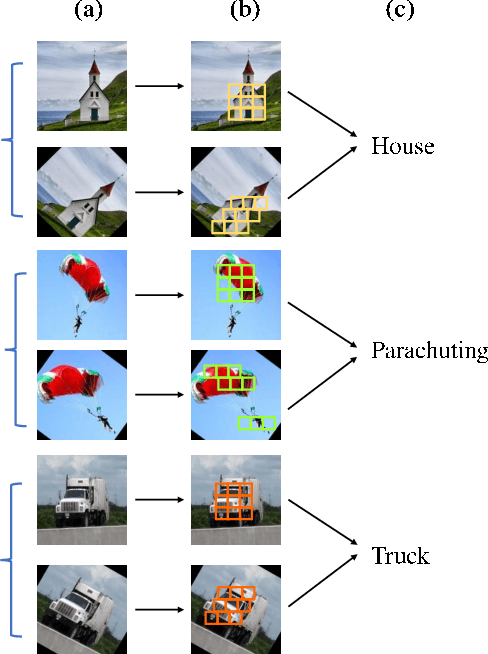
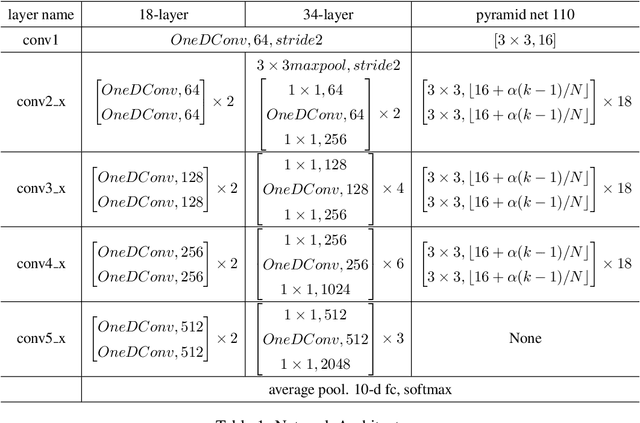
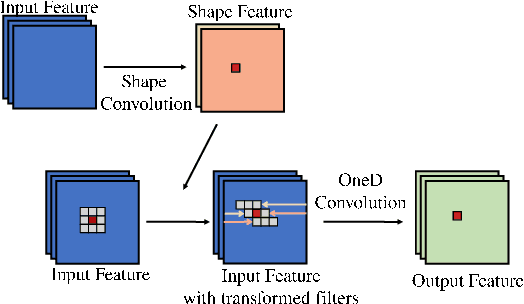
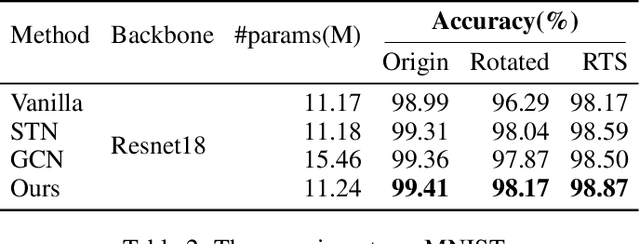
Convolutional Neural Networks (CNNs) have exhibited their great power in a variety of vision tasks. However, the lack of transform-invariant property limits their further applications in complicated real-world scenarios. In this work, we proposed a novel generalized one dimension convolutional operator (OneDConv), which dynamically transforms the convolution kernels based on the input features in a computationally and parametrically efficient manner. The proposed operator can extract the transform-invariant features naturally. It improves the robustness and generalization of convolution without sacrificing the performance on common images. The proposed OneDConv operator can substitute the vanilla convolution, thus it can be incorporated into current popular convolutional architectures and trained end-to-end readily. On several popular benchmarks, OneDConv outperforms the original convolution operation and other proposed models both in canonical and distorted images.
Frequency Estimation Under Multiparty Differential Privacy: One-shot and Streaming
Apr 05, 2021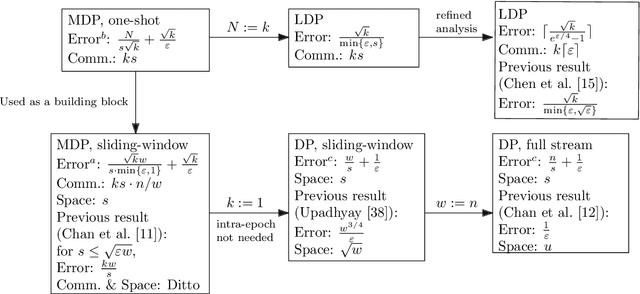
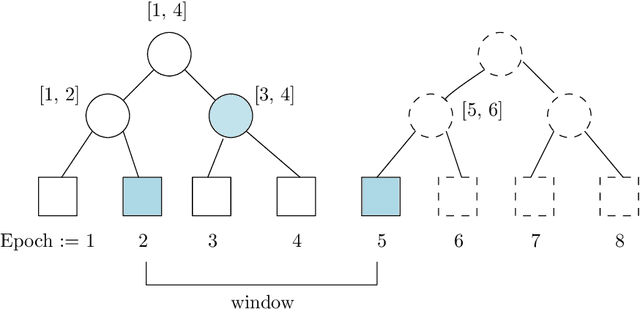
We study the fundamental problem of frequency estimation under both privacy and communication constraints, where the data is distributed among $k$ parties. We consider two application scenarios: (1) one-shot, where the data is static and the aggregator conducts a one-time computation; and (2) streaming, where each party receives a stream of items over time and the aggregator continuously monitors the frequencies. We adopt the model of multiparty differential privacy (MDP), which is more general than local differential privacy (LDP) and (centralized) differential privacy. Our protocols achieve optimality (up to logarithmic factors) permissible by the more stringent of the two constraints. In particular, when specialized to the $\varepsilon$-LDP model, our protocol achieves an error of $\sqrt{k}/(e^{\Theta(\varepsilon)}-1)$ for all $\varepsilon$, while the previous protocol (Chen et al., 2020) has error $O(\sqrt{k}/\min\{\varepsilon, \sqrt{\varepsilon}\})$.
Communication-Efficient Weighted Sampling and Quantile Summary for GBDT
Sep 17, 2019
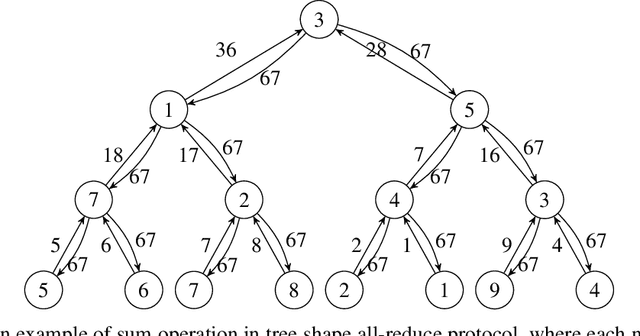
Gradient boosting decision tree (GBDT) is a powerful and widely-used machine learning model, which has achieved state-of-the-art performance in many academic areas and production environment. However, communication overhead is the main bottleneck in distributed training which can handle the massive data nowadays. In this paper, we propose two novel communication-efficient methods over distributed dataset to mitigate this problem, a weighted sampling approach by which we can estimate the information gain over a small subset efficiently, and distributed protocols for weighted quantile problem used in approximate tree learning.