 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReturn-Based Contrastive Representation Learning for Reinforcement Learning
Feb 22, 2021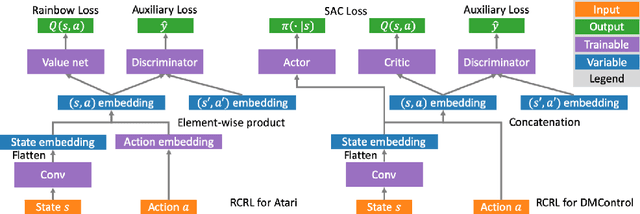
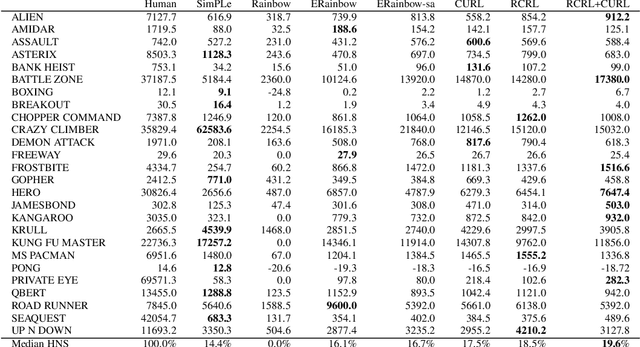
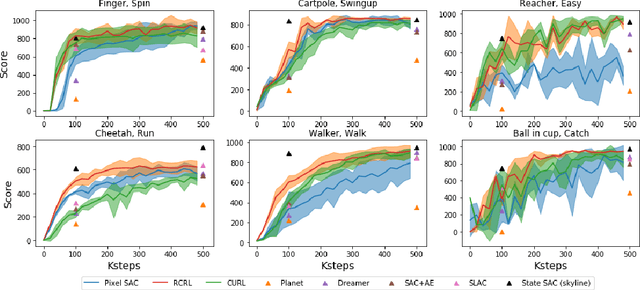
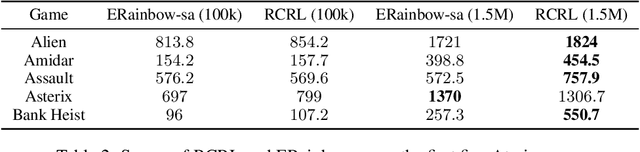
Recently, various auxiliary tasks have been proposed to accelerate representation learning and improve sample efficiency in deep reinforcement learning (RL). However, existing auxiliary tasks do not take the characteristics of RL problems into consideration and are unsupervised. By leveraging returns, the most important feedback signals in RL, we propose a novel auxiliary task that forces the learnt representations to discriminate state-action pairs with different returns. Our auxiliary loss is theoretically justified to learn representations that capture the structure of a new form of state-action abstraction, under which state-action pairs with similar return distributions are aggregated together. In low data regime, our algorithm outperforms strong baselines on complex tasks in Atari games and DeepMind Control suite, and achieves even better performance when combined with existing auxiliary tasks.
REST: Relational Event-driven Stock Trend Forecasting
Feb 19, 2021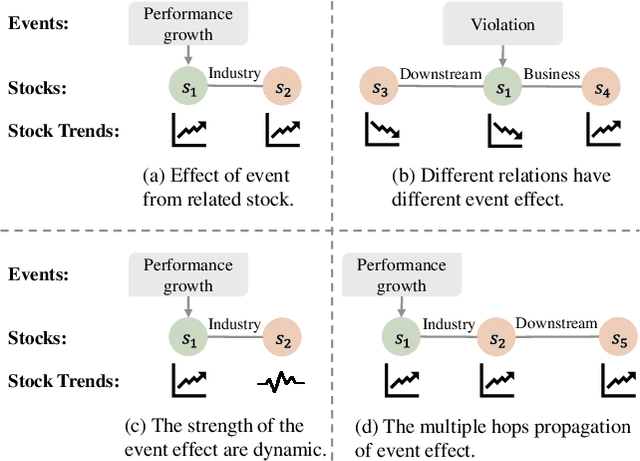

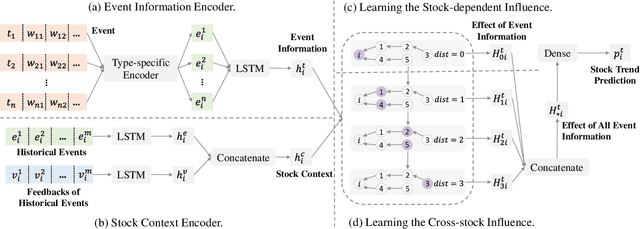
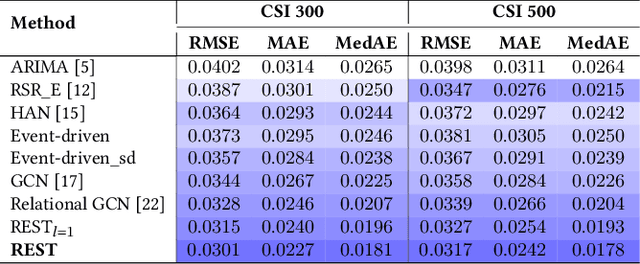
Stock trend forecasting, aiming at predicting the stock future trends, is crucial for investors to seek maximized profits from the stock market. Many event-driven methods utilized the events extracted from news, social media, and discussion board to forecast the stock trend in recent years. However, existing event-driven methods have two main shortcomings: 1) overlooking the influence of event information differentiated by the stock-dependent properties; 2) neglecting the effect of event information from other related stocks. In this paper, we propose a relational event-driven stock trend forecasting (REST) framework, which can address the shortcoming of existing methods. To remedy the first shortcoming, we propose to model the stock context and learn the effect of event information on the stocks under different contexts. To address the second shortcoming, we construct a stock graph and design a new propagation layer to propagate the effect of event information from related stocks. The experimental studies on the real-world data demonstrate the efficiency of our REST framework. The results of investment simulation show that our framework can achieve a higher return of investment than baselines.
Revisiting Language Encoding in Learning Multilingual Representations
Feb 16, 2021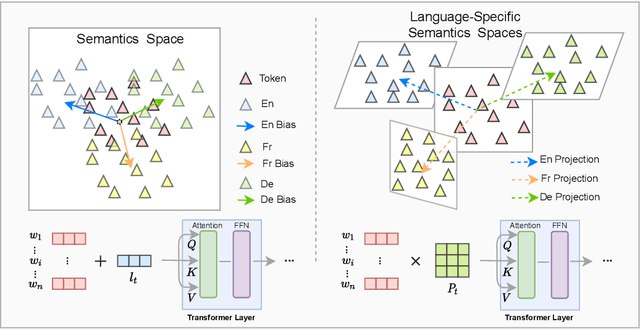
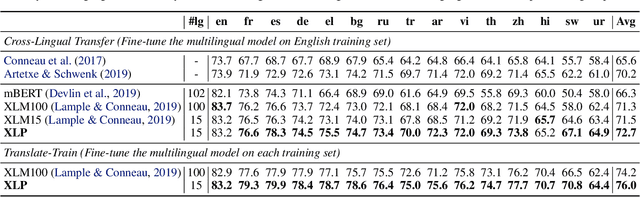
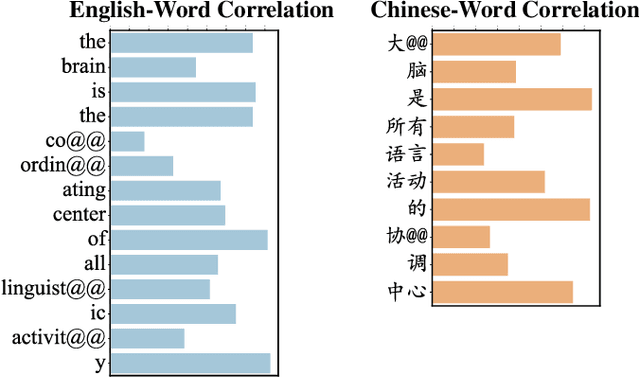

Transformer has demonstrated its great power to learn contextual word representations for multiple languages in a single model. To process multilingual sentences in the model, a learnable vector is usually assigned to each language, which is called "language embedding". The language embedding can be either added to the word embedding or attached at the beginning of the sentence. It serves as a language-specific signal for the Transformer to capture contextual representations across languages. In this paper, we revisit the use of language embedding and identify several problems in the existing formulations. By investigating the interaction between language embedding and word embedding in the self-attention module, we find that the current methods cannot reflect the language-specific word correlation well. Given these findings, we propose a new approach called Cross-lingual Language Projection (XLP) to replace language embedding. For a sentence, XLP projects the word embeddings into language-specific semantic space, and then the projected embeddings will be fed into the Transformer model to process with their language-specific meanings. In such a way, XLP achieves the purpose of appropriately encoding "language" in a multilingual Transformer model. Experimental results show that XLP can freely and significantly boost the model performance on extensive multilingual benchmark datasets. Codes and models will be released at https://github.com/lsj2408/XLP.
LightSpeech: Lightweight and Fast Text to Speech with Neural Architecture Search
Feb 08, 2021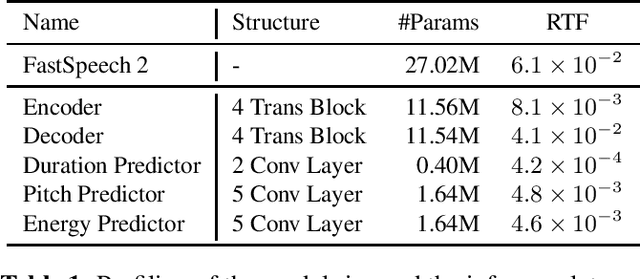
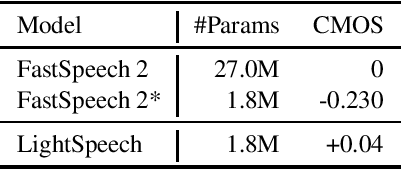

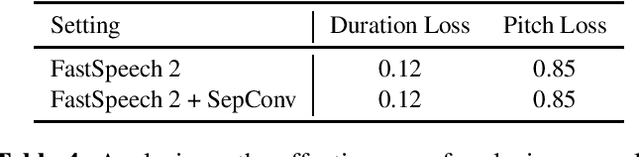
Text to speech (TTS) has been broadly used to synthesize natural and intelligible speech in different scenarios. Deploying TTS in various end devices such as mobile phones or embedded devices requires extremely small memory usage and inference latency. While non-autoregressive TTS models such as FastSpeech have achieved significantly faster inference speed than autoregressive models, their model size and inference latency are still large for the deployment in resource constrained devices. In this paper, we propose LightSpeech, which leverages neural architecture search~(NAS) to automatically design more lightweight and efficient models based on FastSpeech. We first profile the components of current FastSpeech model and carefully design a novel search space containing various lightweight and potentially effective architectures. Then NAS is utilized to automatically discover well performing architectures within the search space. Experiments show that the model discovered by our method achieves 15x model compression ratio and 6.5x inference speedup on CPU with on par voice quality. Audio demos are provided at https://speechresearch.github.io/lightspeech.
BN-invariant sharpness regularizes the training model to better generalization
Jan 08, 2021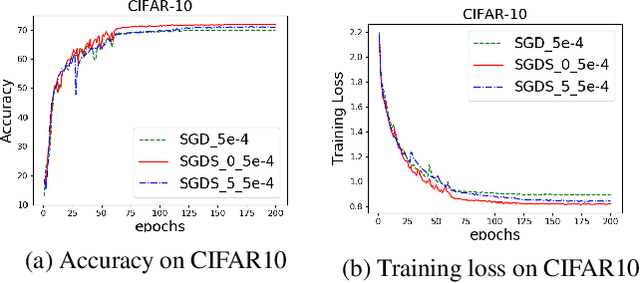
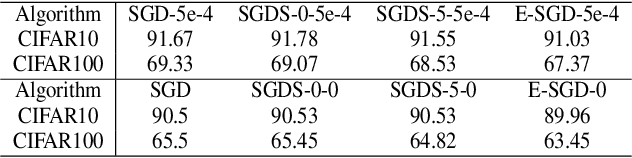
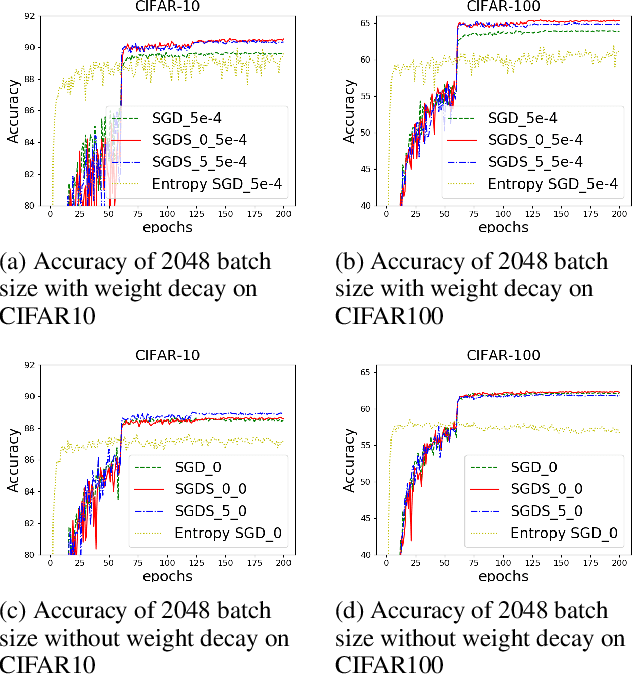
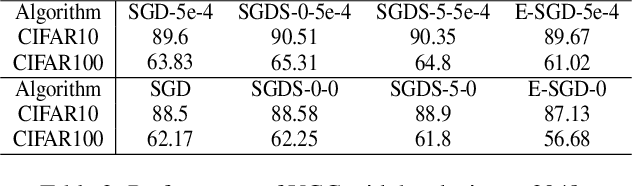
It is arguably believed that flatter minima can generalize better. However, it has been pointed out that the usual definitions of sharpness, which consider either the maxima or the integral of loss over a $\delta$ ball of parameters around minima, cannot give consistent measurement for scale invariant neural networks, e.g., networks with batch normalization layer. In this paper, we first propose a measure of sharpness, BN-Sharpness, which gives consistent value for equivalent networks under BN. It achieves the property of scale invariance by connecting the integral diameter with the scale of parameter. Then we present a computation-efficient way to calculate the BN-sharpness approximately i.e., one dimensional integral along the "sharpest" direction. Furthermore, we use the BN-sharpness to regularize the training and design an algorithm to minimize the new regularized objective. Our algorithm achieves considerably better performance than vanilla SGD over various experiment settings.
Cooperative Policy Learning with Pre-trained Heterogeneous Observation Representations
Dec 24, 2020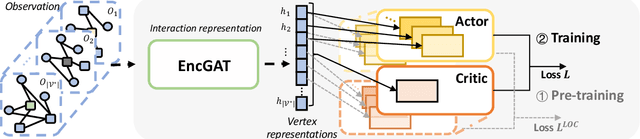
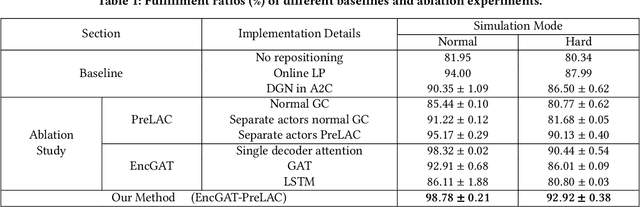
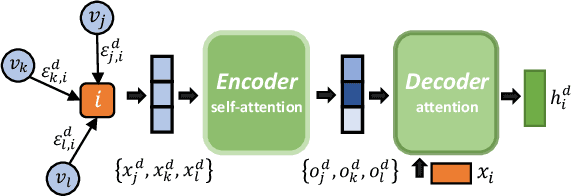

Multi-agent reinforcement learning (MARL) has been increasingly explored to learn the cooperative policy towards maximizing a certain global reward. Many existing studies take advantage of graph neural networks (GNN) in MARL to propagate critical collaborative information over the interaction graph, built upon inter-connected agents. Nevertheless, the vanilla GNN approach yields substantial defects in dealing with complex real-world scenarios since the generic message passing mechanism is ineffective between heterogeneous vertices and, moreover, simple message aggregation functions are incapable of accurately modeling the combinational interactions from multiple neighbors. While adopting complex GNN models with more informative message passing and aggregation mechanisms can obviously benefit heterogeneous vertex representations and cooperative policy learning, it could, on the other hand, increase the training difficulty of MARL and demand more intense and direct reward signals compared to the original global reward. To address these challenges, we propose a new cooperative learning framework with pre-trained heterogeneous observation representations. Particularly, we employ an encoder-decoder based graph attention to learn the intricate interactions and heterogeneous representations that can be more easily leveraged by MARL. Moreover, we design a pre-training with local actor-critic algorithm to ease the difficulty in cooperative policy learning. Extensive experiments over real-world scenarios demonstrate that our new approach can significantly outperform existing MARL baselines as well as operational research solutions that are widely-used in industry.
Learning Causal Semantic Representation for Out-of-Distribution Prediction
Nov 03, 2020
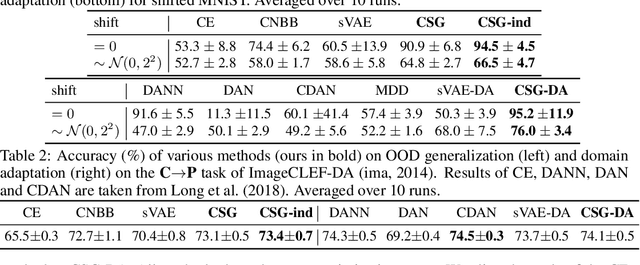
Conventional supervised learning methods, especially deep ones, are found to be sensitive to out-of-distribution (OOD) examples, largely because the learned representation mixes the semantic factor with the variation factor due to their domain-specific correlation, while only the semantic factor causes the output. To address the problem, we propose a Causal Semantic Generative model (CSG) based on causality to model the two factors separately, and learn it on a single training domain for prediction without (OOD generalization) or with (domain adaptation) unsupervised data in a test domain. We prove that CSG identifies the semantic factor on the training domain, and the invariance principle of causality subsequently guarantees the boundedness of OOD generalization error and the success of adaptation. We design learning methods for both effective learning and easy prediction, by leveraging the graphical structure of CSG. Empirical study demonstrates the effect of our methods to improve test accuracy for OOD generalization and domain adaptation.
COSEA: Convolutional Code Search with Layer-wise Attention
Oct 19, 2020
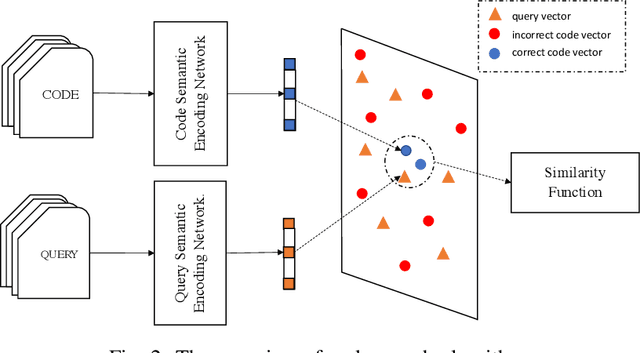
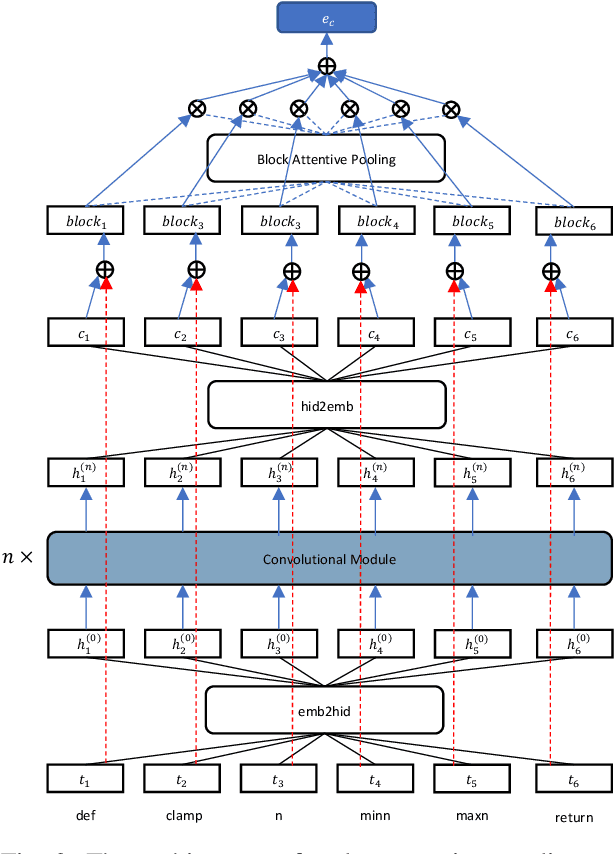
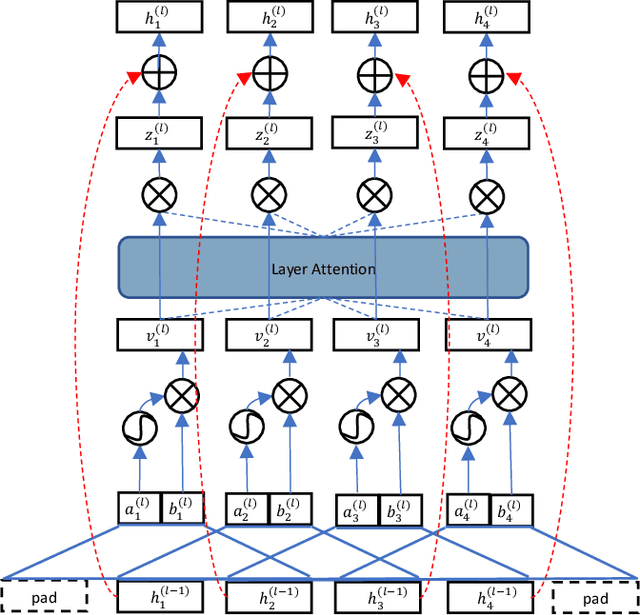
Semantic code search, which aims to retrieve code snippets relevant to a given natural language query, has attracted many research efforts with the purpose of accelerating software development. The huge amount of online publicly available code repositories has prompted the employment of deep learning techniques to build state-of-the-art code search models. Particularly, they leverage deep neural networks to embed codes and queries into a unified semantic vector space and then use the similarity between code's and query's vectors to approximate the semantic correlation between code and the query. However, most existing studies overlook the code's intrinsic structural logic, which indeed contains a wealth of semantic information, and fails to capture intrinsic features of codes. In this paper, we propose a new deep learning architecture, COSEA, which leverages convolutional neural networks with layer-wise attention to capture the valuable code's intrinsic structural logic. To further increase the learning efficiency of COSEA, we propose a variant of contrastive loss for training the code search model, where the ground-truth code should be distinguished from the most similar negative sample. We have implemented a prototype of COSEA. Extensive experiments over existing public datasets of Python and SQL have demonstrated that COSEA can achieve significant improvements over state-of-the-art methods on code search tasks.
Qlib: An AI-oriented Quantitative Investment Platform
Sep 22, 2020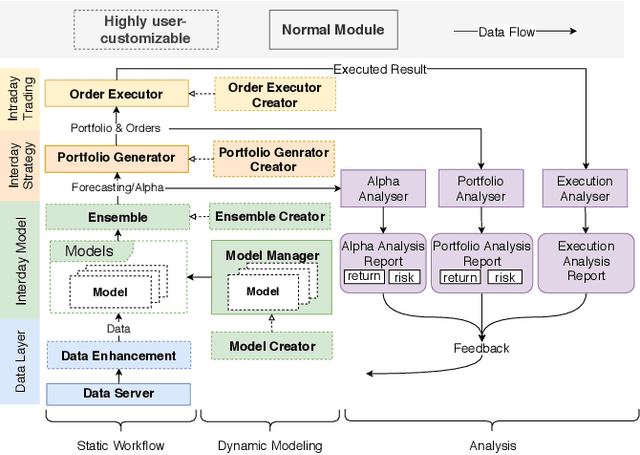
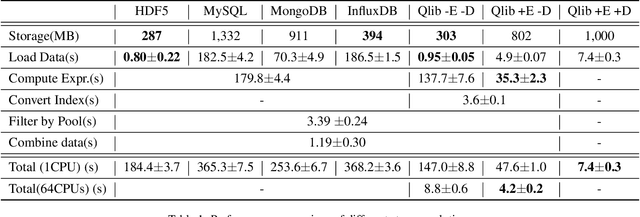
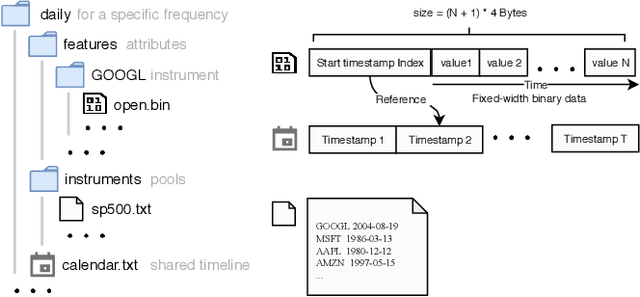
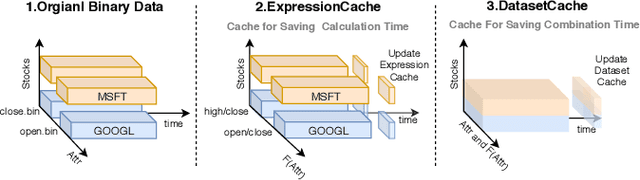
Quantitative investment aims to maximize the return and minimize the risk in a sequential trading period over a set of financial instruments. Recently, inspired by rapid development and great potential of AI technologies in generating remarkable innovation in quantitative investment, there has been increasing adoption of AI-driven workflow for quantitative research and practical investment. In the meantime of enriching the quantitative investment methodology, AI technologies have raised new challenges to the quantitative investment system. Particularly, the new learning paradigms for quantitative investment call for an infrastructure upgrade to accommodate the renovated workflow; moreover, the data-driven nature of AI technologies indeed indicates a requirement of the infrastructure with more powerful performance; additionally, there exist some unique challenges for applying AI technologies to solve different tasks in the financial scenarios. To address these challenges and bridge the gap between AI technologies and quantitative investment, we design and develop Qlib that aims to realize the potential, empower the research, and create the value of AI technologies in quantitative investment.
HiFiSinger: Towards High-Fidelity Neural Singing Voice Synthesis
Sep 03, 2020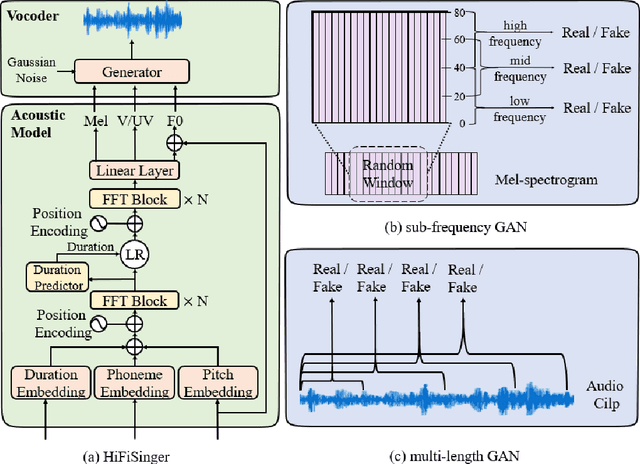
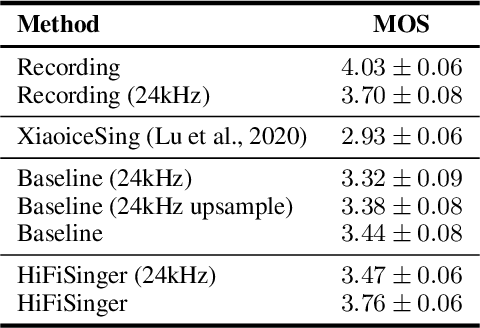

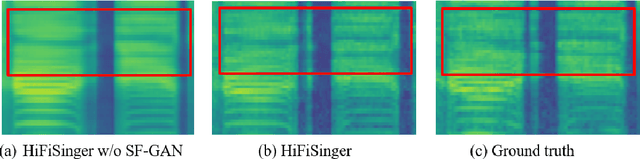
High-fidelity singing voices usually require higher sampling rate (e.g., 48kHz) to convey expression and emotion. However, higher sampling rate causes the wider frequency band and longer waveform sequences and throws challenges for singing voice synthesis (SVS) in both frequency and time domains. Conventional SVS systems that adopt small sampling rate cannot well address the above challenges. In this paper, we develop HiFiSinger, an SVS system towards high-fidelity singing voice. HiFiSinger consists of a FastSpeech based acoustic model and a Parallel WaveGAN based vocoder to ensure fast training and inference and also high voice quality. To tackle the difficulty of singing modeling caused by high sampling rate (wider frequency band and longer waveform), we introduce multi-scale adversarial training in both the acoustic model and vocoder to improve singing modeling. Specifically, 1) To handle the larger range of frequencies caused by higher sampling rate, we propose a novel sub-frequency GAN (SF-GAN) on mel-spectrogram generation, which splits the full 80-dimensional mel-frequency into multiple sub-bands and models each sub-band with a separate discriminator. 2) To model longer waveform sequences caused by higher sampling rate, we propose a multi-length GAN (ML-GAN) for waveform generation to model different lengths of waveform sequences with separate discriminators. 3) We also introduce several additional designs and findings in HiFiSinger that are crucial for high-fidelity voices, such as adding F0 (pitch) and V/UV (voiced/unvoiced flag) as acoustic features, choosing an appropriate window/hop size for mel-spectrogram, and increasing the receptive field in vocoder for long vowel modeling. Experiment results show that HiFiSinger synthesizes high-fidelity singing voices with much higher quality: 0.32/0.44 MOS gain over 48kHz/24kHz baseline and 0.83 MOS gain over previous SVS systems.