 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRXFOOD: Plug-in RGB-X Fusion for Object of Interest Detection
Jun 22, 2023The emergence of different sensors (Near-Infrared, Depth, etc.) is a remedy for the limited application scenarios of traditional RGB camera. The RGB-X tasks, which rely on RGB input and another type of data input to resolve specific problems, have become a popular research topic in multimedia. A crucial part in two-branch RGB-X deep neural networks is how to fuse information across modalities. Given the tremendous information inside RGB-X networks, previous works typically apply naive fusion (e.g., average or max fusion) or only focus on the feature fusion at the same scale(s). While in this paper, we propose a novel method called RXFOOD for the fusion of features across different scales within the same modality branch and from different modality branches simultaneously in a unified attention mechanism. An Energy Exchange Module is designed for the interaction of each feature map's energy matrix, who reflects the inter-relationship of different positions and different channels inside a feature map. The RXFOOD method can be easily incorporated to any dual-branch encoder-decoder network as a plug-in module, and help the original backbone network better focus on important positions and channels for object of interest detection. Experimental results on RGB-NIR salient object detection, RGB-D salient object detection, and RGBFrequency image manipulation detection demonstrate the clear effectiveness of the proposed RXFOOD.
Loss Attitude Aware Energy Management for Signal Detection
Jan 18, 2023
This work considers a Bayesian signal processing problem where increasing the power of the probing signal may cause risks or undesired consequences. We employ a market based approach to solve energy management problems for signal detection while balancing multiple objectives. In particular, the optimal amount of resource consumption is determined so as to maximize a profit-loss based expected utility function. Next, we study the human behavior of resource consumption while taking individuals' behavioral disparity into account. Unlike rational decision makers who consume the amount of resource to maximize the expected utility function, human decision makers act to maximize their subjective utilities. We employ prospect theory to model humans' loss aversion towards a risky event. The amount of resource consumption that maximizes the humans' subjective utility is derived to characterize the actual behavior of humans. It is shown that loss attitudes may lead the human to behave quite differently from a rational decision maker.
Compact Multi-level Sparse Neural Networks with Input Independent Dynamic Rerouting
Dec 21, 2021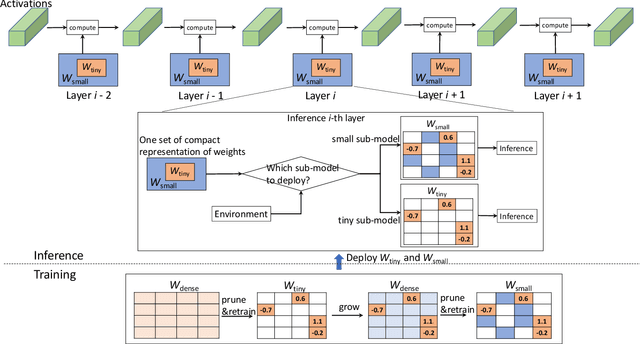

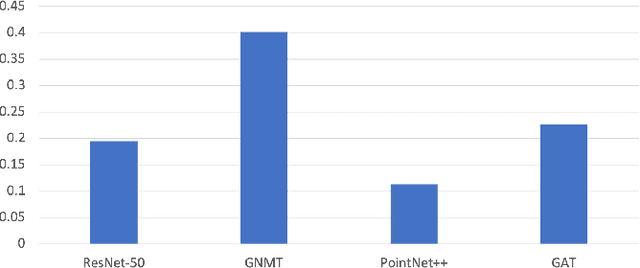
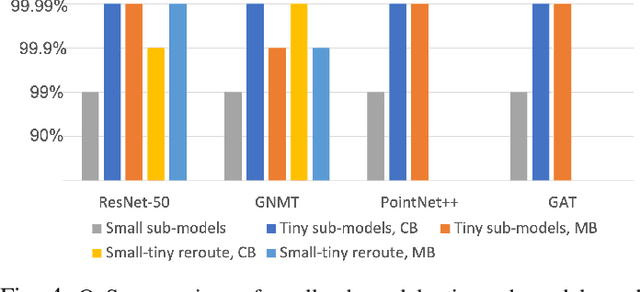
Deep neural networks (DNNs) have shown to provide superb performance in many real life applications, but their large computation cost and storage requirement have prevented them from being deployed to many edge and internet-of-things (IoT) devices. Sparse deep neural networks, whose majority weight parameters are zeros, can substantially reduce the computation complexity and memory consumption of the models. In real-use scenarios, devices may suffer from large fluctuations of the available computation and memory resources under different environment, and the quality of service (QoS) is difficult to maintain due to the long tail inferences with large latency. Facing the real-life challenges, we propose to train a sparse model that supports multiple sparse levels. That is, a hierarchical structure of weights are satisfied such that the locations and the values of the non-zero parameters of the more-sparse sub-model area subset of the less-sparse sub-model. In this way, one can dynamically select the appropriate sparsity level during inference, while the storage cost is capped by the least sparse sub-model. We have verified our methodologies on a variety of DNN models and tasks, including the ResNet-50, PointNet++, GNMT, and graph attention networks. We obtain sparse sub-models with an average of 13.38% weights and 14.97% FLOPs, while the accuracies are as good as their dense counterparts. More-sparse sub-models with 5.38% weights and 4.47% of FLOPs, which are subsets of the less-sparse ones, can be obtained with only 3.25% relative accuracy loss.
Load-balanced Gather-scatter Patterns for Sparse Deep Neural Networks
Dec 20, 2021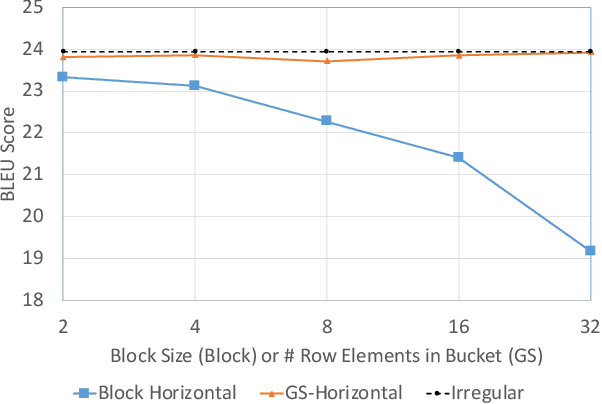
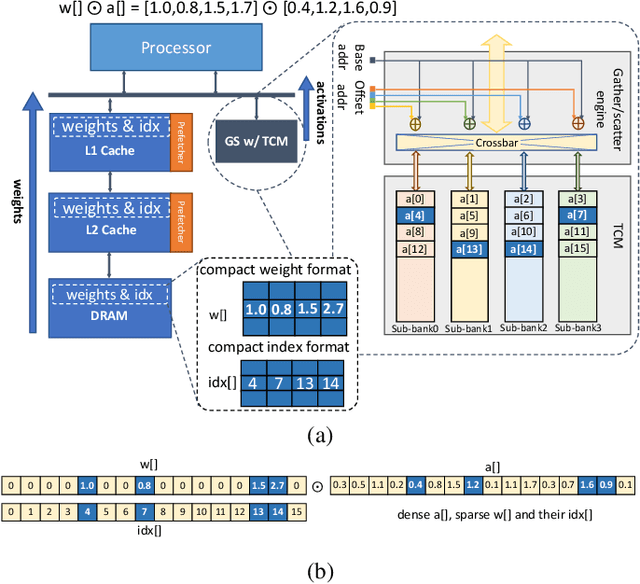

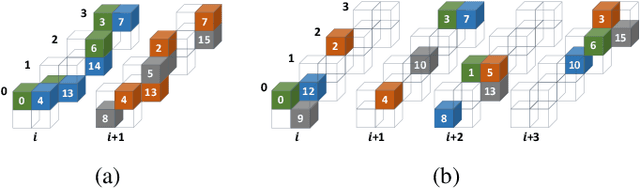
Deep neural networks (DNNs) have been proven to be effective in solving many real-life problems, but its high computation cost prohibits those models from being deployed to edge devices. Pruning, as a method to introduce zeros to model weights, has shown to be an effective method to provide good trade-offs between model accuracy and computation efficiency, and is a widely-used method to generate compressed models. However, the granularity of pruning makes important trade-offs. At the same sparsity level, a coarse-grained structured sparse pattern is more efficient on conventional hardware but results in worse accuracy, while a fine-grained unstructured sparse pattern can achieve better accuracy but is inefficient on existing hardware. On the other hand, some modern processors are equipped with fast on-chip scratchpad memories and gather/scatter engines that perform indirect load and store operations on such memories. In this work, we propose a set of novel sparse patterns, named gather-scatter (GS) patterns, to utilize the scratchpad memories and gather/scatter engines to speed up neural network inferences. Correspondingly, we present a compact sparse format. The proposed set of sparse patterns, along with a novel pruning methodology, address the load imbalance issue and result in models with quality close to unstructured sparse models and computation efficiency close to structured sparse models. Our experiments show that GS patterns consistently make better trade-offs between accuracy and computation efficiency compared to conventional structured sparse patterns. GS patterns can reduce the runtime of the DNN components by two to three times at the same accuracy levels. This is confirmed on three different deep learning tasks and popular models, namely, GNMT for machine translation, ResNet50 for image recognition, and Japser for acoustic speech recognition.
Achieving on-Mobile Real-Time Super-Resolution with Neural Architecture and Pruning Search
Aug 18, 2021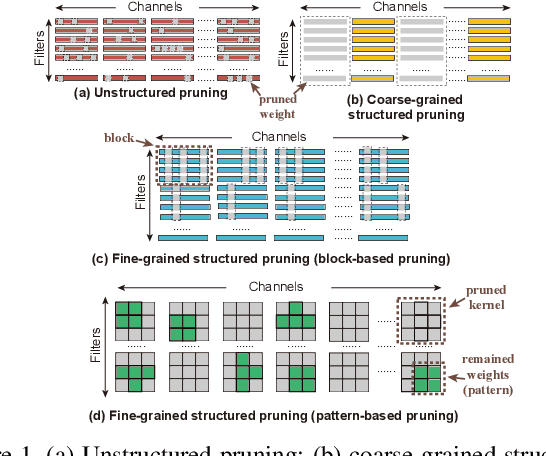
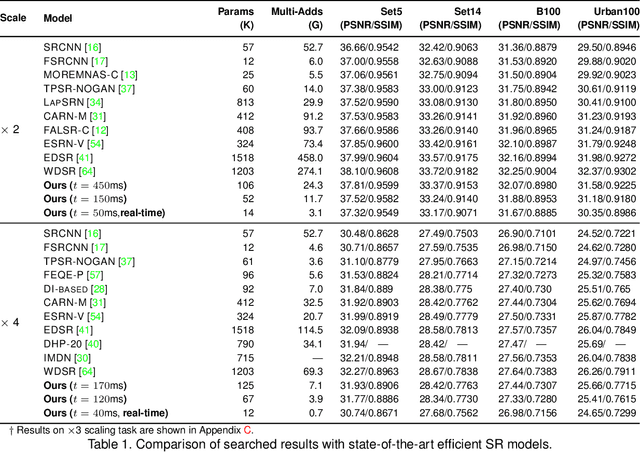
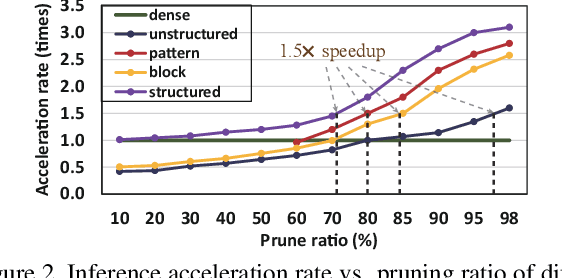
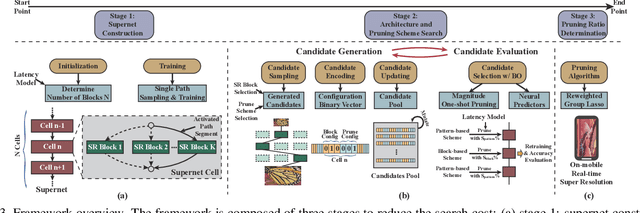
Though recent years have witnessed remarkable progress in single image super-resolution (SISR) tasks with the prosperous development of deep neural networks (DNNs), the deep learning methods are confronted with the computation and memory consumption issues in practice, especially for resource-limited platforms such as mobile devices. To overcome the challenge and facilitate the real-time deployment of SISR tasks on mobile, we combine neural architecture search with pruning search and propose an automatic search framework that derives sparse super-resolution (SR) models with high image quality while satisfying the real-time inference requirement. To decrease the search cost, we leverage the weight sharing strategy by introducing a supernet and decouple the search problem into three stages, including supernet construction, compiler-aware architecture and pruning search, and compiler-aware pruning ratio search. With the proposed framework, we are the first to achieve real-time SR inference (with only tens of milliseconds per frame) for implementing 720p resolution with competitive image quality (in terms of PSNR and SSIM) on mobile platforms (Samsung Galaxy S20).
Efficient Transformer-based Large Scale Language Representations using Hardware-friendly Block Structured Pruning
Oct 08, 2020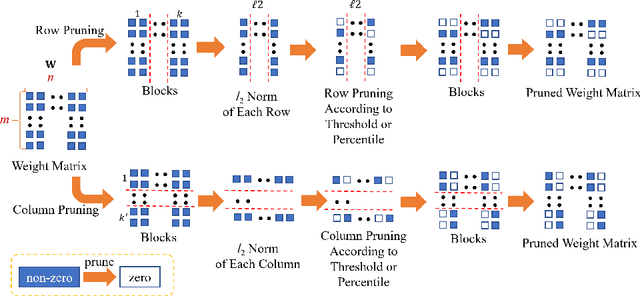
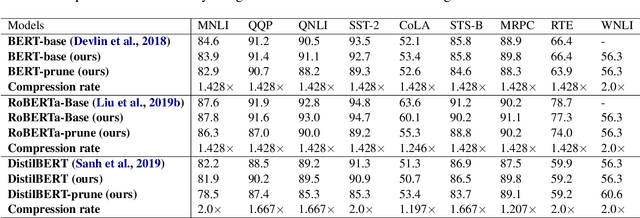
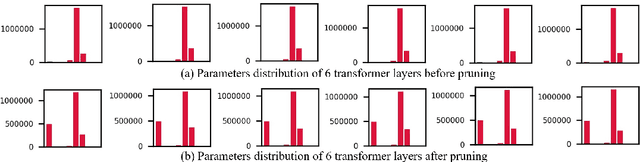
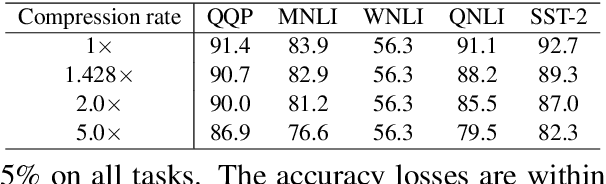
Pre-trained large-scale language models have increasingly demonstrated high accuracy on many natural language processing (NLP) tasks. However, the limited weight storage and computational speed on hardware platforms have impeded the popularity of pre-trained models, especially in the era of edge computing. In this work, we propose an efficient transformer-based large-scale language representation using hardware-friendly block structure pruning. We incorporate the reweighted group Lasso into block-structured pruning for optimization. Besides the significantly reduced weight storage and computation, the proposed approach achieves high compression rates. Experimental results on different models (BERT, RoBERTa, and DistilBERT) on the General Language Understanding Evaluation (GLUE) benchmark tasks show that we achieve up to 5.0x with zero or minor accuracy degradation on certain task(s). Our proposed method is also orthogonal to existing compact pre-trained language models such as DistilBERT using knowledge distillation, since a further 1.79x average compression rate can be achieved on top of DistilBERT with zero or minor accuracy degradation. It is suitable to deploy the final compressed model on resource-constrained edge devices.
Computation on Sparse Neural Networks: an Inspiration for Future Hardware
Apr 24, 2020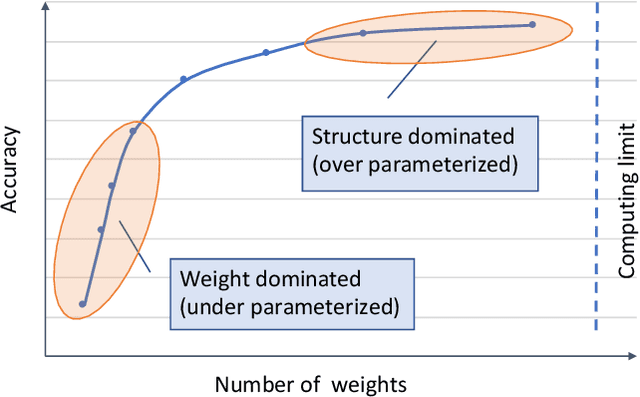
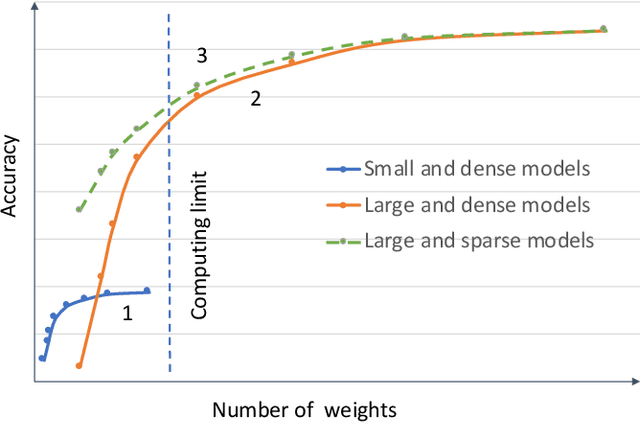
Neural network models are widely used in solving many challenging problems, such as computer vision, personalized recommendation, and natural language processing. Those models are very computationally intensive and reach the hardware limit of the existing server and IoT devices. Thus, finding better model architectures with much less amount of computation while maximally preserving the accuracy is a popular research topic. Among various mechanisms that aim to reduce the computation complexity, identifying the zero values in the model weights and in the activations to avoid computing them is a promising direction. In this paper, we summarize the current status of the research on the computation of sparse neural networks, from the perspective of the sparse algorithms, the software frameworks, and the hardware accelerations. We observe that the search for the sparse structure can be a general methodology for high-quality model explorations, in addition to a strategy for high-efficiency model execution. We discuss the model accuracy influenced by the number of weight parameters and the structure of the model. The corresponding models are called to be located in the weight dominated and structure dominated regions, respectively. We show that for practically complicated problems, it is more beneficial to search large and sparse models in the weight dominated region. In order to achieve the goal, new approaches are required to search for proper sparse structures, and new sparse training hardware needs to be developed to facilitate fast iterations of sparse models.
A Unified DNN Weight Compression Framework Using Reweighted Optimization Methods
Apr 12, 2020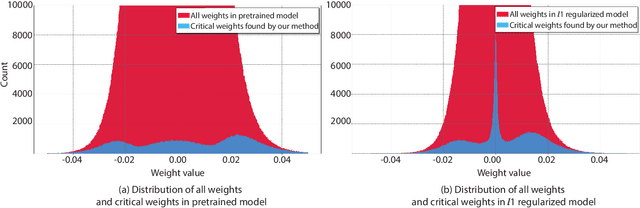

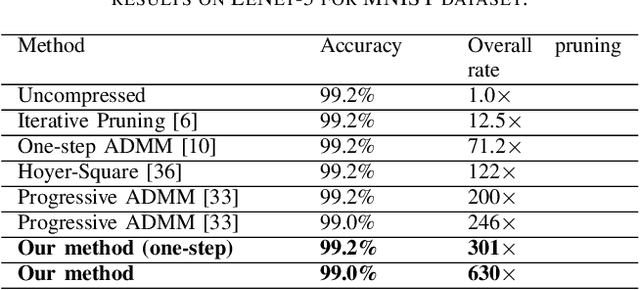
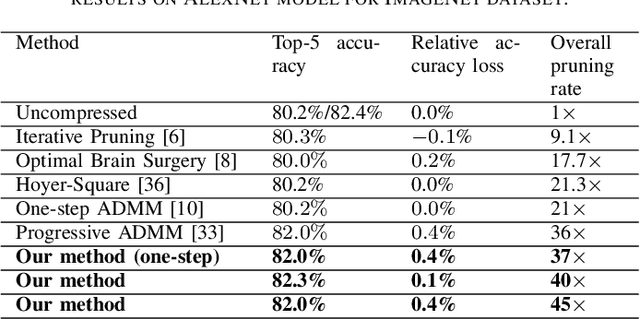
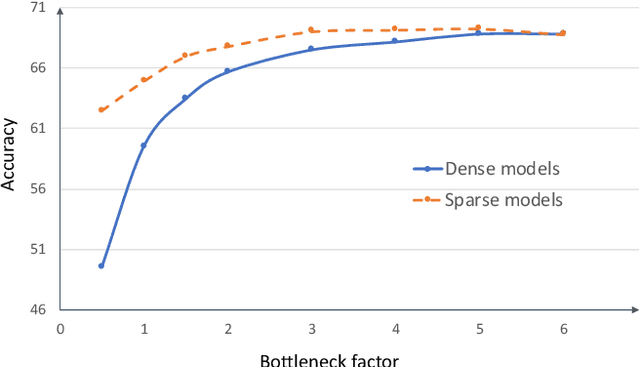
To address the large model size and intensive computation requirement of deep neural networks (DNNs), weight pruning techniques have been proposed and generally fall into two categories, i.e., static regularization-based pruning and dynamic regularization-based pruning. However, the former method currently suffers either complex workloads or accuracy degradation, while the latter one takes a long time to tune the parameters to achieve the desired pruning rate without accuracy loss. In this paper, we propose a unified DNN weight pruning framework with dynamically updated regularization terms bounded by the designated constraint, which can generate both non-structured sparsity and different kinds of structured sparsity. We also extend our method to an integrated framework for the combination of different DNN compression tasks.
BLK-REW: A Unified Block-based DNN Pruning Framework using Reweighted Regularization Method
Feb 22, 2020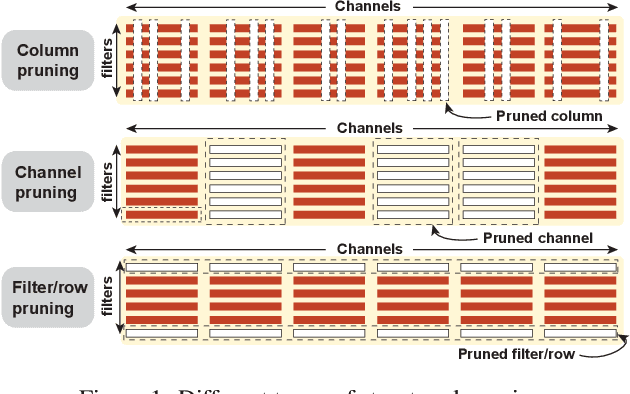
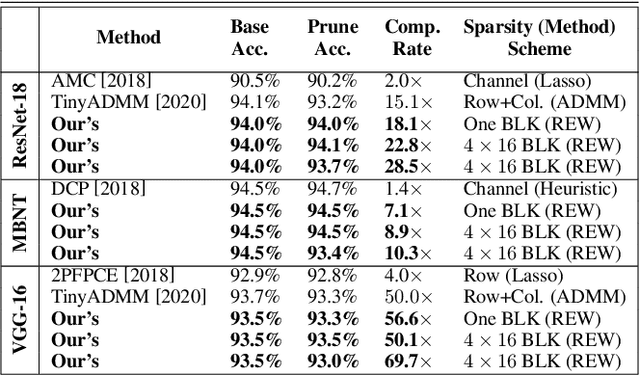
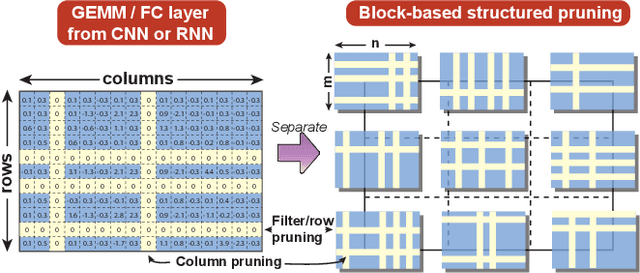
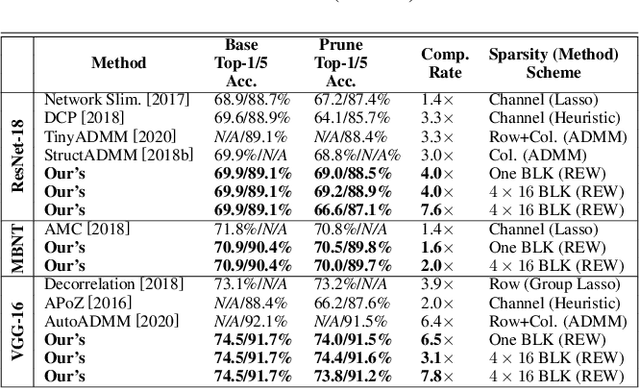
Accelerating DNN execution on various resource-limited computing platforms has been a long-standing problem. Prior works utilize l1-based group lasso or dynamic regularization such as ADMM to perform structured pruning on DNN models to leverage the parallel computing architectures. However, both of the pruning dimensions and pruning methods lack universality, which leads to degraded performance and limited applicability. To solve the problem, we propose a new block-based pruning framework that comprises a general and flexible structured pruning dimension as well as a powerful and efficient reweighted regularization method. Our framework is universal, which can be applied to both CNNs and RNNs, implying complete support for the two major kinds of computation-intensive layers (i.e., CONV and FC layers). To complete all aspects of the pruning-for-acceleration task, we also integrate compiler-based code optimization into our framework that can perform DNN inference in a real-time manner. To the best of our knowledge, it is the first time that the weight pruning framework achieves universal coverage for both CNNs and RNNs with real-time mobile acceleration and no accuracy compromise.
An Image Enhancing Pattern-based Sparsity for Real-time Inference on Mobile Devices
Feb 22, 2020
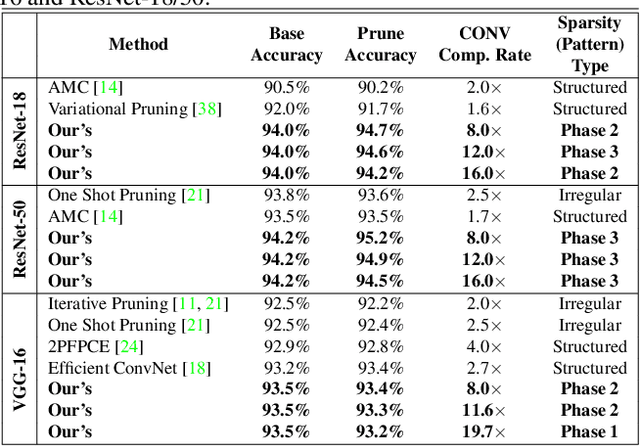
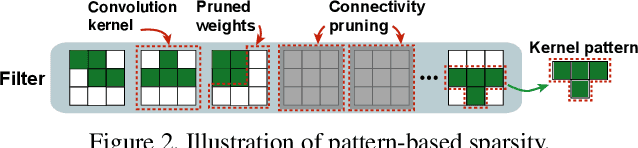
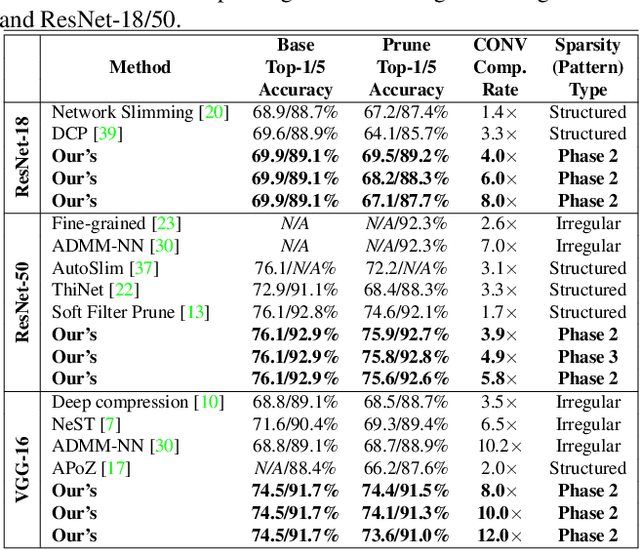
Weight pruning has been widely acknowledged as a straightforward and effective method to eliminate redundancy in Deep Neural Networks (DNN), thereby achieving acceleration on various platforms. However, most of the pruning techniques are essentially trade-offs between model accuracy and regularity which lead to impaired inference accuracy and limited on-device acceleration performance. To solve the problem, we introduce a new sparsity dimension, namely pattern-based sparsity that comprises pattern and connectivity sparsity, and becoming both highly accurate and hardware friendly. With carefully designed patterns, the proposed pruning unprecedentedly and consistently achieves accuracy enhancement and better feature extraction ability on different DNN structures and datasets, and our pattern-aware pruning framework also achieves pattern library extraction, pattern selection, pattern and connectivity pruning and weight training simultaneously. Our approach on the new pattern-based sparsity naturally fits into compiler optimization for highly efficient DNN execution on mobile platforms. To the best of our knowledge, it is the first time that mobile devices achieve real-time inference for the large-scale DNN models thanks to the unique spatial property of pattern-based sparsity and the help of the code generation capability of compilers.