 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy LLM Safety Guardrails Collapse After Fine-tuning: A Similarity Analysis Between Alignment and Fine-tuning Datasets
Jun 05, 2025Recent advancements in large language models (LLMs) have underscored their vulnerability to safety alignment jailbreaks, particularly when subjected to downstream fine-tuning. However, existing mitigation strategies primarily focus on reactively addressing jailbreak incidents after safety guardrails have been compromised, removing harmful gradients during fine-tuning, or continuously reinforcing safety alignment throughout fine-tuning. As such, they tend to overlook a critical upstream factor: the role of the original safety-alignment data. This paper therefore investigates the degradation of safety guardrails through the lens of representation similarity between upstream alignment datasets and downstream fine-tuning tasks. Our experiments demonstrate that high similarity between these datasets significantly weakens safety guardrails, making models more susceptible to jailbreaks. Conversely, low similarity between these two types of datasets yields substantially more robust models and thus reduces harmfulness score by up to 10.33%. By highlighting the importance of upstream dataset design in the building of durable safety guardrails and reducing real-world vulnerability to jailbreak attacks, these findings offer actionable insights for fine-tuning service providers.
Fostering Video Reasoning via Next-Event Prediction
May 28, 2025



Next-token prediction serves as the foundational learning task enabling reasoning in LLMs. But what should the learning task be when aiming to equip MLLMs with temporal reasoning capabilities over video inputs? Existing tasks such as video question answering often rely on annotations from humans or much stronger MLLMs, while video captioning tends to entangle temporal reasoning with spatial information. To address this gap, we propose next-event prediction (NEP), a learning task that harnesses future video segments as a rich, self-supervised signal to foster temporal reasoning. We segment each video into past and future frames: the MLLM takes the past frames as input and predicts a summary of events derived from the future frames, thereby encouraging the model to reason temporally in order to complete the task. To support this task, we curate V1-33K, a dataset comprising 33,000 automatically extracted video segments spanning diverse real-world scenarios. We further explore a range of video instruction-tuning strategies to study their effects on temporal reasoning. To evaluate progress, we introduce FutureBench to assess coherence in predicting unseen future events. Experiments validate that NEP offers a scalable and effective training paradigm for fostering temporal reasoning in MLLMs.
Reinforcing General Reasoning without Verifiers
May 27, 2025The recent paradigm shift towards training large language models (LLMs) using DeepSeek-R1-Zero-style reinforcement learning (RL) on verifiable rewards has led to impressive advancements in code and mathematical reasoning. However, this methodology is limited to tasks where rule-based answer verification is possible and does not naturally extend to real-world domains such as chemistry, healthcare, engineering, law, biology, business, and economics. Current practical workarounds use an additional LLM as a model-based verifier; however, this introduces issues such as reliance on a strong verifier LLM, susceptibility to reward hacking, and the practical burden of maintaining the verifier model in memory during training. To address this and extend DeepSeek-R1-Zero-style training to general reasoning domains, we propose a verifier-free method (VeriFree) that bypasses answer verification and instead uses RL to directly maximize the probability of generating the reference answer. We compare VeriFree with verifier-based methods and demonstrate that, in addition to its significant practical benefits and reduced compute requirements, VeriFree matches and even surpasses verifier-based methods on extensive evaluations across MMLU-Pro, GPQA, SuperGPQA, and math-related benchmarks. Moreover, we provide insights into this method from multiple perspectives: as an elegant integration of training both the policy and implicit verifier in a unified model, and as a variational optimization approach. Code is available at https://github.com/sail-sg/VeriFree.
Adversarial Attacks against Closed-Source MLLMs via Feature Optimal Alignment
May 27, 2025Multimodal large language models (MLLMs) remain vulnerable to transferable adversarial examples. While existing methods typically achieve targeted attacks by aligning global features-such as CLIP's [CLS] token-between adversarial and target samples, they often overlook the rich local information encoded in patch tokens. This leads to suboptimal alignment and limited transferability, particularly for closed-source models. To address this limitation, we propose a targeted transferable adversarial attack method based on feature optimal alignment, called FOA-Attack, to improve adversarial transfer capability. Specifically, at the global level, we introduce a global feature loss based on cosine similarity to align the coarse-grained features of adversarial samples with those of target samples. At the local level, given the rich local representations within Transformers, we leverage clustering techniques to extract compact local patterns to alleviate redundant local features. We then formulate local feature alignment between adversarial and target samples as an optimal transport (OT) problem and propose a local clustering optimal transport loss to refine fine-grained feature alignment. Additionally, we propose a dynamic ensemble model weighting strategy to adaptively balance the influence of multiple models during adversarial example generation, thereby further improving transferability. Extensive experiments across various models demonstrate the superiority of the proposed method, outperforming state-of-the-art methods, especially in transferring to closed-source MLLMs. The code is released at https://github.com/jiaxiaojunQAQ/FOA-Attack.
Lifelong Safety Alignment for Language Models
May 26, 2025



LLMs have made impressive progress, but their growing capabilities also expose them to highly flexible jailbreaking attacks designed to bypass safety alignment. While many existing defenses focus on known types of attacks, it is more critical to prepare LLMs for unseen attacks that may arise during deployment. To address this, we propose a lifelong safety alignment framework that enables LLMs to continuously adapt to new and evolving jailbreaking strategies. Our framework introduces a competitive setup between two components: a Meta-Attacker, trained to actively discover novel jailbreaking strategies, and a Defender, trained to resist them. To effectively warm up the Meta-Attacker, we first leverage the GPT-4o API to extract key insights from a large collection of jailbreak-related research papers. Through iterative training, the first iteration Meta-Attacker achieves a 73% attack success rate (ASR) on RR and a 57% transfer ASR on LAT using only single-turn attacks. Meanwhile, the Defender progressively improves its robustness and ultimately reduces the Meta-Attacker's success rate to just 7%, enabling safer and more reliable deployment of LLMs in open-ended environments. The code is available at https://github.com/sail-sg/LifelongSafetyAlignment.
QuickVideo: Real-Time Long Video Understanding with System Algorithm Co-Design
May 22, 2025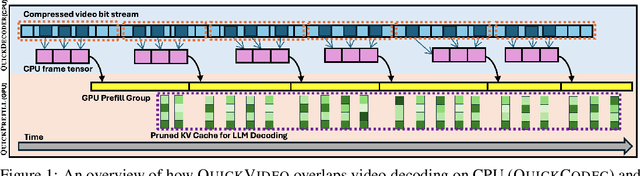
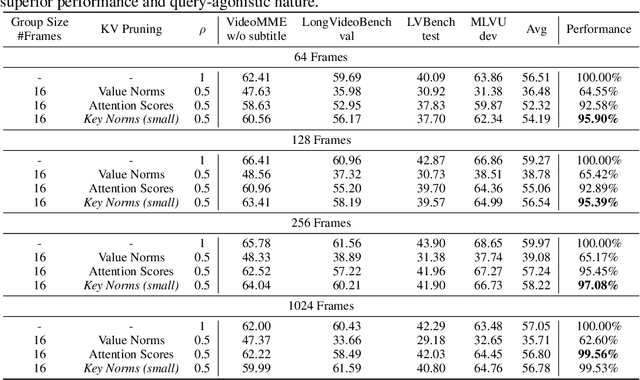
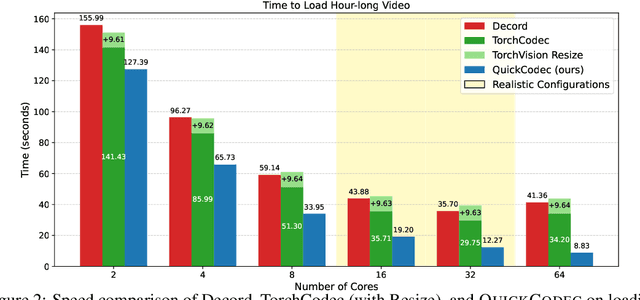
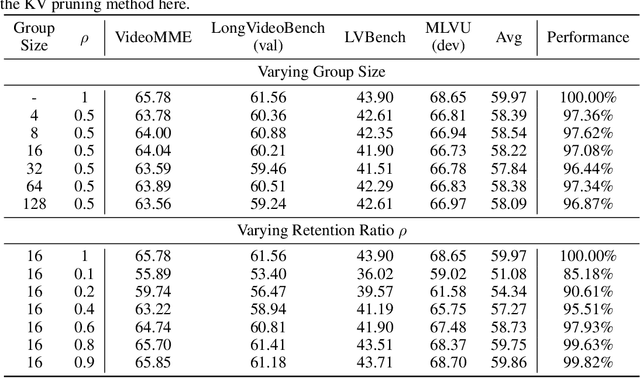
Long-video understanding has emerged as a crucial capability in real-world applications such as video surveillance, meeting summarization, educational lecture analysis, and sports broadcasting. However, it remains computationally prohibitive for VideoLLMs, primarily due to two bottlenecks: 1) sequential video decoding, the process of converting the raw bit stream to RGB frames can take up to a minute for hour-long video inputs, and 2) costly prefilling of up to several million tokens for LLM inference, resulting in high latency and memory use. To address these challenges, we propose QuickVideo, a system-algorithm co-design that substantially accelerates long-video understanding to support real-time downstream applications. It comprises three key innovations: QuickDecoder, a parallelized CPU-based video decoder that achieves 2-3 times speedup by splitting videos into keyframe-aligned intervals processed concurrently; QuickPrefill, a memory-efficient prefilling method using KV-cache pruning to support more frames with less GPU memory; and an overlapping scheme that overlaps CPU video decoding with GPU inference. Together, these components infernece time reduce by a minute on long video inputs, enabling scalable, high-quality video understanding even on limited hardware. Experiments show that QuickVideo generalizes across durations and sampling rates, making long video processing feasible in practice.
BanditSpec: Adaptive Speculative Decoding via Bandit Algorithms
May 21, 2025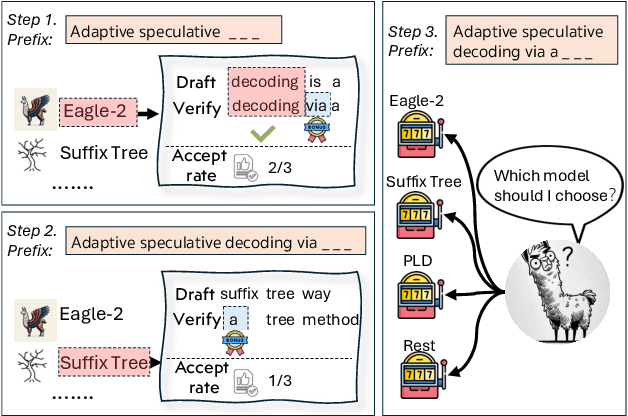
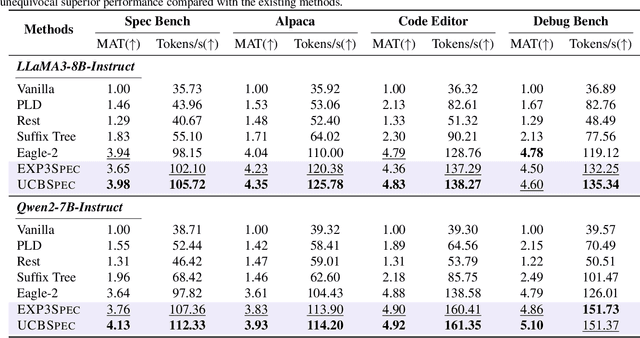
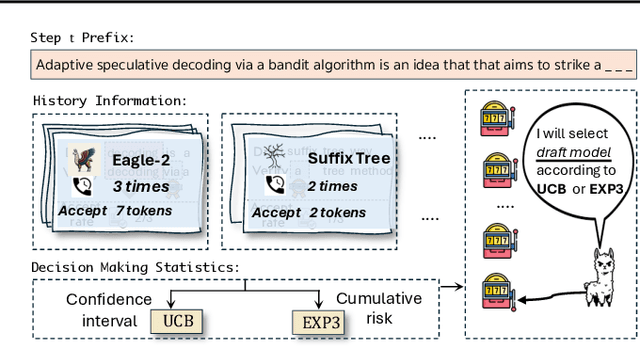
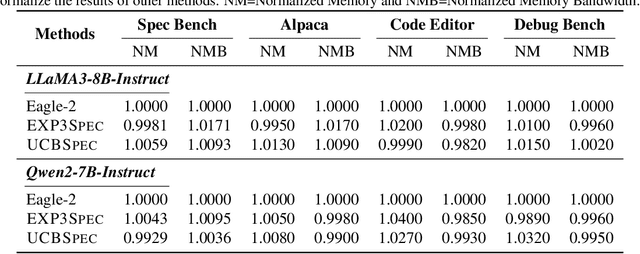
Speculative decoding has emerged as a popular method to accelerate the inference of Large Language Models (LLMs) while retaining their superior text generation performance. Previous methods either adopt a fixed speculative decoding configuration regardless of the prefix tokens, or train draft models in an offline or online manner to align them with the context. This paper proposes a training-free online learning framework to adaptively choose the configuration of the hyperparameters for speculative decoding as text is being generated. We first formulate this hyperparameter selection problem as a Multi-Armed Bandit problem and provide a general speculative decoding framework BanditSpec. Furthermore, two bandit-based hyperparameter selection algorithms, UCBSpec and EXP3Spec, are designed and analyzed in terms of a novel quantity, the stopping time regret. We upper bound this regret under both stochastic and adversarial reward settings. By deriving an information-theoretic impossibility result, it is shown that the regret performance of UCBSpec is optimal up to universal constants. Finally, extensive empirical experiments with LLaMA3 and Qwen2 demonstrate that our algorithms are effective compared to existing methods, and the throughput is close to the oracle best hyperparameter in simulated real-life LLM serving scenarios with diverse input prompts.
Optimizing Anytime Reasoning via Budget Relative Policy Optimization
May 19, 2025



Scaling test-time compute is crucial for enhancing the reasoning capabilities of large language models (LLMs). Existing approaches typically employ reinforcement learning (RL) to maximize a verifiable reward obtained at the end of reasoning traces. However, such methods optimize only the final performance under a large and fixed token budget, which hinders efficiency in both training and deployment. In this work, we present a novel framework, AnytimeReasoner, to optimize anytime reasoning performance, which aims to improve token efficiency and the flexibility of reasoning under varying token budget constraints. To achieve this, we truncate the complete thinking process to fit within sampled token budgets from a prior distribution, compelling the model to summarize the optimal answer for each truncated thinking for verification. This introduces verifiable dense rewards into the reasoning process, facilitating more effective credit assignment in RL optimization. We then optimize the thinking and summary policies in a decoupled manner to maximize the cumulative reward. Additionally, we introduce a novel variance reduction technique, Budget Relative Policy Optimization (BRPO), to enhance the robustness and efficiency of the learning process when reinforcing the thinking policy. Empirical results in mathematical reasoning tasks demonstrate that our method consistently outperforms GRPO across all thinking budgets under various prior distributions, enhancing both training and token efficiency.
FlowReasoner: Reinforcing Query-Level Meta-Agents
Apr 21, 2025



This paper proposes a query-level meta-agent named FlowReasoner to automate the design of query-level multi-agent systems, i.e., one system per user query. Our core idea is to incentivize a reasoning-based meta-agent via external execution feedback. Concretely, by distilling DeepSeek R1, we first endow the basic reasoning ability regarding the generation of multi-agent systems to FlowReasoner. Then, we further enhance it via reinforcement learning (RL) with external execution feedback. A multi-purpose reward is designed to guide the RL training from aspects of performance, complexity, and efficiency. In this manner, FlowReasoner is enabled to generate a personalized multi-agent system for each user query via deliberative reasoning. Experiments on both engineering and competition code benchmarks demonstrate the superiority of FlowReasoner. Remarkably, it surpasses o1-mini by 10.52% accuracy across three benchmarks. The code is available at https://github.com/sail-sg/FlowReasoner.
NoisyRollout: Reinforcing Visual Reasoning with Data Augmentation
Apr 17, 2025Recent advances in reinforcement learning (RL) have strengthened the reasoning capabilities of vision-language models (VLMs). However, enhancing policy exploration to more effectively scale test-time compute remains underexplored in VLMs. In addition, VLMs continue to struggle with imperfect visual perception, which in turn affects the subsequent reasoning process. To this end, we propose NoisyRollout, a simple yet effective RL approach that mixes trajectories from both clean and moderately distorted images to introduce targeted diversity in visual perception and the resulting reasoning patterns. Without additional training cost, NoisyRollout enhances the exploration capabilities of VLMs by incorporating a vision-oriented inductive bias. Furthermore, NoisyRollout employs a noise annealing schedule that gradually reduces distortion strength over training, ensuring benefit from noisy signals early while maintaining training stability and scalability in later stages. With just 2.1K training samples, NoisyRollout achieves state-of-the-art performance among open-source RL-tuned models on 5 out-of-domain benchmarks spanning both reasoning and perception tasks, while preserving comparable or even better in-domain performance.