 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy LLM Safety Guardrails Collapse After Fine-tuning: A Similarity Analysis Between Alignment and Fine-tuning Datasets
Jun 05, 2025Recent advancements in large language models (LLMs) have underscored their vulnerability to safety alignment jailbreaks, particularly when subjected to downstream fine-tuning. However, existing mitigation strategies primarily focus on reactively addressing jailbreak incidents after safety guardrails have been compromised, removing harmful gradients during fine-tuning, or continuously reinforcing safety alignment throughout fine-tuning. As such, they tend to overlook a critical upstream factor: the role of the original safety-alignment data. This paper therefore investigates the degradation of safety guardrails through the lens of representation similarity between upstream alignment datasets and downstream fine-tuning tasks. Our experiments demonstrate that high similarity between these datasets significantly weakens safety guardrails, making models more susceptible to jailbreaks. Conversely, low similarity between these two types of datasets yields substantially more robust models and thus reduces harmfulness score by up to 10.33%. By highlighting the importance of upstream dataset design in the building of durable safety guardrails and reducing real-world vulnerability to jailbreak attacks, these findings offer actionable insights for fine-tuning service providers.
Neurotoxin: Durable Backdoors in Federated Learning
Jun 12, 2022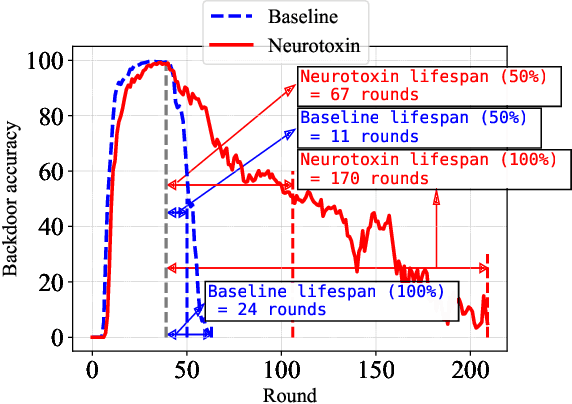

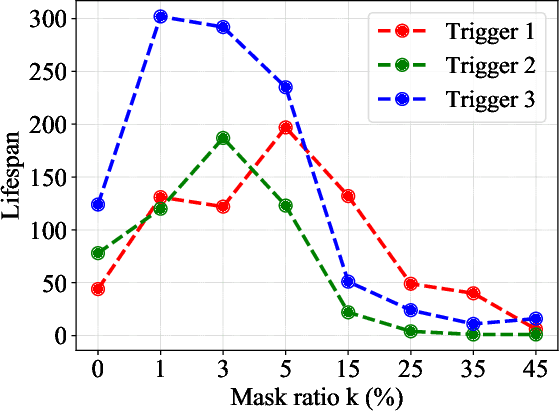
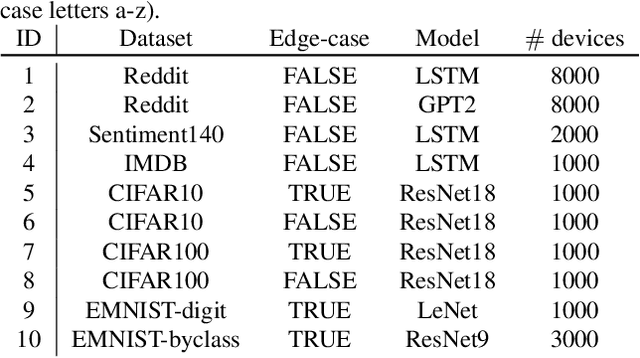
Due to their decentralized nature, federated learning (FL) systems have an inherent vulnerability during their training to adversarial backdoor attacks. In this type of attack, the goal of the attacker is to use poisoned updates to implant so-called backdoors into the learned model such that, at test time, the model's outputs can be fixed to a given target for certain inputs. (As a simple toy example, if a user types "people from New York" into a mobile keyboard app that uses a backdoored next word prediction model, then the model could autocomplete the sentence to "people from New York are rude"). Prior work has shown that backdoors can be inserted into FL models, but these backdoors are often not durable, i.e., they do not remain in the model after the attacker stops uploading poisoned updates. Thus, since training typically continues progressively in production FL systems, an inserted backdoor may not survive until deployment. Here, we propose Neurotoxin, a simple one-line modification to existing backdoor attacks that acts by attacking parameters that are changed less in magnitude during training. We conduct an exhaustive evaluation across ten natural language processing and computer vision tasks, and we find that we can double the durability of state of the art backdoors.