 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-Ground Tech Report: Advancing Perception in GUI Grounding
Jul 31, 2025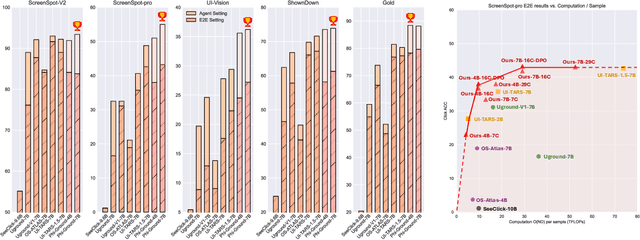
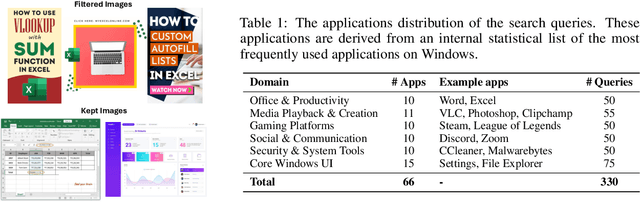
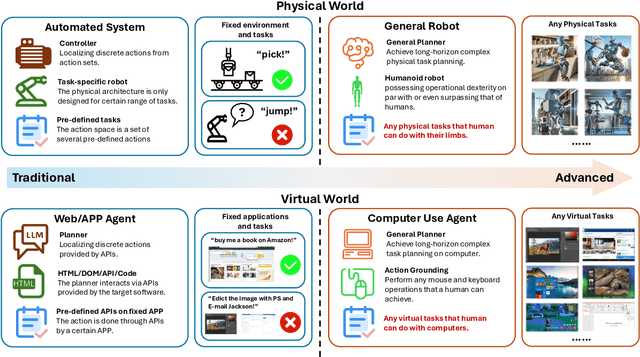

With the development of multimodal reasoning models, Computer Use Agents (CUAs), akin to Jarvis from \textit{"Iron Man"}, are becoming a reality. GUI grounding is a core component for CUAs to execute actual actions, similar to mechanical control in robotics, and it directly leads to the success or failure of the system. It determines actions such as clicking and typing, as well as related parameters like the coordinates for clicks. Current end-to-end grounding models still achieve less than 65\% accuracy on challenging benchmarks like ScreenSpot-pro and UI-Vision, indicating they are far from being ready for deployment. % , as a single misclick can result in unacceptable consequences. In this work, we conduct an empirical study on the training of grounding models, examining details from data collection to model training. Ultimately, we developed the \textbf{Phi-Ground} model family, which achieves state-of-the-art performance across all five grounding benchmarks for models under $10B$ parameters in agent settings. In the end-to-end model setting, our model still achieves SOTA results with scores of \textit{\textbf{43.2}} on ScreenSpot-pro and \textit{\textbf{27.2}} on UI-Vision. We believe that the various details discussed in this paper, along with our successes and failures, not only clarify the construction of grounding models but also benefit other perception tasks. Project homepage: \href{https://zhangmiaosen2000.github.io/Phi-Ground/}{https://zhangmiaosen2000.github.io/Phi-Ground/}
One-Step Flow Policy Mirror Descent
Jul 31, 2025Diffusion policies have achieved great success in online reinforcement learning (RL) due to their strong expressive capacity. However, the inference of diffusion policy models relies on a slow iterative sampling process, which limits their responsiveness. To overcome this limitation, we propose Flow Policy Mirror Descent (FPMD), an online RL algorithm that enables 1-step sampling during policy inference. Our approach exploits a theoretical connection between the distribution variance and the discretization error of single-step sampling in straight interpolation flow matching models, and requires no extra distillation or consistency training. We present two algorithm variants based on flow policy and MeanFlow policy parametrizations, respectively. Extensive empirical evaluations on MuJoCo benchmarks demonstrate that our algorithms show strong performance comparable to diffusion policy baselines while requiring hundreds of times fewer function evaluations during inference.
Symbolic identification of tensor equations in multidimensional physical fields
Jul 02, 2025Recently, data-driven methods have shown great promise for discovering governing equations from simulation or experimental data. However, most existing approaches are limited to scalar equations, with few capable of identifying tensor relationships. In this work, we propose a general data-driven framework for identifying tensor equations, referred to as Symbolic Identification of Tensor Equations (SITE). The core idea of SITE--representing tensor equations using a host-plasmid structure--is inspired by the multidimensional gene expression programming (M-GEP) approach. To improve the robustness of the evolutionary process, SITE adopts a genetic information retention strategy. Moreover, SITE introduces two key innovations beyond conventional evolutionary algorithms. First, it incorporates a dimensional homogeneity check to restrict the search space and eliminate physically invalid expressions. Second, it replaces traditional linear scaling with a tensor linear regression technique, greatly enhancing the efficiency of numerical coefficient optimization. We validate SITE using two benchmark scenarios, where it accurately recovers target equations from synthetic data, showing robustness to noise and small sample sizes. Furthermore, SITE is applied to identify constitutive relations directly from molecular simulation data, which are generated without reliance on macroscopic constitutive models. It adapts to both compressible and incompressible flow conditions and successfully identifies the corresponding macroscopic forms, highlighting its potential for data-driven discovery of tensor equation.
Scalable Complexity Control Facilitates Reasoning Ability of LLMs
May 29, 2025



The reasoning ability of large language models (LLMs) has been rapidly advancing in recent years, attracting interest in more fundamental approaches that can reliably enhance their generalizability. This work demonstrates that model complexity control, conveniently implementable by adjusting the initialization rate and weight decay coefficient, improves the scaling law of LLMs consistently over varying model sizes and data sizes. This gain is further illustrated by comparing the benchmark performance of 2.4B models pretrained on 1T tokens with different complexity hyperparameters. Instead of fixing the initialization std, we found that a constant initialization rate (the exponent of std) enables the scaling law to descend faster in both model and data sizes. These results indicate that complexity control is a promising direction for the continual advancement of LLMs.
MemOS: An Operating System for Memory-Augmented Generation (MAG) in Large Language Models
May 28, 2025



Large Language Models (LLMs) have emerged as foundational infrastructure in the pursuit of Artificial General Intelligence (AGI). Despite their remarkable capabilities in language perception and generation, current LLMs fundamentally lack a unified and structured architecture for handling memory. They primarily rely on parametric memory (knowledge encoded in model weights) and ephemeral activation memory (context-limited runtime states). While emerging methods like Retrieval-Augmented Generation (RAG) incorporate plaintext memory, they lack lifecycle management and multi-modal integration, limiting their capacity for long-term knowledge evolution. To address this, we introduce MemOS, a memory operating system designed for LLMs that, for the first time, elevates memory to a first-class operational resource. It builds unified mechanisms for representation, organization, and governance across three core memory types: parametric, activation, and plaintext. At its core is the MemCube, a standardized memory abstraction that enables tracking, fusion, and migration of heterogeneous memory, while offering structured, traceable access across tasks and contexts. MemOS establishes a memory-centric execution framework with strong controllability, adaptability, and evolvability. It fills a critical gap in current LLM infrastructure and lays the groundwork for continual adaptation, personalized intelligence, and cross-platform coordination in next-generation intelligent systems.
ProCrop: Learning Aesthetic Image Cropping from Professional Compositions
May 28, 2025Image cropping is crucial for enhancing the visual appeal and narrative impact of photographs, yet existing rule-based and data-driven approaches often lack diversity or require annotated training data. We introduce ProCrop, a retrieval-based method that leverages professional photography to guide cropping decisions. By fusing features from professional photographs with those of the query image, ProCrop learns from professional compositions, significantly boosting performance. Additionally, we present a large-scale dataset of 242K weakly-annotated images, generated by out-painting professional images and iteratively refining diverse crop proposals. This composition-aware dataset generation offers diverse high-quality crop proposals guided by aesthetic principles and becomes the largest publicly available dataset for image cropping. Extensive experiments show that ProCrop significantly outperforms existing methods in both supervised and weakly-supervised settings. Notably, when trained on the new dataset, our ProCrop surpasses previous weakly-supervised methods and even matches fully supervised approaches. Both the code and dataset will be made publicly available to advance research in image aesthetics and composition analysis.
WINA: Weight Informed Neuron Activation for Accelerating Large Language Model Inference
May 26, 2025The growing computational demands of large language models (LLMs) make efficient inference and activation strategies increasingly critical. While recent approaches, such as Mixture-of-Experts (MoE), leverage selective activation but require specialized training, training-free sparse activation methods offer broader applicability and superior resource efficiency through their plug-and-play design. However, many existing methods rely solely on hidden state magnitudes to determine activation, resulting in high approximation errors and suboptimal inference accuracy. To address these limitations, we propose WINA (Weight Informed Neuron Activation), a novel, simple, and training-free sparse activation framework that jointly considers hidden state magnitudes and the column-wise $\ell_2$-norms of weight matrices. We show that this leads to a sparsification strategy that obtains optimal approximation error bounds with theoretical guarantees tighter than existing techniques. Empirically, WINA also outperforms state-of-the-art methods (e.g., TEAL) by up to $2.94\%$ in average performance at the same sparsity levels, across a diverse set of LLM architectures and datasets. These results position WINA as a new performance frontier for training-free sparse activation in LLM inference, advancing training-free sparse activation methods and setting a robust baseline for efficient inference. The source code is available at https://github.com/microsoft/wina.
Why 1 + 1 < 1 in Visual Token Pruning: Beyond Naive Integration via Multi-Objective Balanced Covering
May 15, 2025Existing visual token pruning methods target prompt alignment and visual preservation with static strategies, overlooking the varying relative importance of these objectives across tasks, which leads to inconsistent performance. To address this, we derive the first closed-form error bound for visual token pruning based on the Hausdorff distance, uniformly characterizing the contributions of both objectives. Moreover, leveraging $\epsilon$-covering theory, we reveal an intrinsic trade-off between these objectives and quantify their optimal attainment levels under a fixed budget. To practically handle this trade-off, we propose Multi-Objective Balanced Covering (MoB), which reformulates visual token pruning as a bi-objective covering problem. In this framework, the attainment trade-off reduces to budget allocation via greedy radius trading. MoB offers a provable performance bound and linear scalability with respect to the number of input visual tokens, enabling adaptation to challenging pruning scenarios. Extensive experiments show that MoB preserves 96.4% of performance for LLaVA-1.5-7B using only 11.1% of the original visual tokens and accelerates LLaVA-Next-7B by 1.3-1.5$\times$ with negligible performance loss. Additionally, evaluations on Qwen2-VL and Video-LLaVA confirm that MoB integrates seamlessly into advanced MLLMs and diverse vision-language tasks.
Endo-CLIP: Progressive Self-Supervised Pre-training on Raw Colonoscopy Records
May 14, 2025



Pre-training on image-text colonoscopy records offers substantial potential for improving endoscopic image analysis, but faces challenges including non-informative background images, complex medical terminology, and ambiguous multi-lesion descriptions. We introduce Endo-CLIP, a novel self-supervised framework that enhances Contrastive Language-Image Pre-training (CLIP) for this domain. Endo-CLIP's three-stage framework--cleansing, attunement, and unification--addresses these challenges by (1) removing background frames, (2) leveraging large language models to extract clinical attributes for fine-grained contrastive learning, and (3) employing patient-level cross-attention to resolve multi-polyp ambiguities. Extensive experiments demonstrate that Endo-CLIP significantly outperforms state-of-the-art pre-training methods in zero-shot and few-shot polyp detection and classification, paving the way for more accurate and clinically relevant endoscopic analysis.
On the Robustness of GUI Grounding Models Against Image Attacks
Apr 07, 2025Graphical User Interface (GUI) grounding models are crucial for enabling intelligent agents to understand and interact with complex visual interfaces. However, these models face significant robustness challenges in real-world scenarios due to natural noise and adversarial perturbations, and their robustness remains underexplored. In this study, we systematically evaluate the robustness of state-of-the-art GUI grounding models, such as UGround, under three conditions: natural noise, untargeted adversarial attacks, and targeted adversarial attacks. Our experiments, which were conducted across a wide range of GUI environments, including mobile, desktop, and web interfaces, have clearly demonstrated that GUI grounding models exhibit a high degree of sensitivity to adversarial perturbations and low-resolution conditions. These findings provide valuable insights into the vulnerabilities of GUI grounding models and establish a strong benchmark for future research aimed at enhancing their robustness in practical applications. Our code is available at https://github.com/ZZZhr-1/Robust_GUI_Grounding.