 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiMPO: Measure Matching for Online Diffusion Reinforcement Learning
Mar 10, 2026A commonly used family of RL algorithms for diffusion policies conducts softmax reweighting over the behavior policy, which usually induces an over-greedy policy and fails to leverage feedback from negative samples. In this work, we introduce Signed Measure Policy Optimization (SiMPO), a simple and unified framework that generalizes reweighting scheme in diffusion RL with general monotonic functions. SiMPO revisits diffusion RL via a two-stage measure matching lens. First, we construct a virtual target policy by $f$-divergence regularized policy optimization, where we can relax the non-negativity constraint to allow for a signed target measure. Second, we use this signed measure to guide diffusion or flow models through reweighted matching. This formulation offers two key advantages: a) it generalizes to arbitrary monotonically increasing weighting functions; and b) it provides a principled justification and practical guidance for negative reweighting. Furthermore, we provide geometric interpretations to illustrate how negative reweighting actively repels the policy from suboptimal actions. Extensive empirical evaluations demonstrate that SiMPO achieves superior performance by leveraging these flexible weighting schemes, and we provide practical guidelines for selecting reweighting methods tailored to the reward landscape.
Offline Imitation Learning upon Arbitrary Demonstrations by Pre-Training Dynamics Representations
Aug 20, 2025Limited data has become a major bottleneck in scaling up offline imitation learning (IL). In this paper, we propose enhancing IL performance under limited expert data by introducing a pre-training stage that learns dynamics representations, derived from factorizations of the transition dynamics. We first theoretically justify that the optimal decision variable of offline IL lies in the representation space, significantly reducing the parameters to learn in the downstream IL. Moreover, the dynamics representations can be learned from arbitrary data collected with the same dynamics, allowing the reuse of massive non-expert data and mitigating the limited data issues. We present a tractable loss function inspired by noise contrastive estimation to learn the dynamics representations at the pre-training stage. Experiments on MuJoCo demonstrate that our proposed algorithm can mimic expert policies with as few as a single trajectory. Experiments on real quadrupeds show that we can leverage pre-trained dynamics representations from simulator data to learn to walk from a few real-world demonstrations.
One-Step Flow Policy Mirror Descent
Jul 31, 2025Diffusion policies have achieved great success in online reinforcement learning (RL) due to their strong expressive capacity. However, the inference of diffusion policy models relies on a slow iterative sampling process, which limits their responsiveness. To overcome this limitation, we propose Flow Policy Mirror Descent (FPMD), an online RL algorithm that enables 1-step sampling during policy inference. Our approach exploits a theoretical connection between the distribution variance and the discretization error of single-step sampling in straight interpolation flow matching models, and requires no extra distillation or consistency training. We present two algorithm variants based on flow policy and MeanFlow policy parametrizations, respectively. Extensive empirical evaluations on MuJoCo benchmarks demonstrate that our algorithms show strong performance comparable to diffusion policy baselines while requiring hundreds of times fewer function evaluations during inference.
Distributed Thompson sampling under constrained communication
Oct 21, 2024

In Bayesian optimization, a black-box function is maximized via the use of a surrogate model. We apply distributed Thompson sampling, using a Gaussian process as a surrogate model, to approach the multi-agent Bayesian optimization problem. In our distributed Thompson sampling implementation, each agent receives sampled points from neighbors, where the communication network is encoded in a graph; each agent utilizes a Gaussian process to model the objective function. We demonstrate a theoretical bound on Bayesian Simple Regret, where the bound depends on the size of the largest complete subgraph of the communication graph. Unlike in batch Bayesian optimization, this bound is applicable in cases where the communication graph amongst agents is constrained. When compared to sequential Thompson sampling, our bound guarantees faster convergence with respect to time as long as there is a fully connected subgraph of at least two agents. We confirm the efficacy of our algorithm with numerical simulations on traditional optimization test functions, illustrating the significance of graph connectivity on improving regret convergence.
Autonomous Robotic Ultrasound System for Liver Follow-up Diagnosis: Pilot Phantom Study
May 09, 2024



The paper introduces a novel autonomous robot ultrasound (US) system targeting liver follow-up scans for outpatients in local communities. Given a computed tomography (CT) image with specific target regions of interest, the proposed system carries out the autonomous follow-up scan in three steps: (i) initial robot contact to surface, (ii) coordinate mapping between CT image and robot, and (iii) target US scan. Utilizing 3D US-CT registration and deep learning-based segmentation networks, we can achieve precise imaging of 3D hepatic veins, facilitating accurate coordinate mapping between CT and the robot. This enables the automatic localization of follow-up targets within the CT image, allowing the robot to navigate precisely to the target's surface. Evaluation of the ultrasound phantom confirms the quality of the US-CT registration and shows the robot reliably locates the targets in repeated trials. The proposed framework holds the potential to significantly reduce time and costs for healthcare providers, clinicians, and follow-up patients, thereby addressing the increasing healthcare burden associated with chronic disease in local communities.
Efficient Duple Perturbation Robustness in Low-rank MDPs
Apr 11, 2024



The pursuit of robustness has recently been a popular topic in reinforcement learning (RL) research, yet the existing methods generally suffer from efficiency issues that obstruct their real-world implementation. In this paper, we introduce duple perturbation robustness, i.e. perturbation on both the feature and factor vectors for low-rank Markov decision processes (MDPs), via a novel characterization of $(\xi,\eta)$-ambiguity sets. The novel robust MDP formulation is compatible with the function representation view, and therefore, is naturally applicable to practical RL problems with large or even continuous state-action spaces. Meanwhile, it also gives rise to a provably efficient and practical algorithm with theoretical convergence rate guarantee. Examples are designed to justify the new robustness concept, and algorithmic efficiency is supported by both theoretical bounds and numerical simulations.
Skill Transfer and Discovery for Sim-to-Real Learning: A Representation-Based Viewpoint
Apr 07, 2024We study sim-to-real skill transfer and discovery in the context of robotics control using representation learning. We draw inspiration from spectral decomposition of Markov decision processes. The spectral decomposition brings about representation that can linearly represent the state-action value function induced by any policies, thus can be regarded as skills. The skill representations are transferable across arbitrary tasks with the same transition dynamics. Moreover, to handle the sim-to-real gap in the dynamics, we propose a skill discovery algorithm that learns new skills caused by the sim-to-real gap from real-world data. We promote the discovery of new skills by enforcing orthogonal constraints between the skills to learn and the skills from simulators, and then synthesize the policy using the enlarged skill sets. We demonstrate our methodology by transferring quadrotor controllers from simulators to Crazyflie 2.1 quadrotors. We show that we can learn the skill representations from a single simulator task and transfer these to multiple different real-world tasks including hovering, taking off, landing and trajectory tracking. Our skill discovery approach helps narrow the sim-to-real gap and improve the real-world controller performance by up to 30.2%.
Gaussian Max-Value Entropy Search for Multi-Agent Bayesian Optimization
Mar 10, 2023



We study the multi-agent Bayesian optimization (BO) problem, where multiple agents maximize a black-box function via iterative queries. We focus on Entropy Search (ES), a sample-efficient BO algorithm that selects queries to maximize the mutual information about the maximum of the black-box function. One of the main challenges of ES is that calculating the mutual information requires computationally-costly approximation techniques. For multi-agent BO problems, the computational cost of ES is exponential in the number of agents. To address this challenge, we propose the Gaussian Max-value Entropy Search, a multi-agent BO algorithm with favorable sample and computational efficiency. The key to our idea is to use a normal distribution to approximate the function maximum and calculate its mutual information accordingly. The resulting approximation allows queries to be cast as the solution of a closed-form optimization problem which, in turn, can be solved via a modified gradient ascent algorithm and scaled to a large number of agents. We demonstrate the effectiveness of Gaussian max-value Entropy Search through numerical experiments on standard test functions and real-robot experiments on the source-seeking problem. Results show that the proposed algorithm outperforms the multi-agent BO baselines in the numerical experiments and can stably seek the source with a limited number of noisy observations on real robots.
Safe Model-Based Reinforcement Learning with an Uncertainty-Aware Reachability Certificate
Oct 14, 2022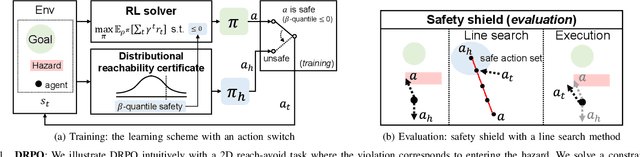
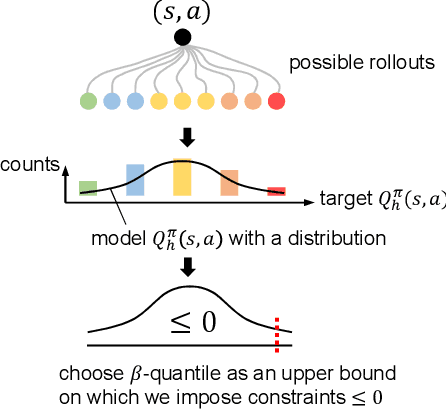
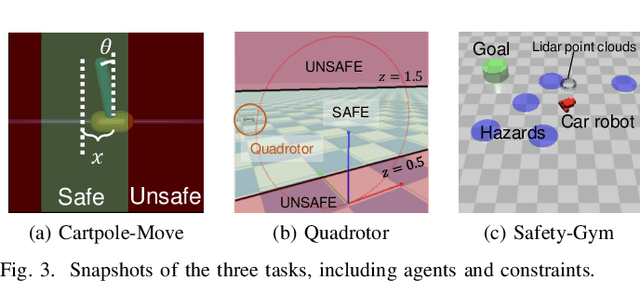
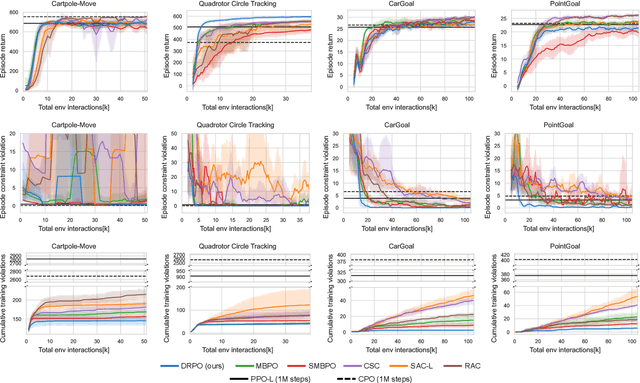
Safe reinforcement learning (RL) that solves constraint-satisfactory policies provides a promising way to the broader safety-critical applications of RL in real-world problems such as robotics. Among all safe RL approaches, model-based methods reduce training time violations further due to their high sample efficiency. However, lacking safety robustness against the model uncertainties remains an issue in safe model-based RL, especially in training time safety. In this paper, we propose a distributional reachability certificate (DRC) and its Bellman equation to address model uncertainties and characterize robust persistently safe states. Furthermore, we build a safe RL framework to resolve constraints required by the DRC and its corresponding shield policy. We also devise a line search method to maintain safety and reach higher returns simultaneously while leveraging the shield policy. Comprehensive experiments on classical benchmarks such as constrained tracking and navigation indicate that the proposed algorithm achieves comparable returns with much fewer constraint violations during training.
Synthesize Efficient Safety Certificates for Learning-Based Safe Control using Magnitude Regularization
Sep 23, 2022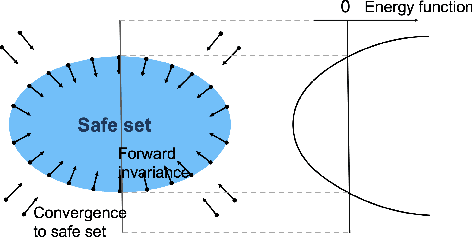
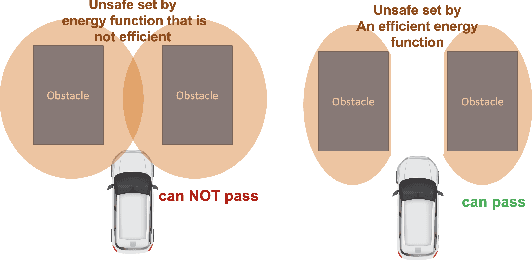
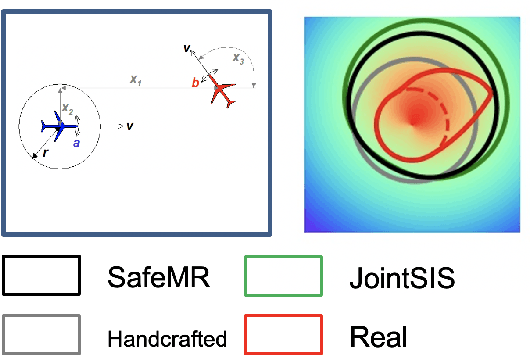

Energy-function-based safety certificates can provide provable safety guarantees for the safe control tasks of complex robotic systems. However, all recent studies about learning-based energy function synthesis only consider the feasibility, which might cause over-conservativeness and result in less efficient controllers. In this work, we proposed the magnitude regularization technique to improve the efficiency of safe controllers by reducing the conservativeness inside the energy function while keeping the promising provable safety guarantees. Specifically, we quantify the conservativeness by the magnitude of the energy function, and we reduce the conservativeness by adding a magnitude regularization term to the synthesis loss. We propose the SafeMR algorithm that uses reinforcement learning (RL) for the synthesis to unify the learning processes of safe controllers and energy functions. Experimental results show that the proposed method does reduce the conservativeness of the energy functions and outperforms the baselines in terms of the controller efficiency while guaranteeing safety.