 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovering Human Action Space for Computer Use: Data Synthesis and Benchmark
May 12, 2026Computer-use agents (CUAs) automate on-screen work, as illustrated by GPT-5.4 and Claude. Yet their reliability on complex, low-frequency interactions is still poor, limiting user trust. Our analysis of failure cases from advanced models suggests a long-tail pattern in GUI operations, where a relatively small fraction of complex and diverse interactions accounts for a disproportionate share of task failures. We hypothesize that this issue largely stems from the scarcity of data for complex interactions. To address this problem, we propose a new benchmark CUActSpot for evaluating models' capabilities on complex interactions across five modalities: GUI, text, table, canvas, and natural image, as well as a variety of actions (click, drag, draw, etc.), covering a broader range of interaction types than prior click-centric benchmarks that focus mainly on GUI widgets. We also design a renderer-based data-synthesis pipeline: scenes are automatically generated for each modality, screenshots and element coordinates are recorded, and an LLM produces matching instructions and action traces. After training on this corpus, our Phi-Ground-Any-4B outperforms open-source models with fewer than 32B parameters. We will release our benchmark, data, code, and models at https://github.com/microsoft/Phi-Ground.git
Towards On-Policy SFT: Distribution Discriminant Theory and its Applications in LLM Training
Feb 12, 2026Supervised fine-tuning (SFT) is computationally efficient but often yields inferior generalization compared to reinforcement learning (RL). This gap is primarily driven by RL's use of on-policy data. We propose a framework to bridge this chasm by enabling On-Policy SFT. We first present \textbf{\textit{Distribution Discriminant Theory (DDT)}}, which explains and quantifies the alignment between data and the model-induced distribution. Leveraging DDT, we introduce two complementary techniques: (i) \textbf{\textit{In-Distribution Finetuning (IDFT)}}, a loss-level method to enhance generalization ability of SFT, and (ii) \textbf{\textit{Hinted Decoding}}, a data-level technique that can re-align the training corpus to the model's distribution. Extensive experiments demonstrate that our framework achieves generalization performance on par with prominent offline RL algorithms, including DPO and SimPO, while maintaining the efficiency of an SFT pipeline. The proposed framework thus offers a practical alternative in domains where RL is infeasible. We open-source the code here: https://github.com/zhangmiaosen2000/Towards-On-Policy-SFT
RE-TRAC: REcursive TRAjectory Compression for Deep Search Agents
Feb 02, 2026LLM-based deep research agents are largely built on the ReAct framework. This linear design makes it difficult to revisit earlier states, branch into alternative search directions, or maintain global awareness under long contexts, often leading to local optima, redundant exploration, and inefficient search. We propose Re-TRAC, an agentic framework that performs cross-trajectory exploration by generating a structured state representation after each trajectory to summarize evidence, uncertainties, failures, and future plans, and conditioning subsequent trajectories on this state representation. This enables iterative reflection and globally informed planning, reframing research as a progressive process. Empirical results show that Re-TRAC consistently outperforms ReAct by 15-20% on BrowseComp with frontier LLMs. For smaller models, we introduce Re-TRAC-aware supervised fine-tuning, achieving state-of-the-art performance at comparable scales. Notably, Re-TRAC shows a monotonic reduction in tool calls and token usage across rounds, indicating progressively targeted exploration driven by cross-trajectory reflection rather than redundant search.
Phi-Ground Tech Report: Advancing Perception in GUI Grounding
Jul 31, 2025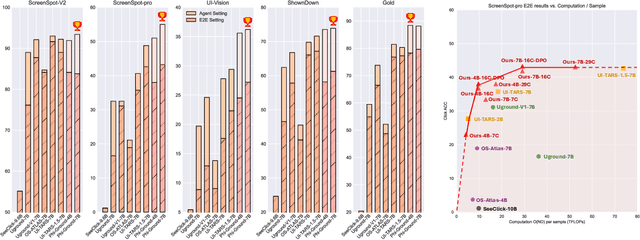
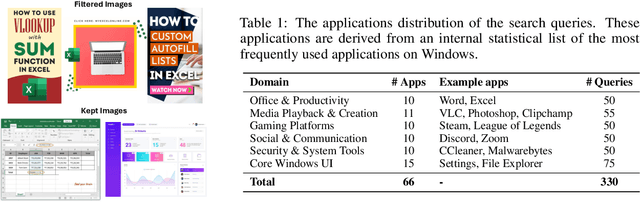
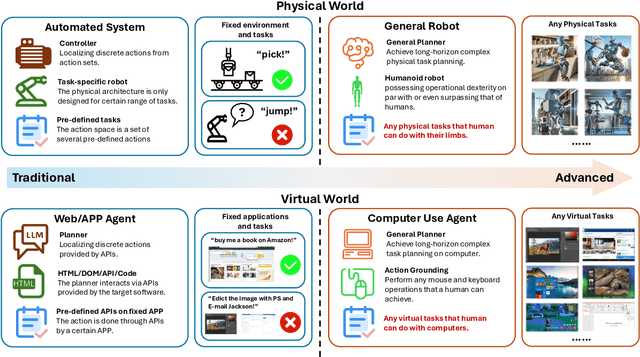

With the development of multimodal reasoning models, Computer Use Agents (CUAs), akin to Jarvis from \textit{"Iron Man"}, are becoming a reality. GUI grounding is a core component for CUAs to execute actual actions, similar to mechanical control in robotics, and it directly leads to the success or failure of the system. It determines actions such as clicking and typing, as well as related parameters like the coordinates for clicks. Current end-to-end grounding models still achieve less than 65\% accuracy on challenging benchmarks like ScreenSpot-pro and UI-Vision, indicating they are far from being ready for deployment. % , as a single misclick can result in unacceptable consequences. In this work, we conduct an empirical study on the training of grounding models, examining details from data collection to model training. Ultimately, we developed the \textbf{Phi-Ground} model family, which achieves state-of-the-art performance across all five grounding benchmarks for models under $10B$ parameters in agent settings. In the end-to-end model setting, our model still achieves SOTA results with scores of \textit{\textbf{43.2}} on ScreenSpot-pro and \textit{\textbf{27.2}} on UI-Vision. We believe that the various details discussed in this paper, along with our successes and failures, not only clarify the construction of grounding models but also benefit other perception tasks. Project homepage: \href{https://zhangmiaosen2000.github.io/Phi-Ground/}{https://zhangmiaosen2000.github.io/Phi-Ground/}
LMM-R1: Empowering 3B LMMs with Strong Reasoning Abilities Through Two-Stage Rule-Based RL
Mar 11, 2025Enhancing reasoning in Large Multimodal Models (LMMs) faces unique challenges from the complex interplay between visual perception and logical reasoning, particularly in compact 3B-parameter architectures where architectural constraints limit reasoning capacity and modality alignment. While rule-based reinforcement learning (RL) excels in text-only domains, its multimodal extension confronts two critical barriers: (1) data limitations due to ambiguous answers and scarce complex reasoning examples, and (2) degraded foundational reasoning induced by multimodal pretraining. To address these challenges, we propose \textbf{LMM-R1}, a two-stage framework adapting rule-based RL for multimodal reasoning through \textbf{Foundational Reasoning Enhancement (FRE)} followed by \textbf{Multimodal Generalization Training (MGT)}. The FRE stage first strengthens reasoning abilities using text-only data with rule-based RL, then the MGT stage generalizes these reasoning capabilities to multimodal domains. Experiments on Qwen2.5-VL-Instruct-3B demonstrate that LMM-R1 achieves 4.83\% and 4.5\% average improvements over baselines in multimodal and text-only benchmarks, respectively, with a 3.63\% gain in complex Football Game tasks. These results validate that text-based reasoning enhancement enables effective multimodal generalization, offering a data-efficient paradigm that bypasses costly high-quality multimodal training data.
MageBench: Bridging Large Multimodal Models to Agents
Dec 05, 2024LMMs have shown impressive visual understanding capabilities, with the potential to be applied in agents, which demand strong reasoning and planning abilities. Nevertheless, existing benchmarks mostly assess their reasoning abilities in language part, where the chain-of-thought is entirely composed of text.We consider the scenario where visual signals are continuously updated and required along the decision making process. Such vision-in-the-chain reasoning paradigm is more aligned with the needs of multimodal agents, while being rarely evaluated. In this paper, we introduce MageBench, a reasoning capability oriented multimodal agent benchmark that, while having light-weight environments, poses significant reasoning challenges and holds substantial practical value. This benchmark currently includes three types of environments: WebUI, Sokoban, and Football, comprising a total of 483 different scenarios. It thoroughly validates the agent's knowledge and engineering capabilities, visual intelligence, and interaction skills. The results show that only a few product-level models are better than random acting, and all of them are far inferior to human-level. More specifically, we found current models severely lack the ability to modify their planning based on visual feedback, as well as visual imagination, interleaved image-text long context handling, and other abilities. We hope that our work will provide optimization directions for LMM from the perspective of being an agent. We release our code and data at https://github.com/microsoft/MageBench.
ScalingFilter: Assessing Data Quality through Inverse Utilization of Scaling Laws
Aug 15, 2024



High-quality data is crucial for the pre-training performance of large language models. Unfortunately, existing quality filtering methods rely on a known high-quality dataset as reference, which can introduce potential bias and compromise diversity. In this paper, we propose ScalingFilter, a novel approach that evaluates text quality based on the perplexity difference between two language models trained on the same data, thereby eliminating the influence of the reference dataset in the filtering process. An theoretical analysis shows that ScalingFilter is equivalent to an inverse utilization of scaling laws. Through training models with 1.3B parameters on the same data source processed by various quality filters, we find ScalingFilter can improve zero-shot performance of pre-trained models in downstream tasks. To assess the bias introduced by quality filtering, we introduce semantic diversity, a metric of utilizing text embedding models for semantic representations. Extensive experiments reveal that semantic diversity is a reliable indicator of dataset diversity, and ScalingFilter achieves an optimal balance between downstream performance and semantic diversity.
Aligning Vision Models with Human Aesthetics in Retrieval: Benchmarks and Algorithms
Jun 13, 2024



Modern vision models are trained on very large noisy datasets. While these models acquire strong capabilities, they may not follow the user's intent to output the desired results in certain aspects, e.g., visual aesthetic, preferred style, and responsibility. In this paper, we target the realm of visual aesthetics and aim to align vision models with human aesthetic standards in a retrieval system. Advanced retrieval systems usually adopt a cascade of aesthetic models as re-rankers or filters, which are limited to low-level features like saturation and perform poorly when stylistic, cultural or knowledge contexts are involved. We find that utilizing the reasoning ability of large language models (LLMs) to rephrase the search query and extend the aesthetic expectations can make up for this shortcoming. Based on the above findings, we propose a preference-based reinforcement learning method that fine-tunes the vision models to distill the knowledge from both LLMs reasoning and the aesthetic models to better align the vision models with human aesthetics. Meanwhile, with rare benchmarks designed for evaluating retrieval systems, we leverage large multi-modality model (LMM) to evaluate the aesthetic performance with their strong abilities. As aesthetic assessment is one of the most subjective tasks, to validate the robustness of LMM, we further propose a novel dataset named HPIR to benchmark the alignment with human aesthetics. Experiments demonstrate that our method significantly enhances the aesthetic behaviors of the vision models, under several metrics. We believe the proposed algorithm can be a general practice for aligning vision models with human values.
Transformer as Linear Expansion of Learngene
Dec 20, 2023



We propose expanding the shared Transformer module to produce and initialize Transformers of varying depths, enabling adaptation to diverse resource constraints. Drawing an analogy to genetic expansibility, we term such module as learngene. To identify the expansion mechanism, we delve into the relationship between the layer's position and its corresponding weight value, and find that linear function appropriately approximates this relationship. Building on this insight, we present Transformer as Linear Expansion of learnGene (TLEG), a novel approach for flexibly producing and initializing Transformers of diverse depths. Specifically, to learn learngene, we firstly construct an auxiliary Transformer linearly expanded from learngene, after which we train it through employing soft distillation. Subsequently, we can produce and initialize Transformers of varying depths via linearly expanding the well-trained learngene, thereby supporting diverse downstream scenarios. Extensive experiments on ImageNet-1K demonstrate that TLEG achieves comparable or better performance in contrast to many individual models trained from scratch, while reducing around 2x training cost. When transferring to several downstream classification datasets, TLEG surpasses existing initialization methods by a large margin (e.g., +6.87% on iNat 2019 and +7.66% on CIFAR-100). Under the situation where we need to produce models of varying depths adapting for different resource constraints, TLEG achieves comparable results while reducing around 19x parameters stored to initialize these models and around 5x pre-training costs, in contrast to the pre-training and fine-tuning approach. When transferring a fixed set of parameters to initialize different models, TLEG presents better flexibility and competitive performance while reducing around 2.9x parameters stored to initialize, compared to the pre-training approach.
FP8-LM: Training FP8 Large Language Models
Oct 27, 2023



In this paper, we explore FP8 low-bit data formats for efficient training of large language models (LLMs). Our key insight is that most variables, such as gradients and optimizer states, in LLM training can employ low-precision data formats without compromising model accuracy and requiring no changes to hyper-parameters. Specifically, we propose a new FP8 automatic mixed-precision framework for training LLMs. This framework offers three levels of FP8 utilization to streamline mixed-precision and distributed parallel training for LLMs. It gradually incorporates 8-bit gradients, optimizer states, and distributed learning in an incremental manner. Experiment results show that, during the training of GPT-175B model on H100 GPU platform, our FP8 mixed-precision training framework not only achieved a remarkable 42% reduction in real memory usage but also ran 64% faster than the widely adopted BF16 framework (i.e., Megatron-LM), surpassing the speed of Nvidia Transformer Engine by 17%. This largely reduces the training costs for large foundation models. Furthermore, our FP8 mixed-precision training methodology is generic. It can be seamlessly applied to other tasks such as LLM instruction tuning and reinforcement learning with human feedback, offering savings in fine-tuning expenses. Our FP8 low-precision training framework is open-sourced at {https://github.com/Azure/MS-AMP}{aka.ms/MS.AMP}.