 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Reasoning Efficiently via Relaxed On-Policy Distillation
Mar 11, 2026On-policy distillation is pivotal for transferring reasoning capabilities to capacity-constrained models, yet remains prone to instability and negative transfer. We show that on-policy distillation can be interpreted, both theoretically and empirically, as a form of policy optimization, where the teacher-student log-likelihood ratio acts as a token reward. From this insight, we introduce REOPOLD (Relaxed On-Policy Distillation) a framework that stabilizes optimization by relaxing the strict imitation constraints of standard on-policy distillation. Specifically, REOPOLD temperately and selectively leverages rewards from the teacher through mixture-based reward clipping, entropy-based token-level dynamic sampling, and a unified exploration-to-refinement training strategy. Empirically, REOPOLD surpasses its baselines with superior sample efficiency during training and enhanced test-time scaling at inference, across mathematical, visual, and agentic tool-use reasoning tasks. Specifically, REOPOLD outperforms recent RL approaches achieving 6.7~12x greater sample efficiency and enables a 7B student to match a 32B teacher in visual reasoning with a ~3.32x inference speedup.
CUA-Skill: Develop Skills for Computer Using Agent
Jan 28, 2026Computer-Using Agents (CUAs) aim to autonomously operate computer systems to complete real-world tasks. However, existing agentic systems remain difficult to scale and lag behind human performance. A key limitation is the absence of reusable and structured skill abstractions that capture how humans interact with graphical user interfaces and how to leverage these skills. We introduce CUA-Skill, a computer-using agentic skill base that encodes human computer-use knowledge as skills coupled with parameterized execution and composition graphs. CUA-Skill is a large-scale library of carefully engineered skills spanning common Windows applications, serving as a practical infrastructure and tool substrate for scalable, reliable agent development. Built upon this skill base, we construct CUA-Skill Agent, an end-to-end computer-using agent that supports dynamic skill retrieval, argument instantiation, and memory-aware failure recovery. Our results demonstrate that CUA-Skill substantially improves execution success rates and robustness on challenging end-to-end agent benchmarks, establishing a strong foundation for future computer-using agent development. On WindowsAgentArena, CUA-Skill Agent achieves state-of-the-art 57.5% (best of three) successful rate while being significantly more efficient than prior and concurrent approaches. The project page is available at https://microsoft.github.io/cua_skill/.
StableQAT: Stable Quantization-Aware Training at Ultra-Low Bitwidths
Jan 27, 2026Quantization-aware training (QAT) is essential for deploying large models under strict memory and latency constraints, yet achieving stable and robust optimization at ultra-low bitwidths remains challenging. Common approaches based on the straight-through estimator (STE) or soft quantizers often suffer from gradient mismatch, instability, or high computational overhead. As such, we propose StableQAT, a unified and efficient QAT framework that stabilizes training in ultra low-bit settings via a novel, lightweight, and theoretically grounded surrogate for backpropagation derived from a discrete Fourier analysis of the rounding operator. StableQAT strictly generalizes STE as the latter arises as a special case of our more expressive surrogate family, yielding smooth, bounded, and inexpensive gradients that improve QAT training performance and stability across various hyperparameter choices. In experiments, StableQAT exhibits stable and efficient QAT at 2-4 bit regimes, demonstrating improved training stability, robustness, and superior performance with negligible training overhead against standard QAT techniques. Our code is available at https://github.com/microsoft/StableQAT.
Revisiting Multi-Agent Debate as Test-Time Scaling: A Systematic Study of Conditional Effectiveness
May 29, 2025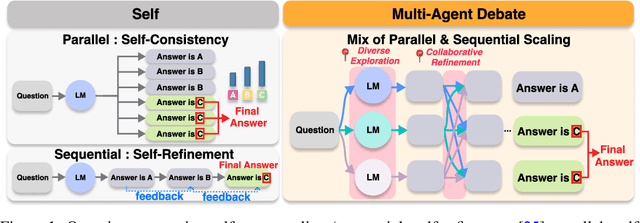
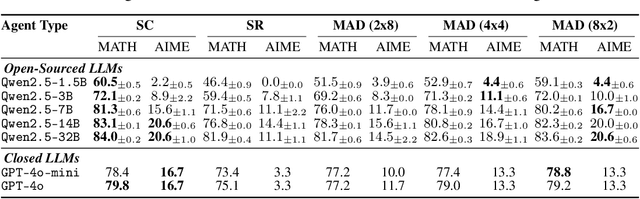
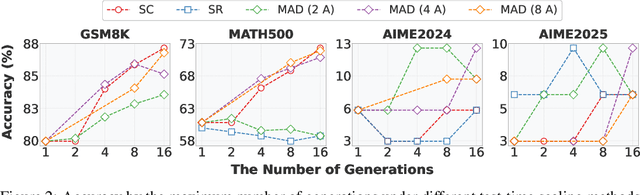
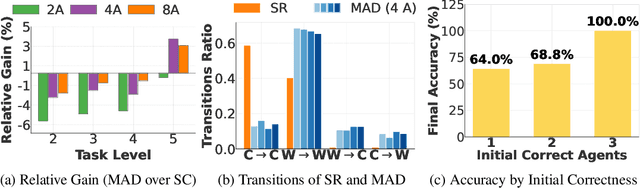
The remarkable growth in large language model (LLM) capabilities has spurred exploration into multi-agent systems, with debate frameworks emerging as a promising avenue for enhanced problem-solving. These multi-agent debate (MAD) approaches, where agents collaboratively present, critique, and refine arguments, potentially offer improved reasoning, robustness, and diverse perspectives over monolithic models. Despite prior studies leveraging MAD, a systematic understanding of its effectiveness compared to self-agent methods, particularly under varying conditions, remains elusive. This paper seeks to fill this gap by conceptualizing MAD as a test-time computational scaling technique, distinguished by collaborative refinement and diverse exploration capabilities. We conduct a comprehensive empirical investigation comparing MAD with strong self-agent test-time scaling baselines on mathematical reasoning and safety-related tasks. Our study systematically examines the influence of task difficulty, model scale, and agent diversity on MAD's performance. Key findings reveal that, for mathematical reasoning, MAD offers limited advantages over self-agent scaling but becomes more effective with increased problem difficulty and decreased model capability, while agent diversity shows little benefit. Conversely, for safety tasks, MAD's collaborative refinement can increase vulnerability, but incorporating diverse agent configurations facilitates a gradual reduction in attack success through the collaborative refinement process. We believe our findings provide critical guidance for the future development of more effective and strategically deployed MAD systems.
WINA: Weight Informed Neuron Activation for Accelerating Large Language Model Inference
May 26, 2025The growing computational demands of large language models (LLMs) make efficient inference and activation strategies increasingly critical. While recent approaches, such as Mixture-of-Experts (MoE), leverage selective activation but require specialized training, training-free sparse activation methods offer broader applicability and superior resource efficiency through their plug-and-play design. However, many existing methods rely solely on hidden state magnitudes to determine activation, resulting in high approximation errors and suboptimal inference accuracy. To address these limitations, we propose WINA (Weight Informed Neuron Activation), a novel, simple, and training-free sparse activation framework that jointly considers hidden state magnitudes and the column-wise $\ell_2$-norms of weight matrices. We show that this leads to a sparsification strategy that obtains optimal approximation error bounds with theoretical guarantees tighter than existing techniques. Empirically, WINA also outperforms state-of-the-art methods (e.g., TEAL) by up to $2.94\%$ in average performance at the same sparsity levels, across a diverse set of LLM architectures and datasets. These results position WINA as a new performance frontier for training-free sparse activation in LLM inference, advancing training-free sparse activation methods and setting a robust baseline for efficient inference. The source code is available at https://github.com/microsoft/wina.
Flex-Judge: Think Once, Judge Anywhere
May 24, 2025Human-generated reward signals are critical for aligning generative models with human preferences, guiding both training and inference-time evaluations. While large language models (LLMs) employed as proxy evaluators, i.e., LLM-as-a-Judge, significantly reduce the costs associated with manual annotations, they typically require extensive modality-specific training data and fail to generalize well across diverse multimodal tasks. In this paper, we propose Flex-Judge, a reasoning-guided multimodal judge model that leverages minimal textual reasoning data to robustly generalize across multiple modalities and evaluation formats. Our core intuition is that structured textual reasoning explanations inherently encode generalizable decision-making patterns, enabling an effective transfer to multimodal judgments, e.g., with images or videos. Empirical results demonstrate that Flex-Judge, despite being trained on significantly fewer text data, achieves competitive or superior performance compared to state-of-the-art commercial APIs and extensively trained multimodal evaluators. Notably, Flex-Judge presents broad impact in modalities like molecule, where comprehensive evaluation benchmarks are scarce, underscoring its practical value in resource-constrained domains. Our framework highlights reasoning-based text supervision as a powerful, cost-effective alternative to traditional annotation-intensive approaches, substantially advancing scalable multimodal model-as-a-judge.
Bayesian Principles Improve Prompt Learning In Vision-Language Models
Apr 19, 2025Prompt learning is a popular fine-tuning method for vision-language models due to its efficiency. It requires a small number of additional learnable parameters while significantly enhancing performance on target tasks. However, most existing methods suffer from overfitting to fine-tuning data, yielding poor generalizability. To address this, we propose a new training objective function based on a Bayesian learning principle to balance adaptability and generalizability. We derive a prior over the logits, where the mean function is parameterized by the pre-trained model, while the posterior corresponds to the fine-tuned model. This objective establishes a balance by allowing the fine-tuned model to adapt to downstream tasks while remaining close to the pre-trained model.
When Debate Fails: Bias Reinforcement in Large Language Models
Mar 21, 2025



Large Language Models $($LLMs$)$ solve complex problems using training-free methods like prompt engineering and in-context learning, yet ensuring reasoning correctness remains challenging. While self-correction methods such as self-consistency and self-refinement aim to improve reliability, they often reinforce biases due to the lack of effective feedback mechanisms. Multi-Agent Debate $($MAD$)$ has emerged as an alternative, but we identify two key limitations: bias reinforcement, where debate amplifies model biases instead of correcting them, and lack of perspective diversity, as all agents share the same model and reasoning patterns, limiting true debate effectiveness. To systematically evaluate these issues, we introduce $\textit{MetaNIM Arena}$, a benchmark designed to assess LLMs in adversarial strategic decision-making, where dynamic interactions influence optimal decisions. To overcome MAD's limitations, we propose $\textbf{DReaMAD}$ $($$\textbf{D}$iverse $\textbf{Rea}$soning via $\textbf{M}$ulti-$\textbf{A}$gent $\textbf{D}$ebate with Refined Prompt$)$, a novel framework that $(1)$ refines LLM's strategic prior knowledge to improve reasoning quality and $(2)$ promotes diverse viewpoints within a single model by systematically modifying prompts, reducing bias. Empirical results show that $\textbf{DReaMAD}$ significantly improves decision accuracy, reasoning diversity, and bias mitigation across multiple strategic tasks, establishing it as a more effective approach for LLM-based decision-making.
DistiLLM-2: A Contrastive Approach Boosts the Distillation of LLMs
Mar 10, 2025



Despite the success of distillation in large language models (LLMs), most prior work applies identical loss functions to both teacher- and student-generated data. These strategies overlook the synergy between loss formulations and data types, leading to a suboptimal performance boost in student models. To address this, we propose DistiLLM-2, a contrastive approach that simultaneously increases the likelihood of teacher responses and decreases that of student responses by harnessing this synergy. Our extensive experiments show that DistiLLM-2 not only builds high-performing student models across a wide range of tasks, including instruction-following and code generation, but also supports diverse applications, such as preference alignment and vision-language extensions. These findings highlight the potential of a contrastive approach to enhance the efficacy of LLM distillation by effectively aligning teacher and student models across varied data types.
SeRA: Self-Reviewing and Alignment of Large Language Models using Implicit Reward Margins
Oct 12, 2024Direct alignment algorithms (DAAs), such as direct preference optimization (DPO), have become popular alternatives for Reinforcement Learning from Human Feedback (RLHF) due to their simplicity, efficiency, and stability. However, the preferences used in DAAs are usually collected before the alignment training begins and remain unchanged (off-policy). This can lead to two problems where the policy model (1) picks up on spurious correlations in the dataset (as opposed to learning the intended alignment expressed in the human preference labels), and (2) overfits to feedback on off-policy trajectories that have less likelihood of being generated by an updated policy model. To address these issues, we introduce Self-Reviewing and Alignment (SeRA), a cost-efficient and effective method that can be readily combined with existing DAAs. SeRA comprises of two components: (1) sample selection using implicit reward margins, which helps alleviate over-fitting to some undesired features, and (2) preference bootstrapping using implicit rewards to augment preference data with updated policy models in a cost-efficient manner. Extensive experimentation, including some on instruction-following tasks, demonstrate the effectiveness and generality of SeRA in training LLMs on offline preference datasets with DAAs.