 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemPrivacy: Privacy-Preserving Personalized Memory Management for Edge-Cloud Agents
May 10, 2026As LLM-powered agents are increasingly deployed in edge-cloud environments, personalized memory has become a key enabler of long-term adaptation and user-centric interaction. However, cloud-assisted memory management exposes sensitive user information, while existing privacy protection methods typically rely on aggressive masking that removes task-relevant semantics and consequently degrades memory utility and personalization quality. To address this challenge, We propose MemPrivacy, which identifies privacy-sensitive spans on edge devices, replaces them with semantically structured type-aware placeholders for cloud-side memory processing, and restores the original values locally when needed. By decoupling privacy protection from semantic destruction, MemPrivacy minimizes sensitive data exposure while retaining the information required for effective memory formation and retrieval. We also construct MemPrivacy-Bench for systematic evaluation, a dataset covering 200 users and over 52k privacy instances, and introduce a four-level privacy taxonomy for configurable protection policies. Experiments show that MemPrivacy achieves strong performance in privacy information extraction, substantially surpassing strong general-purpose models such as GPT-5.2 and Gemini-3.1-Pro, while also reducing inference latency. Across multiple widely used memory systems, MemPrivacy limits utility loss to within 1.6%, outperforming baseline masking strategies. Overall, MemPrivacy offers an effective balance between privacy protection and personalized memory utility for edge-cloud agents, enabling secure, practical, and user-transparent deployment.
Writer-R1: Enhancing Generative Writing in LLMs via Memory-augmented Replay Policy Optimization
Mar 16, 2026As a typical open-ended generation task, creative writing lacks verifiable reference answers, which has long constrained reward modeling and automatic evaluation due to high human annotation costs, evaluative bias, and coarse feedback signals. To address these challenges, this paper first designs a multi-agent collaborative workflow based on Grounded Theory, performing dimensional decomposition and hierarchical induction of the problem to dynamically produce interpretable and reusable fine-grained criteria. Furthermore, we propose the Memory-augmented Replay Policy Optimization (MRPO) algorithm: on the one hand, without additional training, MRPO guides models to engage in self-reflection based on dynamic criteria, enabling controlled iterative improvement; on the other hand, we adopt the training paradigm that combines supervised fine-tuning with reinforcement learning to convert evaluation criteria into reward signals, achieving end-to-end optimization. Experimental results demonstrate that the automatically constructed criteria achieve performance gains comparable to human annotations. Writer-R1-4B models trained with this approach outperform baselines across multiple creative writing tasks and surpass some 100B+ parameter open-source models.
QChunker: Learning Question-Aware Text Chunking for Domain RAG via Multi-Agent Debate
Mar 12, 2026The effectiveness upper bound of retrieval-augmented generation (RAG) is fundamentally constrained by the semantic integrity and information granularity of text chunks in its knowledge base. To address these challenges, this paper proposes QChunker, which restructures the RAG paradigm from retrieval-augmentation to understanding-retrieval-augmentation. Firstly, QChunker models the text chunking as a composite task of text segmentation and knowledge completion to ensure the logical coherence and integrity of text chunks. Drawing inspiration from Hal Gregersen's "Questions Are the Answer" theory, we design a multi-agent debate framework comprising four specialized components: a question outline generator, text segmenter, integrity reviewer, and knowledge completer. This framework operates on the principle that questions serve as catalysts for profound insights. Through this pipeline, we successfully construct a high-quality dataset of 45K entries and transfer this capability to small language models. Additionally, to handle long evaluation chains and low efficiency in existing chunking evaluation methods, which overly rely on downstream QA tasks, we introduce a novel direct evaluation metric, ChunkScore. Both theoretical and experimental validations demonstrate that ChunkScore can directly and efficiently discriminate the quality of text chunks. Furthermore, during the text segmentation phase, we utilize document outlines for multi-path sampling to generate multiple candidate chunks and select the optimal solution employing ChunkScore. Extensive experimental results across four heterogeneous domains exhibit that QChunker effectively resolves aforementioned issues by providing RAG with more logically coherent and information-rich text chunks.
MemEmo: Evaluating Emotion in Memory Systems of Agents
Feb 27, 2026Memory systems address the challenge of context loss in Large Language Model during prolonged interactions. However, compared to human cognition, the efficacy of these systems in processing emotion-related information remains inconclusive. To address this gap, we propose an emotion-enhanced memory evaluation benchmark to assess the performance of mainstream and state-of-the-art memory systems in handling affective information. We developed the \textbf{H}uman-\textbf{L}ike \textbf{M}emory \textbf{E}motion (\textbf{HLME}) dataset, which evaluates memory systems across three dimensions: emotional information extraction, emotional memory updating, and emotional memory question answering. Experimental results indicate that none of the evaluated systems achieve robust performance across all three tasks. Our findings provide an objective perspective on the current deficiencies of memory systems in processing emotional memories and suggest a new trajectory for future research and system optimization.
Inside Out: Evolving User-Centric Core Memory Trees for Long-Term Personalized Dialogue Systems
Jan 08, 2026Existing long-term personalized dialogue systems struggle to reconcile unbounded interaction streams with finite context constraints, often succumbing to memory noise accumulation, reasoning degradation, and persona inconsistency. To address these challenges, this paper proposes Inside Out, a framework that utilizes a globally maintained PersonaTree as the carrier of long-term user profiling. By constraining the trunk with an initial schema and updating the branches and leaves, PersonaTree enables controllable growth, achieving memory compression while preserving consistency. Moreover, we train a lightweight MemListener via reinforcement learning with process-based rewards to produce structured, executable, and interpretable {ADD, UPDATE, DELETE, NO_OP} operations, thereby supporting the dynamic evolution of the personalized tree. During response generation, PersonaTree is directly leveraged to enhance outputs in latency-sensitive scenarios; when users require more details, the agentic mode is triggered to introduce details on-demand under the constraints of the PersonaTree. Experiments show that PersonaTree outperforms full-text concatenation and various personalized memory systems in suppressing contextual noise and maintaining persona consistency. Notably, the small MemListener model achieves memory-operation decision performance comparable to, or even surpassing, powerful reasoning models such as DeepSeek-R1-0528 and Gemini-3-Pro.
TAdaRAG: Task Adaptive Retrieval-Augmented Generation via On-the-Fly Knowledge Graph Construction
Nov 16, 2025Retrieval-Augmented Generation (RAG) improves large language models by retrieving external knowledge, often truncated into smaller chunks due to the input context window, which leads to information loss, resulting in response hallucinations and broken reasoning chains. Moreover, traditional RAG retrieves unstructured knowledge, introducing irrelevant details that hinder accurate reasoning. To address these issues, we propose TAdaRAG, a novel RAG framework for on-the-fly task-adaptive knowledge graph construction from external sources. Specifically, we design an intent-driven routing mechanism to a domain-specific extraction template, followed by supervised fine-tuning and a reinforcement learning-based implicit extraction mechanism, ensuring concise, coherent, and non-redundant knowledge integration. Evaluations on six public benchmarks and a real-world business benchmark (NowNewsQA) across three backbone models demonstrate that TAdaRAG outperforms existing methods across diverse domains and long-text tasks, highlighting its strong generalization and practical effectiveness.
MoM: Mixtures of Scenario-Aware Document Memories for Retrieval-Augmented Generation Systems
Oct 16, 2025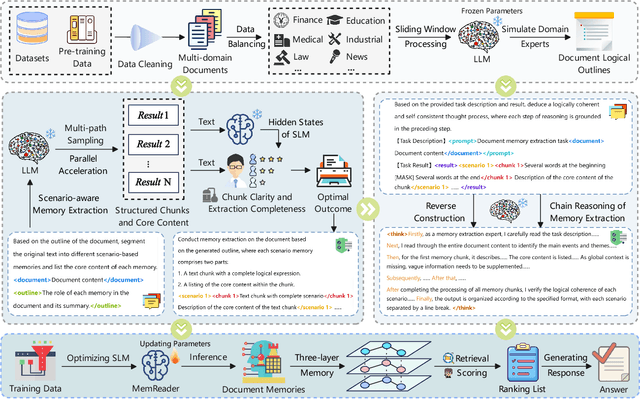
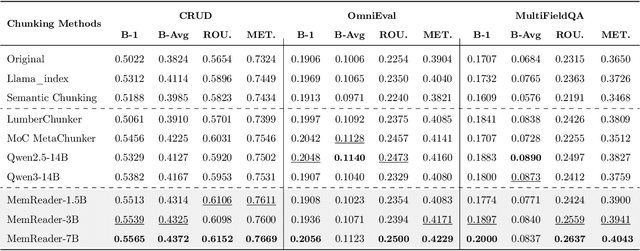
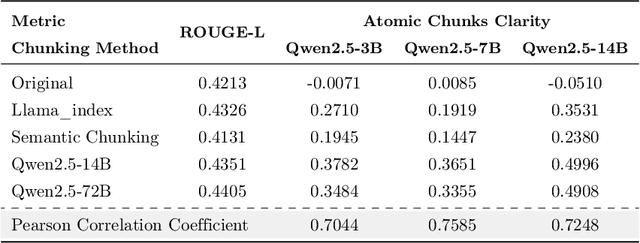
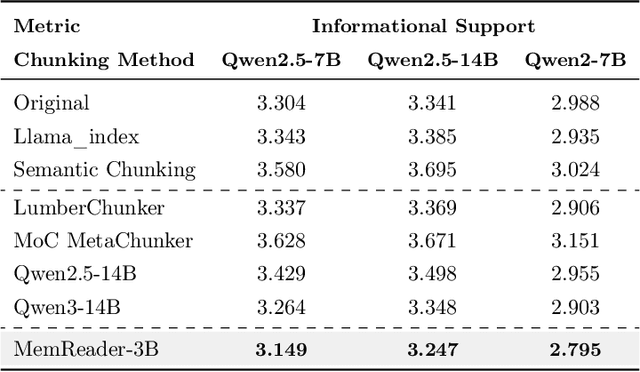
The traditional RAG paradigm, which typically engages in the comprehension of relevant text chunks in response to received queries, inherently restricts both the depth of knowledge internalization and reasoning capabilities. To address this limitation, our research transforms the text processing in RAG from passive chunking to proactive understanding, defining this process as document memory extraction with the objective of simulating human cognitive processes during reading. Building upon this, we propose the Mixtures of scenario-aware document Memories (MoM) framework, engineered to efficiently handle documents from multiple domains and train small language models (SLMs) to acquire the ability to proactively explore and construct document memories. The MoM initially instructs large language models (LLMs) to simulate domain experts in generating document logical outlines, thereby directing structured chunking and core content extraction. It employs a multi-path sampling and multi-perspective evaluation mechanism, specifically designing comprehensive metrics that represent chunk clarity and extraction completeness to select the optimal document memories. Additionally, to infuse deeper human-like reading abilities during the training of SLMs, we incorporate a reverse reasoning strategy, which deduces refined expert thinking paths from high-quality outcomes. Finally, leveraging diverse forms of content generated by MoM, we develop a three-layer document memory retrieval mechanism, which is grounded in our theoretical proof from the perspective of probabilistic modeling. Extensive experimental results across three distinct domains demonstrate that the MoM framework not only resolves text chunking challenges in existing RAG systems, providing LLMs with semantically complete document memories, but also paves the way for SLMs to achieve human-centric intelligent text processing.
MemOS: An Operating System for Memory-Augmented Generation (MAG) in Large Language Models
May 28, 2025



Large Language Models (LLMs) have emerged as foundational infrastructure in the pursuit of Artificial General Intelligence (AGI). Despite their remarkable capabilities in language perception and generation, current LLMs fundamentally lack a unified and structured architecture for handling memory. They primarily rely on parametric memory (knowledge encoded in model weights) and ephemeral activation memory (context-limited runtime states). While emerging methods like Retrieval-Augmented Generation (RAG) incorporate plaintext memory, they lack lifecycle management and multi-modal integration, limiting their capacity for long-term knowledge evolution. To address this, we introduce MemOS, a memory operating system designed for LLMs that, for the first time, elevates memory to a first-class operational resource. It builds unified mechanisms for representation, organization, and governance across three core memory types: parametric, activation, and plaintext. At its core is the MemCube, a standardized memory abstraction that enables tracking, fusion, and migration of heterogeneous memory, while offering structured, traceable access across tasks and contexts. MemOS establishes a memory-centric execution framework with strong controllability, adaptability, and evolvability. It fills a critical gap in current LLM infrastructure and lays the groundwork for continual adaptation, personalized intelligence, and cross-platform coordination in next-generation intelligent systems.
Invoke Interfaces Only When Needed: Adaptive Invocation for Large Language Models in Question Answering
May 05, 2025The collaborative paradigm of large and small language models (LMs) effectively balances performance and cost, yet its pivotal challenge lies in precisely pinpointing the moment of invocation when hallucinations arise in small LMs. Previous optimization efforts primarily focused on post-processing techniques, which were separate from the reasoning process of LMs, resulting in high computational costs and limited effectiveness. In this paper, we propose a practical invocation evaluation metric called AttenHScore, which calculates the accumulation and propagation of hallucinations during the generation process of small LMs, continuously amplifying potential reasoning errors. By dynamically adjusting the detection threshold, we achieve more accurate real-time invocation of large LMs. Additionally, considering the limited reasoning capacity of small LMs, we leverage uncertainty-aware knowledge reorganization to assist them better capture critical information from different text chunks. Extensive experiments reveal that our AttenHScore outperforms most baseline in enhancing real-time hallucination detection capabilities across multiple QA datasets, especially when addressing complex queries. Moreover, our strategies eliminate the need for additional model training and display flexibility in adapting to various transformer-based LMs.
MoC: Mixtures of Text Chunking Learners for Retrieval-Augmented Generation System
Mar 12, 2025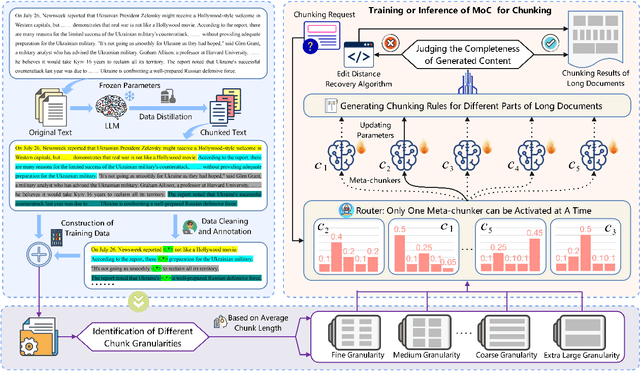
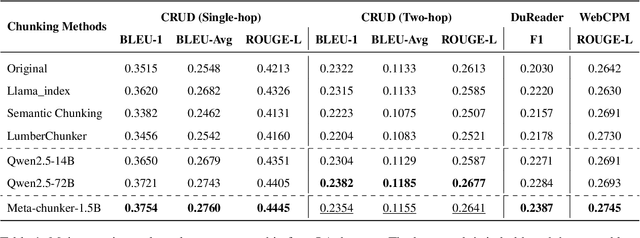
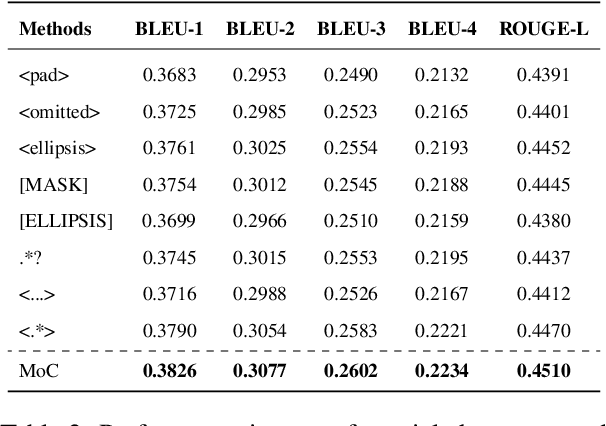

Retrieval-Augmented Generation (RAG), while serving as a viable complement to large language models (LLMs), often overlooks the crucial aspect of text chunking within its pipeline. This paper initially introduces a dual-metric evaluation method, comprising Boundary Clarity and Chunk Stickiness, to enable the direct quantification of chunking quality. Leveraging this assessment method, we highlight the inherent limitations of traditional and semantic chunking in handling complex contextual nuances, thereby substantiating the necessity of integrating LLMs into chunking process. To address the inherent trade-off between computational efficiency and chunking precision in LLM-based approaches, we devise the granularity-aware Mixture-of-Chunkers (MoC) framework, which consists of a three-stage processing mechanism. Notably, our objective is to guide the chunker towards generating a structured list of chunking regular expressions, which are subsequently employed to extract chunks from the original text. Extensive experiments demonstrate that both our proposed metrics and the MoC framework effectively settle challenges of the chunking task, revealing the chunking kernel while enhancing the performance of the RAG system.