 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Mechanistic Interpretability and Prompt Engineering with Gradient Ascent for Interpretable Persona Control
Jan 06, 2026Controlling emergent behavioral personas (e.g., sycophancy, hallucination) in Large Language Models (LLMs) is critical for AI safety, yet remains a persistent challenge. Existing solutions face a dilemma: manual prompt engineering is intuitive but unscalable and imprecise, while automatic optimization methods are effective but operate as "black boxes" with no interpretable connection to model internals. We propose a novel framework that adapts gradient ascent to LLMs, enabling targeted prompt discovery. In specific, we propose two methods, RESGA and SAEGA, that both optimize randomly initialized prompts to achieve better aligned representation with an identified persona direction. We introduce fluent gradient ascent to control the fluency of discovered persona steering prompts. We demonstrate RESGA and SAEGA's effectiveness across Llama 3.1, Qwen 2.5, and Gemma 3 for steering three different personas,sycophancy, hallucination, and myopic reward. Crucially, on sycophancy, our automatically discovered prompts achieve significant improvement (49.90% compared with 79.24%). By grounding prompt discovery in mechanistically meaningful features, our method offers a new paradigm for controllable and interpretable behavior modification.
How does My Model Fail? Automatic Identification and Interpretation of Physical Plausibility Failure Modes with Matryoshka Transcoders
Nov 18, 2025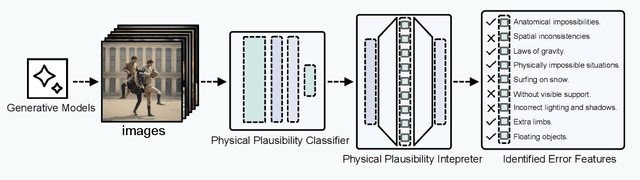
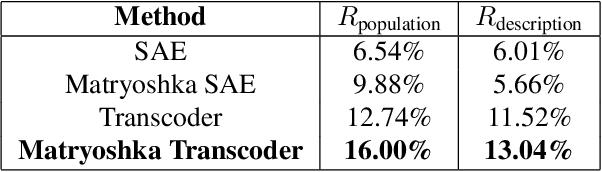
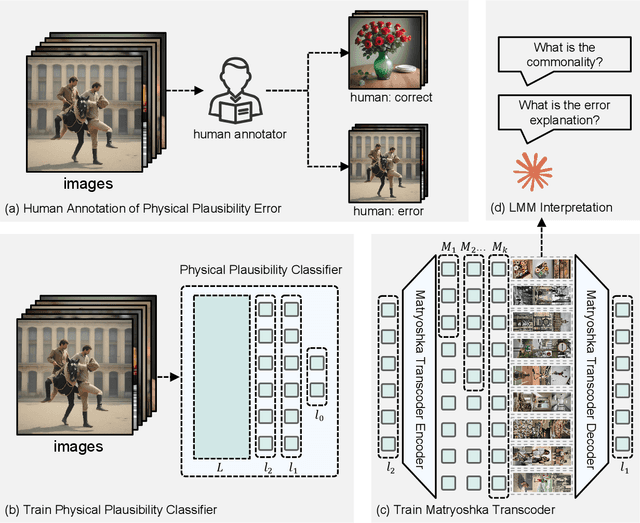
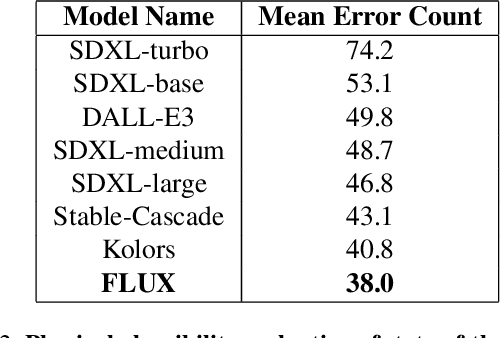
Although recent generative models are remarkably capable of producing instruction-following and realistic outputs, they remain prone to notable physical plausibility failures. Though critical in applications, these physical plausibility errors often escape detection by existing evaluation methods. Furthermore, no framework exists for automatically identifying and interpreting specific physical error patterns in natural language, preventing targeted model improvements. We introduce Matryoshka Transcoders, a novel framework for the automatic discovery and interpretation of physical plausibility features in generative models. Our approach extends the Matryoshka representation learning paradigm to transcoder architectures, enabling hierarchical sparse feature learning at multiple granularity levels. By training on intermediate representations from a physical plausibility classifier and leveraging large multimodal models for interpretation, our method identifies diverse physics-related failure modes without manual feature engineering, achieving superior feature relevance and feature accuracy compared to existing approaches. We utilize the discovered visual patterns to establish a benchmark for evaluating physical plausibility in generative models. Our analysis of eight state-of-the-art generative models provides valuable insights into how these models fail to follow physical constraints, paving the way for further model improvements.
FreDN: Spectral Disentanglement for Time Series Forecasting via Learnable Frequency Decomposition
Nov 14, 2025Time series forecasting is essential in a wide range of real world applications. Recently, frequency-domain methods have attracted increasing interest for their ability to capture global dependencies. However, when applied to non-stationary time series, these methods encounter the $\textit{spectral entanglement}$ and the computational burden of complex-valued learning. The $\textit{spectral entanglement}$ refers to the overlap of trends, periodicities, and noise across the spectrum due to $\textit{spectral leakage}$ and the presence of non-stationarity. However, existing decompositions are not suited to resolving spectral entanglement. To address this, we propose the Frequency Decomposition Network (FreDN), which introduces a learnable Frequency Disentangler module to separate trend and periodic components directly in the frequency domain. Furthermore, we propose a theoretically supported ReIm Block to reduce the complexity of complex-valued operations while maintaining performance. We also re-examine the frequency-domain loss function and provide new theoretical insights into its effectiveness. Extensive experiments on seven long-term forecasting benchmarks demonstrate that FreDN outperforms state-of-the-art methods by up to 10\%. Furthermore, compared with standard complex-valued architectures, our real-imaginary shared-parameter design reduces the parameter count and computational cost by at least 50\%.
CXR-LanIC: Language-Grounded Interpretable Classifier for Chest X-Ray Diagnosis
Oct 24, 2025Deep learning models have achieved remarkable accuracy in chest X-ray diagnosis, yet their widespread clinical adoption remains limited by the black-box nature of their predictions. Clinicians require transparent, verifiable explanations to trust automated diagnoses and identify potential failure modes. We introduce CXR-LanIC (Language-Grounded Interpretable Classifier for Chest X-rays), a novel framework that addresses this interpretability challenge through task-aligned pattern discovery. Our approach trains transcoder-based sparse autoencoders on a BiomedCLIP diagnostic classifier to decompose medical image representations into interpretable visual patterns. By training an ensemble of 100 transcoders on multimodal embeddings from the MIMIC-CXR dataset, we discover approximately 5,000 monosemantic patterns spanning cardiac, pulmonary, pleural, structural, device, and artifact categories. Each pattern exhibits consistent activation behavior across images sharing specific radiological features, enabling transparent attribution where predictions decompose into 20-50 interpretable patterns with verifiable activation galleries. CXR-LanIC achieves competitive diagnostic accuracy on five key findings while providing the foundation for natural language explanations through planned large multimodal model annotation. Our key innovation lies in extracting interpretable features from a classifier trained on specific diagnostic objectives rather than general-purpose embeddings, ensuring discovered patterns are directly relevant to clinical decision-making, demonstrating that medical AI systems can be both accurate and interpretable, supporting safer clinical deployment through transparent, clinically grounded explanations.
StealthRank: LLM Ranking Manipulation via Stealthy Prompt Optimization
Apr 08, 2025



The integration of large language models (LLMs) into information retrieval systems introduces new attack surfaces, particularly for adversarial ranking manipulations. We present StealthRank, a novel adversarial ranking attack that manipulates LLM-driven product recommendation systems while maintaining textual fluency and stealth. Unlike existing methods that often introduce detectable anomalies, StealthRank employs an energy-based optimization framework combined with Langevin dynamics to generate StealthRank Prompts (SRPs)-adversarial text sequences embedded within product descriptions that subtly yet effectively influence LLM ranking mechanisms. We evaluate StealthRank across multiple LLMs, demonstrating its ability to covertly boost the ranking of target products while avoiding explicit manipulation traces that can be easily detected. Our results show that StealthRank consistently outperforms state-of-the-art adversarial ranking baselines in both effectiveness and stealth, highlighting critical vulnerabilities in LLM-driven recommendation systems.
Demonstration Notebook: Finding the Most Suited In-Context Learning Example from Interactions
Jun 16, 2024



Large language models (LLMs) benefit greatly from prompt engineering, with in-context learning standing as a pivital technique. While former approaches have provided various ways to construct the demonstrations used for in-context learning, they often ignore the inherent heterogeneity within datasets, applying the same demonstrations to all reasoning questions. We observed that the effectiveness of demonstrations varies depending on the specific question. This motivates our exploration of using prompt engineering to select appropriate demonstrations. To address the challenge of automatically creating and choosing demonstrations tailored to each question, we propose a novel prompt engineering workflow built around a novel object called the "demonstration notebook." This notebook helps identify the most suitable in-context learning example for a question by gathering and reusing information from the LLM's past interactions. Our experiments show that this approach outperforms all existing methods for automatic demonstration construction and selection (as far as we know), achieving state-of-the-art results on serveral reasoning benchmarks. The method's versatility is further demonstrated by its success in text summarization and prompt compression tasks. Additionally, we contribute a rigorous analysis method to reveal the "demonstrative regime" of a demonstration, providing valuable insights into how demonstrations relate to different question types within a dataset.
LLM as Dataset Analyst: Subpopulation Structure Discovery with Large Language Model
May 03, 2024



The distribution of subpopulations is an important property hidden within a dataset. Uncovering and analyzing the subpopulation distribution within datasets provides a comprehensive understanding of the datasets, standing as a powerful tool beneficial to various downstream tasks, including Dataset Subpopulation Organization, Subpopulation Shift, and Slice Discovery. Despite its importance, there has been no work that systematically explores the subpopulation distribution of datasets to our knowledge. To address the limitation and solve all the mentioned tasks in a unified way, we introduce a novel concept of subpopulation structures to represent, analyze, and utilize subpopulation distributions within datasets. To characterize the structures in an interpretable manner, we propose the Subpopulation Structure Discovery with Large Language Models (SSD-LLM) framework, which employs world knowledge and instruction-following capabilities of Large Language Models (LLMs) to linguistically analyze informative image captions and summarize the structures. Furthermore, we propose complete workflows to address downstream tasks, named Task-specific Tuning, showcasing the application of the discovered structure to a spectrum of subpopulation-related tasks, including dataset subpopulation organization, subpopulation shift, and slice discovery. Furthermore, we propose complete workflows to address downstream tasks, named Task-specific Tuning, showcasing the application of the discovered structure to a spectrum of subpopulation-related tasks, including dataset subpopulation organization, subpopulation shift, and slice discovery.
Prompt Engineering Through the Lens of Optimal Control
Nov 03, 2023


Prompt Engineering (PE) has emerged as a critical technique for guiding Large Language Models (LLMs) in solving intricate tasks. Its importance is highlighted by its potential to significantly enhance the efficiency and effectiveness of human-machine interaction. As tasks grow increasingly complex, recent advanced PE methods have extended beyond the limitations of single-round interactions to embrace multi-round interactions, which allows for a deeper and more nuanced engagement with LLMs. In this paper, we propose an optimal control framework tailored for multi-round interactions with LLMs. This framework provides a unified mathematical structure that not only systematizes the existing PE methods but also sets the stage for rigorous analytical improvements. Furthermore, we extend this framework to include PE via ensemble methods and multi-agent collaboration, thereby enlarging the scope of applicability. By adopting an optimal control perspective, we offer fresh insights into existing PE methods and highlight theoretical challenges that warrant future research. Besides, our work lays a foundation for the development of more effective and interpretable PE methods.