 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoAct: Co-Active LLM Preference Learning with Human-AI Synergy
Apr 19, 2026Learning from preference-based feedback has become an effective approach for aligning LLMs across diverse tasks. However, high-quality human-annotated preference data remains expensive and scarce. Existing methods address this challenge through either self-rewarding, which scales by using purely AI-generated labels but risks unreliability, or active learning, which ensures quality through oracle annotation but cannot fully leverage unlabeled data. In this paper, we present CoAct, a novel framework that synergistically combines self-rewarding and active learning through strategic human-AI collaboration. CoAct leverages self-consistency to identify both reliable self-labeled data and samples that require oracle verification. Additionally, oracle feedback guides the model to generate new instructions within its solvable capability. Evaluated on three reasoning benchmarks across two model families, CoAct achieves average improvements of +13.25% on GSM8K, +8.19% on MATH, and +13.16% on WebInstruct, consistently outperforming all baselines.
No Attacker Needed: Unintentional Cross-User Contamination in Shared-State LLM Agents
Apr 01, 2026LLM-based agents increasingly operate across repeated sessions, maintaining task states to ensure continuity. In many deployments, a single agent serves multiple users within a team or organization, reusing a shared knowledge layer across user identities. This shared persistence expands the failure surface: information that is locally valid for one user can silently degrade another user's outcome when the agent reapplies it without regard for scope. We refer to this failure mode as unintentional cross-user contamination (UCC). Unlike adversarial memory poisoning, UCC requires no attacker; it arises from benign interactions whose scope-bound artifacts persist and are later misapplied. We formalize UCC through a controlled evaluation protocol, introduce a taxonomy of three contamination types, and evaluate the problem in two shared-state mechanisms. Under raw shared state, benign interactions alone produce contamination rates of 57--71%. A write-time sanitization is effective when shared state is conversational, but leaves substantial residual risk when shared state includes executable artifacts, with contamination often manifesting as silent wrong answers. These results indicate that shared-state agents need artifact-level defenses beyond text-level sanitization to prevent silent cross-user failures.
DS$^2$-Instruct: Domain-Specific Data Synthesis for Large Language Models Instruction Tuning
Mar 16, 2026Adapting Large Language Models (LLMs) to specialized domains requires high-quality instruction tuning datasets, which are expensive to create through human annotation. Existing data synthesis methods focus on general-purpose tasks and fail to capture domain-specific terminology and reasoning patterns. To address this, we introduce DS$^2$-Instruct, a zero-shot framework that generates domain-specific instruction datasets without human supervision. Our approach first generates task-informed keywords to ensure comprehensive domain coverage. It then creates diverse instructions by pairing these keywords with different cognitive levels from Bloom's Taxonomy. Finally, it uses self-consistency validation to ensure data quality. We apply this framework to generate datasets across seven challenging domains, such as mathematics, finance, and logical reasoning. Comprehensive evaluation demonstrates that models fine-tuned on our generated data achieve substantial improvements over existing data generation methods.
AD-LLM: Benchmarking Large Language Models for Anomaly Detection
Dec 15, 2024



Anomaly detection (AD) is an important machine learning task with many real-world uses, including fraud detection, medical diagnosis, and industrial monitoring. Within natural language processing (NLP), AD helps detect issues like spam, misinformation, and unusual user activity. Although large language models (LLMs) have had a strong impact on tasks such as text generation and summarization, their potential in AD has not been studied enough. This paper introduces AD-LLM, the first benchmark that evaluates how LLMs can help with NLP anomaly detection. We examine three key tasks: (i) zero-shot detection, using LLMs' pre-trained knowledge to perform AD without tasks-specific training; (ii) data augmentation, generating synthetic data and category descriptions to improve AD models; and (iii) model selection, using LLMs to suggest unsupervised AD models. Through experiments with different datasets, we find that LLMs can work well in zero-shot AD, that carefully designed augmentation methods are useful, and that explaining model selection for specific datasets remains challenging. Based on these results, we outline six future research directions on LLMs for AD.
Large Language Models for Anomaly and Out-of-Distribution Detection: A Survey
Sep 03, 2024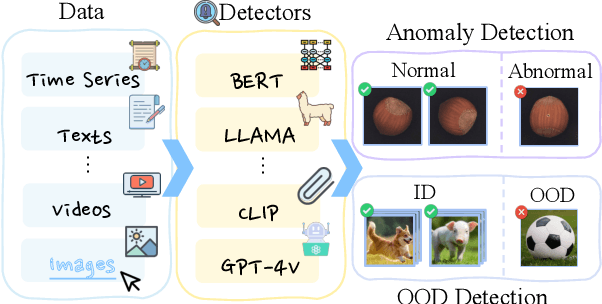
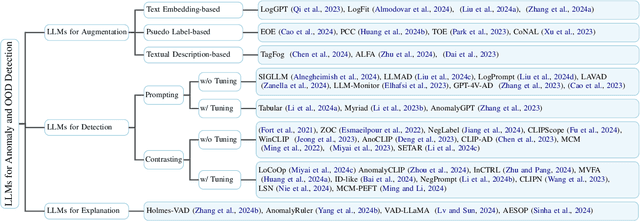
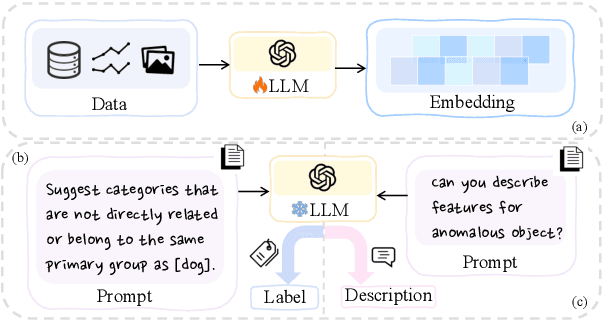
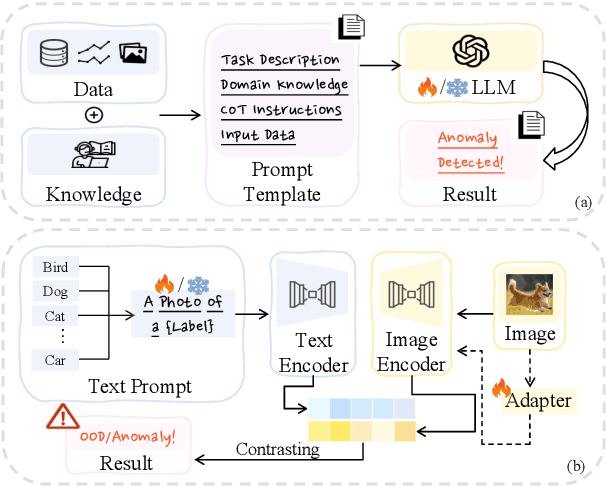
Detecting anomalies or out-of-distribution (OOD) samples is critical for maintaining the reliability and trustworthiness of machine learning systems. Recently, Large Language Models (LLMs) have demonstrated their effectiveness not only in natural language processing but also in broader applications due to their advanced comprehension and generative capabilities. The integration of LLMs into anomaly and OOD detection marks a significant shift from the traditional paradigm in the field. This survey focuses on the problem of anomaly and OOD detection under the context of LLMs. We propose a new taxonomy to categorize existing approaches into three classes based on the role played by LLMs. Following our proposed taxonomy, we further discuss the related work under each of the categories and finally discuss potential challenges and directions for future research in this field. We also provide an up-to-date reading list of relevant papers.