 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting Actions and Characteristic 3D Poses
Nov 25, 2022



We propose to model longer-term future human behavior by jointly predicting action labels and 3D characteristic poses (3D poses representative of the associated actions). While previous work has considered action and 3D pose forecasting separately, we observe that the nature of the two tasks is coupled, and thus we predict them together. Starting from an input 2D video observation, we jointly predict a future sequence of actions along with 3D poses characterizing these actions. Since coupled action labels and 3D pose annotations are difficult and expensive to acquire for videos of complex action sequences, we train our approach with action labels and 2D pose supervision from two existing action video datasets, in tandem with an adversarial loss that encourages likely 3D predicted poses. Our experiments demonstrate the complementary nature of joint action and characteristic 3D pose prediction: our joint approach outperforms each task treated individually, enables robust longer-term sequence prediction, and outperforms alternative approaches to forecast actions and characteristic 3D poses.
MobileNeRF: Exploiting the Polygon Rasterization Pipeline for Efficient Neural Field Rendering on Mobile Architectures
Aug 06, 2022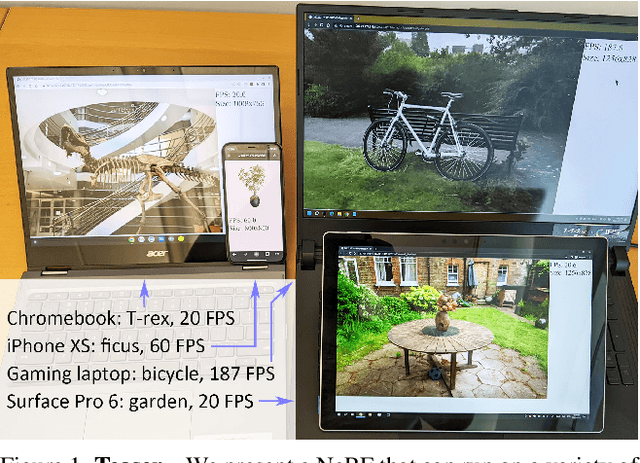

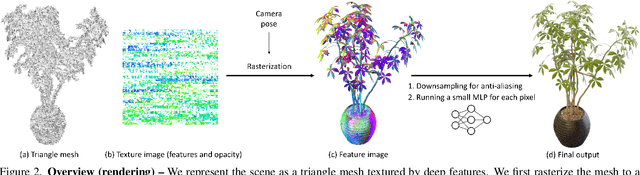
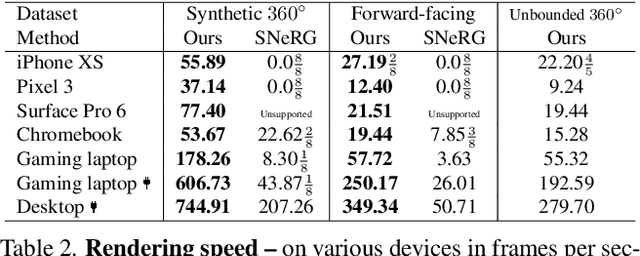
Neural Radiance Fields (NeRFs) have demonstrated amazing ability to synthesize images of 3D scenes from novel views. However, they rely upon specialized volumetric rendering algorithms based on ray marching that are mismatched to the capabilities of widely deployed graphics hardware. This paper introduces a new NeRF representation based on textured polygons that can synthesize novel images efficiently with standard rendering pipelines. The NeRF is represented as a set of polygons with textures representing binary opacities and feature vectors. Traditional rendering of the polygons with a z-buffer yields an image with features at every pixel, which are interpreted by a small, view-dependent MLP running in a fragment shader to produce a final pixel color. This approach enables NeRFs to be rendered with the traditional polygon rasterization pipeline, which provides massive pixel-level parallelism, achieving interactive frame rates on a wide range of compute platforms, including mobile phones.
Panoptic Neural Fields: A Semantic Object-Aware Neural Scene Representation
May 09, 2022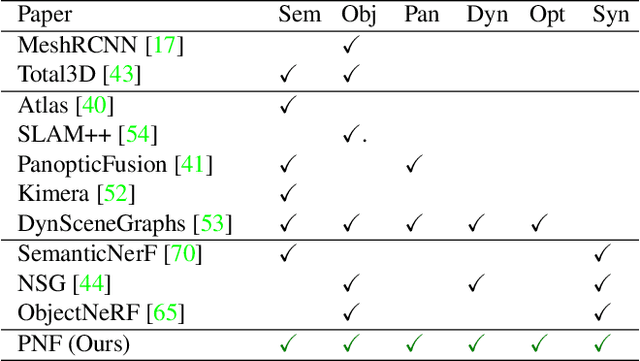
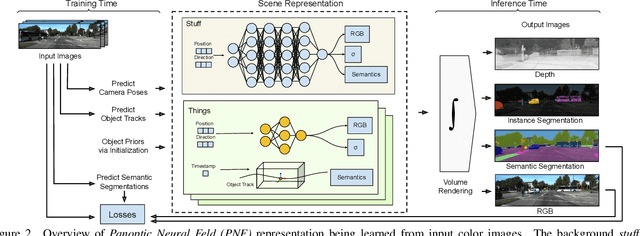
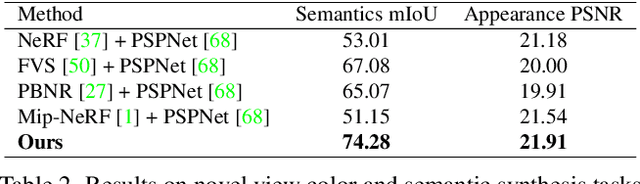
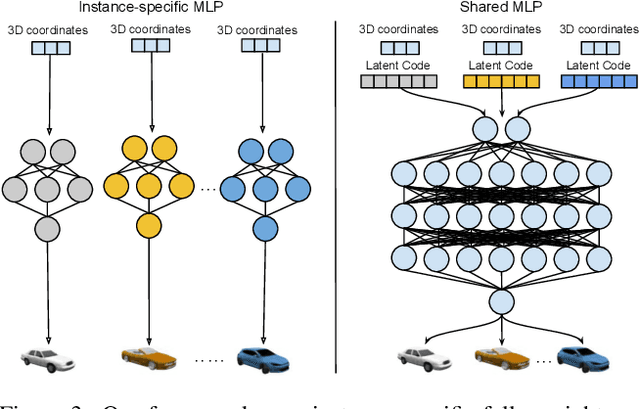
We present Panoptic Neural Fields (PNF), an object-aware neural scene representation that decomposes a scene into a set of objects (things) and background (stuff). Each object is represented by an oriented 3D bounding box and a multi-layer perceptron (MLP) that takes position, direction, and time and outputs density and radiance. The background stuff is represented by a similar MLP that additionally outputs semantic labels. Each object MLPs are instance-specific and thus can be smaller and faster than previous object-aware approaches, while still leveraging category-specific priors incorporated via meta-learned initialization. Our model builds a panoptic radiance field representation of any scene from just color images. We use off-the-shelf algorithms to predict camera poses, object tracks, and 2D image semantic segmentations. Then we jointly optimize the MLP weights and bounding box parameters using analysis-by-synthesis with self-supervision from color images and pseudo-supervision from predicted semantic segmentations. During experiments with real-world dynamic scenes, we find that our model can be used effectively for several tasks like novel view synthesis, 2D panoptic segmentation, 3D scene editing, and multiview depth prediction.
Learning Pneumatic Non-Prehensile Manipulation with a Mobile Blower
Apr 05, 2022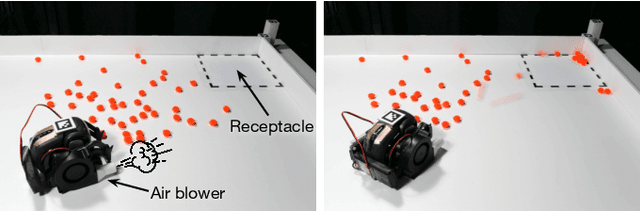
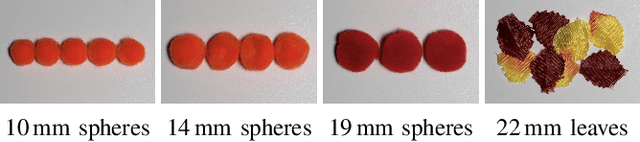

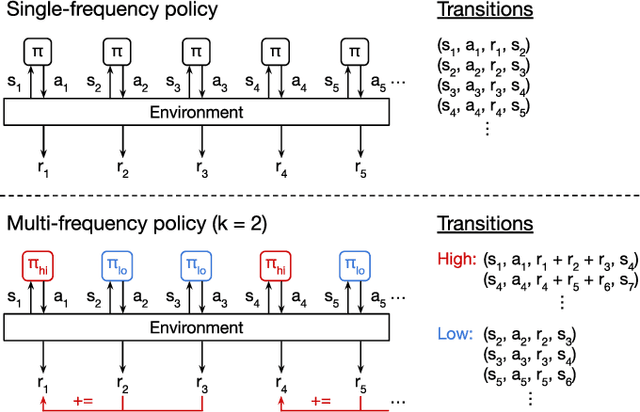
We investigate pneumatic non-prehensile manipulation (i.e., blowing) as a means of efficiently moving scattered objects into a target receptacle. Due to the chaotic nature of aerodynamic forces, a blowing controller must (i) continually adapt to unexpected changes from its actions, (ii) maintain fine-grained control, since the slightest misstep can result in large unintended consequences (e.g., scatter objects already in a pile), and (iii) infer long-range plans (e.g., move the robot to strategic blowing locations). We tackle these challenges in the context of deep reinforcement learning, introducing a multi-frequency version of the spatial action maps framework. This allows for efficient learning of vision-based policies that effectively combine high-level planning and low-level closed-loop control for dynamic mobile manipulation. Experiments show that our system learns efficient behaviors for the task, demonstrating in particular that blowing achieves better downstream performance than pushing, and that our policies improve performance over baselines. Moreover, we show that our system naturally encourages emergent specialization between the different subpolicies spanning low-level fine-grained control and high-level planning. On a real mobile robot equipped with a miniature air blower, we show that our simulation-trained policies transfer well to a real environment and can generalize to novel objects.
Neural Dual Contouring
Feb 04, 2022
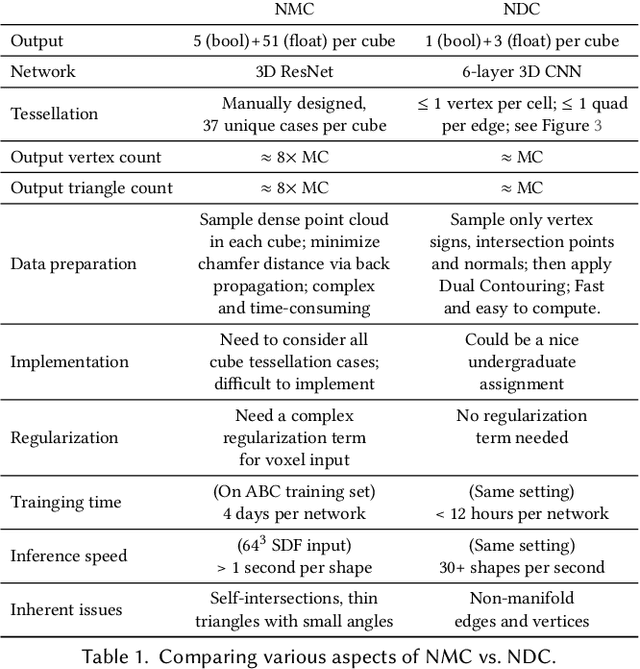
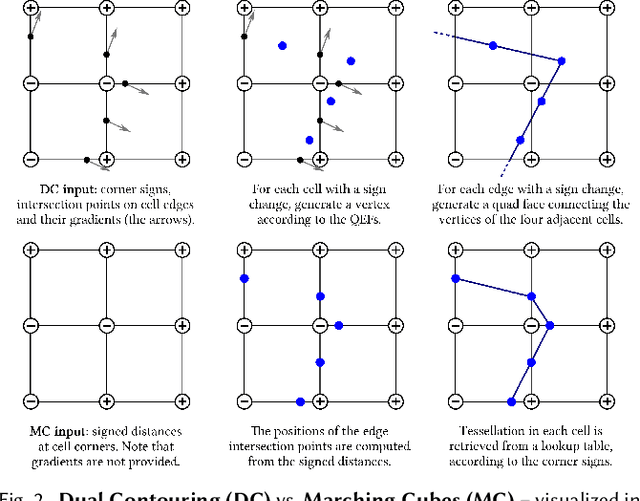
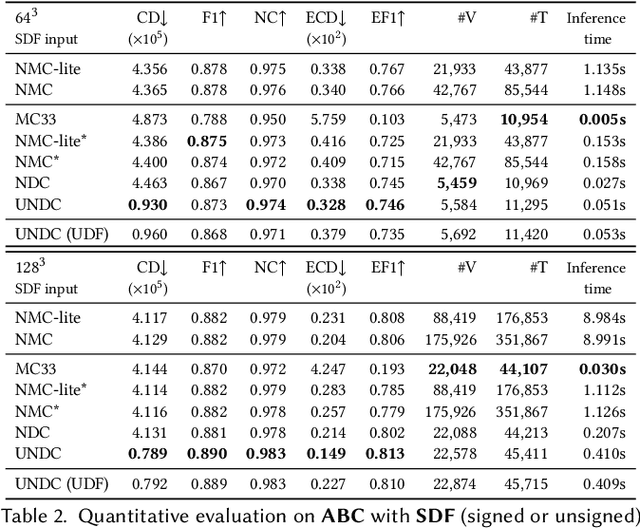
We introduce neural dual contouring (NDC), a new data-driven approach to mesh reconstruction based on dual contouring (DC). Like traditional DC, it produces exactly one vertex per grid cell and one quad for each grid edge intersection, a natural and efficient structure for reproducing sharp features. However, rather than computing vertex locations and edge crossings with hand-crafted functions that depend directly on difficult-to-obtain surface gradients, NDC uses a neural network to predict them. As a result, NDC can be trained to produce meshes from signed or unsigned distance fields, binary voxel grids, or point clouds (with or without normals); and it can produce open surfaces in cases where the input represents a sheet or partial surface. During experiments with five prominent datasets, we find that NDC, when trained on one of the datasets, generalizes well to the others. Furthermore, NDC provides better surface reconstruction accuracy, feature preservation, output complexity, triangle quality, and inference time in comparison to previous learned (e.g., neural marching cubes, convolutional occupancy networks) and traditional (e.g., Poisson) methods.
Revisiting 3D Object Detection From an Egocentric Perspective
Dec 14, 2021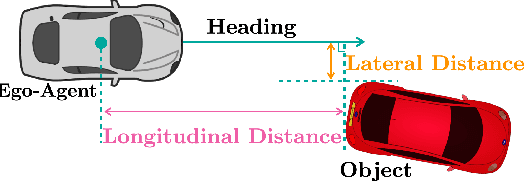
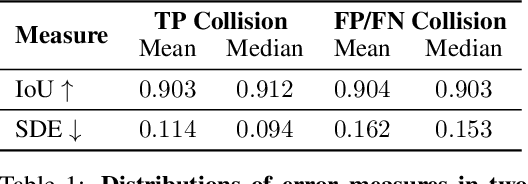
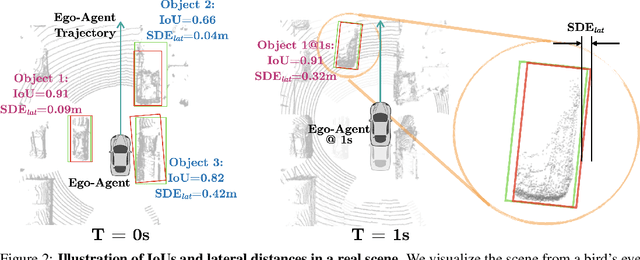
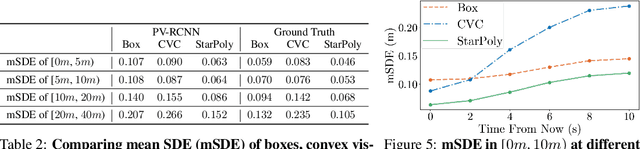
3D object detection is a key module for safety-critical robotics applications such as autonomous driving. For these applications, we care most about how the detections affect the ego-agent's behavior and safety (the egocentric perspective). Intuitively, we seek more accurate descriptions of object geometry when it's more likely to interfere with the ego-agent's motion trajectory. However, current detection metrics, based on box Intersection-over-Union (IoU), are object-centric and aren't designed to capture the spatio-temporal relationship between objects and the ego-agent. To address this issue, we propose a new egocentric measure to evaluate 3D object detection, namely Support Distance Error (SDE). Our analysis based on SDE reveals that the egocentric detection quality is bounded by the coarse geometry of the bounding boxes. Given the insight that SDE would benefit from more accurate geometry descriptions, we propose to represent objects as amodal contours, specifically amodal star-shaped polygons, and devise a simple model, StarPoly, to predict such contours. Our experiments on the large-scale Waymo Open Dataset show that SDE better reflects the impact of detection quality on the ego-agent's safety compared to IoU; and the estimated contours from StarPoly consistently improve the egocentric detection quality over recent 3D object detectors.
Urban Radiance Fields
Nov 29, 2021
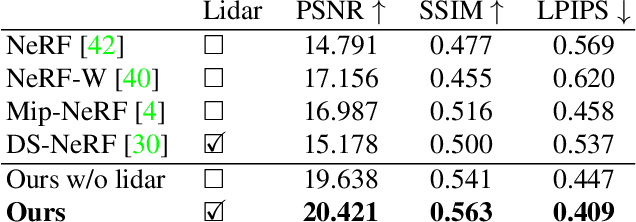


The goal of this work is to perform 3D reconstruction and novel view synthesis from data captured by scanning platforms commonly deployed for world mapping in urban outdoor environments (e.g., Street View). Given a sequence of posed RGB images and lidar sweeps acquired by cameras and scanners moving through an outdoor scene, we produce a model from which 3D surfaces can be extracted and novel RGB images can be synthesized. Our approach extends Neural Radiance Fields, which has been demonstrated to synthesize realistic novel images for small scenes in controlled settings, with new methods for leveraging asynchronously captured lidar data, for addressing exposure variation between captured images, and for leveraging predicted image segmentations to supervise densities on rays pointing at the sky. Each of these three extensions provides significant performance improvements in experiments on Street View data. Our system produces state-of-the-art 3D surface reconstructions and synthesizes higher quality novel views in comparison to both traditional methods (e.g.~COLMAP) and recent neural representations (e.g.~Mip-NeRF).
Scene Representation Transformer: Geometry-Free Novel View Synthesis Through Set-Latent Scene Representations
Nov 29, 2021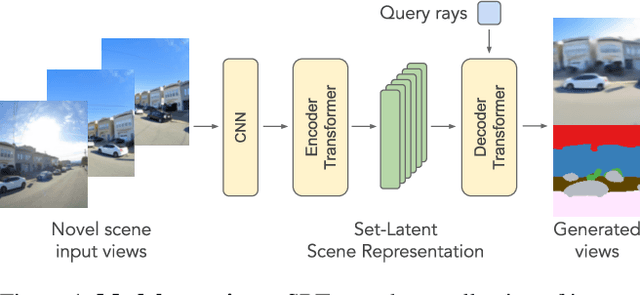

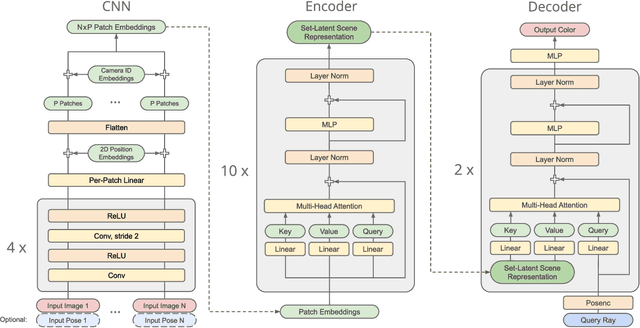
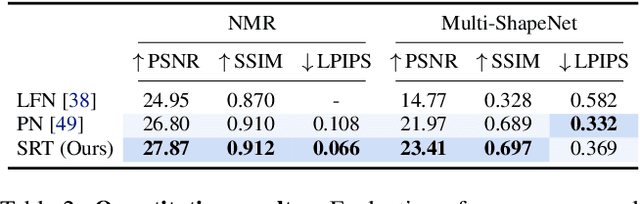
A classical problem in computer vision is to infer a 3D scene representation from few images that can be used to render novel views at interactive rates. Previous work focuses on reconstructing pre-defined 3D representations, e.g. textured meshes, or implicit representations, e.g. radiance fields, and often requires input images with precise camera poses and long processing times for each novel scene. In this work, we propose the Scene Representation Transformer (SRT), a method which processes posed or unposed RGB images of a new area, infers a "set-latent scene representation", and synthesises novel views, all in a single feed-forward pass. To calculate the scene representation, we propose a generalization of the Vision Transformer to sets of images, enabling global information integration, and hence 3D reasoning. An efficient decoder transformer parameterizes the light field by attending into the scene representation to render novel views. Learning is supervised end-to-end by minimizing a novel-view reconstruction error. We show that this method outperforms recent baselines in terms of PSNR and speed on synthetic datasets, including a new dataset created for the paper. Further, we demonstrate that SRT scales to support interactive visualization and semantic segmentation of real-world outdoor environments using Street View imagery.
Learning 3D Semantic Segmentation with only 2D Image Supervision
Oct 21, 2021
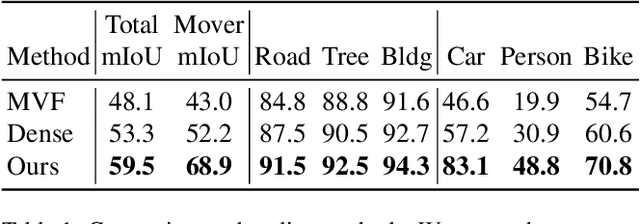
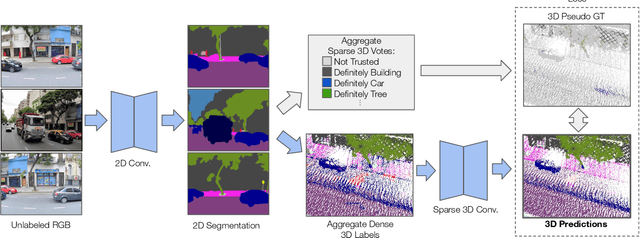
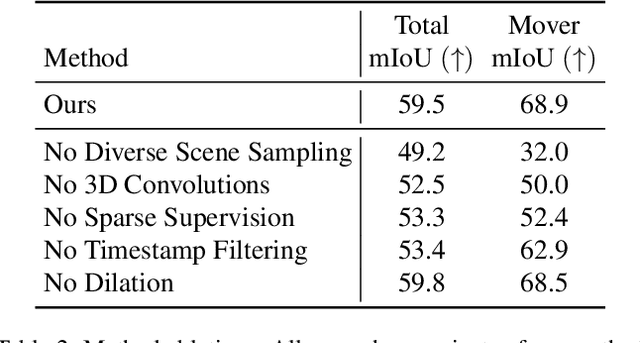
With the recent growth of urban mapping and autonomous driving efforts, there has been an explosion of raw 3D data collected from terrestrial platforms with lidar scanners and color cameras. However, due to high labeling costs, ground-truth 3D semantic segmentation annotations are limited in both quantity and geographic diversity, while also being difficult to transfer across sensors. In contrast, large image collections with ground-truth semantic segmentations are readily available for diverse sets of scenes. In this paper, we investigate how to use only those labeled 2D image collections to supervise training 3D semantic segmentation models. Our approach is to train a 3D model from pseudo-labels derived from 2D semantic image segmentations using multiview fusion. We address several novel issues with this approach, including how to select trusted pseudo-labels, how to sample 3D scenes with rare object categories, and how to decouple input features from 2D images from pseudo-labels during training. The proposed network architecture, 2D3DNet, achieves significantly better performance (+6.2-11.4 mIoU) than baselines during experiments on a new urban dataset with lidar and images captured in 20 cities across 5 continents.
Multiresolution Deep Implicit Functions for 3D Shape Representation
Sep 16, 2021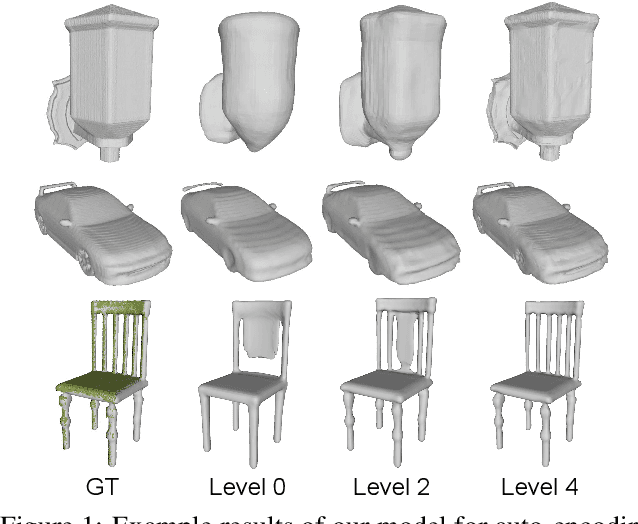
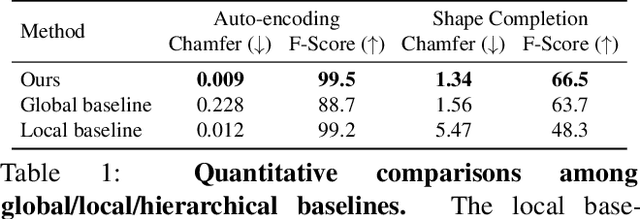
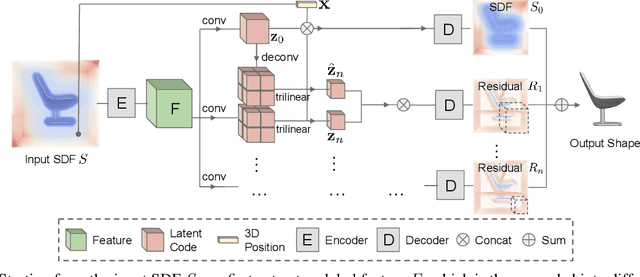
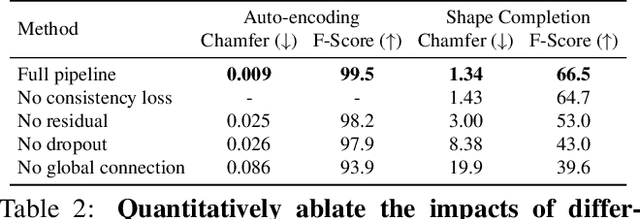
We introduce Multiresolution Deep Implicit Functions (MDIF), a hierarchical representation that can recover fine geometry detail, while being able to perform global operations such as shape completion. Our model represents a complex 3D shape with a hierarchy of latent grids, which can be decoded into different levels of detail and also achieve better accuracy. For shape completion, we propose latent grid dropout to simulate partial data in the latent space and therefore defer the completing functionality to the decoder side. This along with our multires design significantly improves the shape completion quality under decoder-only latent optimization. To the best of our knowledge, MDIF is the first deep implicit function model that can at the same time (1) represent different levels of detail and allow progressive decoding; (2) support both encoder-decoder inference and decoder-only latent optimization, and fulfill multiple applications; (3) perform detailed decoder-only shape completion. Experiments demonstrate its superior performance against prior art in various 3D reconstruction tasks.